







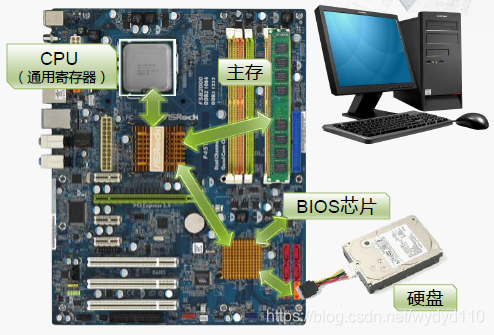
今天学修电脑。
目录
1.1 主存储器(primary memory或main memory,简称“内存”,或“主存”)
1.1.1 DRAM(Dynamic Random Access Memory)——便宜
1.1.4 ROM(Read - Only Memory)只读存储器
1.2 外存储器(peripheral storage或secondary storage,简称“外存”)
1. 存储器
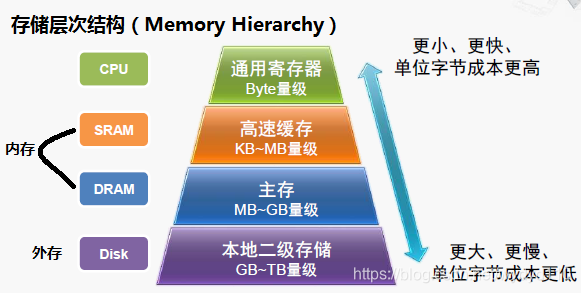
1.1 主存储器(primary memory或main memory,简称“内存”,或“主存”)
电力供应停止时,主存的数据会消失。
1.1.1 DRAM(Dynamic Random Access Memory)——便宜
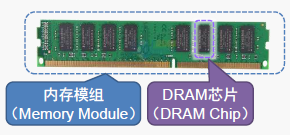
(1) DRAM芯片的内部结构
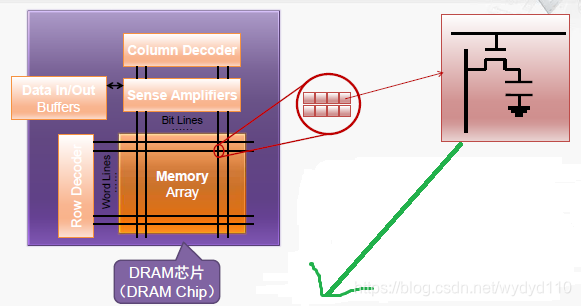
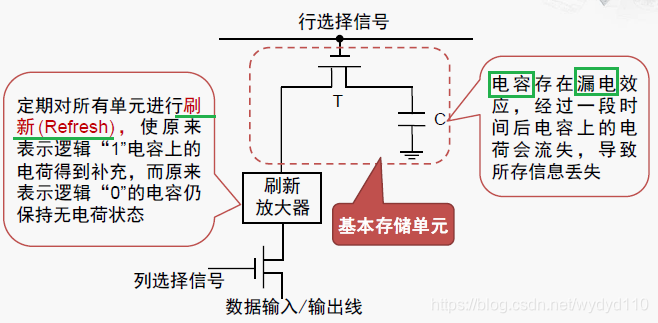
(2)DRAM的基本存储单元
存储一个bit需要2个晶体管
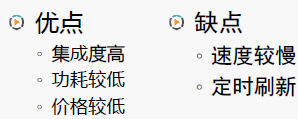
(3) DRAM的特点和主要用途
DRAM每隔一段时间,要刷新充电一次,否则内部的数据即会消失
现代PC机大多采用DRAM作为主存。如:SDRAM,DDR3 SDRAM

1.1.2 SRAM —— 贵

(1)SRAM的基本存储单位
相对于DRAM要复杂得多,存储一个bit需要6个晶体管。价格能不贵吗?
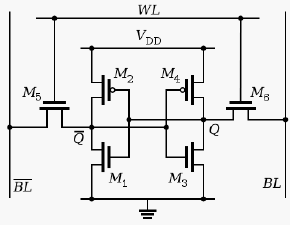
(2)SRAM的特点
现代CPU中的高速缓存通常用SRAM实现。
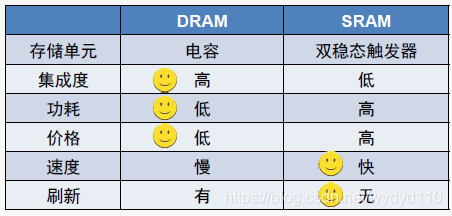
1.1.3 DRAM与SRAM的比较
1.1.4 ROM(Read - Only Memory)只读存储器

一般手机刷机的过程,就是将只读内存镜像(ROM image)写入只读内存(ROM)的过程。
BIOS基本输入输出系统,是一套不大但复杂的程序,存放在ROM中。寄存器刚通电或复位时,CPU就会从ROM的BIOS中取出第一条指令开始执行,所以BIOS中提供了系统加电自检,引导装入,主要I/O设备的处理程序及接口控制等功能模块。
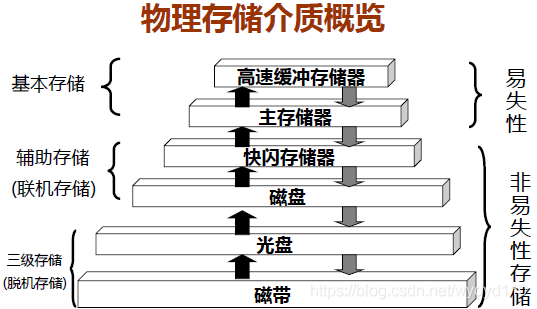
1.2 外存储器(peripheral storage或secondary storage,简称“外存”)

外储存器是指除计算机内存及CPU缓存以外的储存器,此类储存器一般断电后仍然能保存数据。
1.2.1 磁盘
(1)磁盘的物理结构
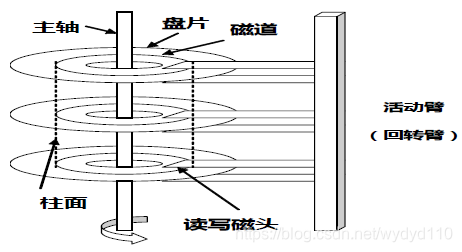
(2)磁盘盘片的组织
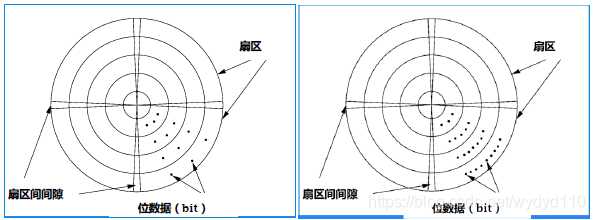
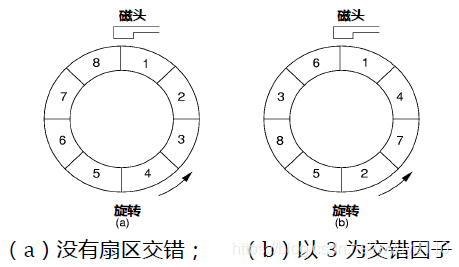
(3)磁盘磁道的组织(交错法)
每页 512 字节 或 1024 字节
1.3 总结
1.3.1 内存的优缺点

1.3.2 外存的优缺点

1.3.3 附加

2 文件
2.1 文件的逻辑结构
文件是记录的汇集
- 一个文件的各个记录按照某种次序排列起来,各记录间就自然地形成了一种线性关系。
- 文件可看成是一种线性结构
2.2 文件的组织形式
2.2.1 逻辑文件(logical file)
从用户角度去看,连续的字节构成记录,记录构成逻辑文件
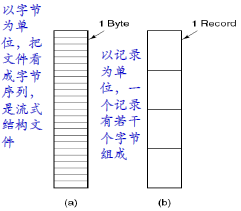
文件逻辑组织形式
- 顺序结构的定长记录
- 顺序结构的变长记录
- 按关键码存取的记录
2.2.2 物理文件(physical file)
文件中包含的字节成功存储分布在整个磁盘中
文件物理组织结构
(1)顺序结构——顺序文件
文件的信息存放在若干连续的物理块中
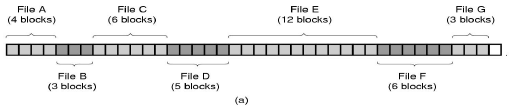
(2)计算寻址结构——散列文件
一个文件的信息存放在若干不连续的物理块中,各块之间通过指针连接,前一个物理块指向下一个物理块
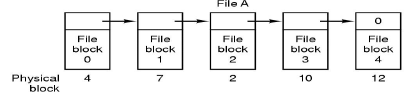
(2)带索引的结构——带索引文件
系统为每个文件建立一个专用数据结构—索引表,并将这些物理块的块号存放在该索引表中

2.2.3 文件管理器
- 操作系统或数据库系统中的一部分
文件的记录是无结构的,而数据库文件的记录是结构型的
- 文件管理器负责将文件的逻辑位置映射为磁盘中具体的物理位置
2.2.4 文件上的操作

2.3 缓冲区和缓冲池
目的:减少磁盘访问次数的
方法:缓冲 ( buffering ) 或缓存 ( caching )
- 在内存中保留尽可能多的块
- 增加待访问的块已经在内存中的机会
- 存储在一个缓冲区中的信息经常称为一页( page ),往往是一次 I/O 的量
- 缓冲区合起来称为缓冲池( buffer pool )
2.3.1 替换缓冲区块的策略
新的页块申请缓冲区时,把最近最不可能被再次引用的缓冲区释放来存放新页
- “先进先出”( FIFO )
- “最不频繁使用”( LFU )
- “最近最少使用”( LRU )
3 外排序
当我们要排序的文件太大以至于内存无法一次性装下的时候,这时候我们可以使用外部排序,将数据在外部存储器和内存之间来回交换,以达到排序的目的。
通常由两个相对独立的阶段组成
(1)文件形成尽可能长的初始顺串
(2)处理顺串,最后形成对整数据文件的排列文件
一天晚上,一尘正在呆呆地看着星星,师傅突然坐在了他的旁边

一尘啊,天上的星星那么多,不妨你给他们按大小排个序吧

哦,这个怎么排?
具体到我们的编程,就是给你2G的数据在硬盘上,但是你只有256M的内存可以使用,怎么排这2G的数据呢?
这么小的内存,装不下数据啊,怎么排呢?一脸懵逼。
还记得分而治之的思想吗?我们可以采用这种思想把它排好序。
soga。
3.1 二路外排序——二路合并
3.1.1 例子1
首先我们可以将2G的数据分成8份,分别加载到内存中进行排序,在内存中的排序方法可以用内部排序如快排、希尔等
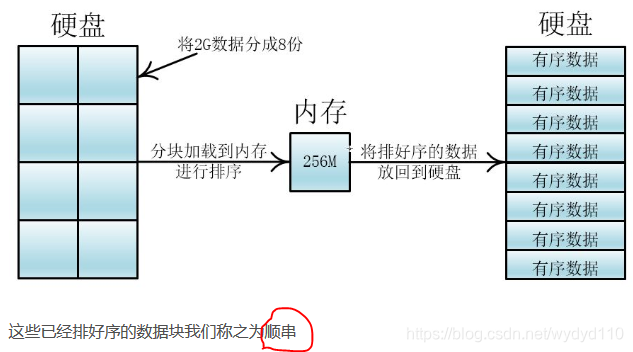
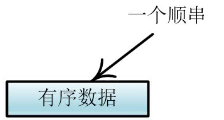
然后我们可以将两个顺串通过内存合并成一个顺串(长度为原来的两倍),经过四次合并就完成了
注意:合并操作几乎不需要内存,只需分别从磁盘中的两个顺串读入两个元素,选择一个最大的(或最小的)输出,然后再读入,再选择
按照这个方法一直来回合并,一直合并到最终的一个顺串(有序),此时排序完成
来个例子
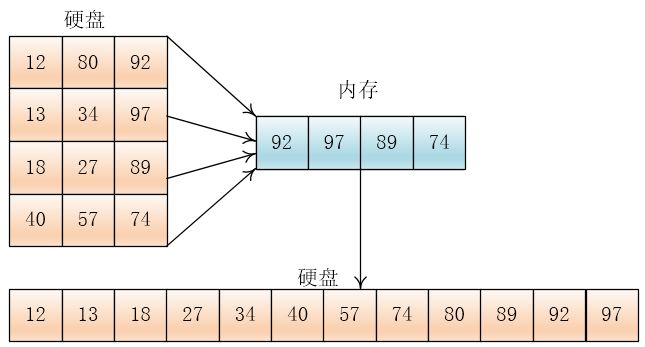
设待排数据为:80,92,12,97,13,34,18,98,27,57,40,74,内存一次可以装三个数据
将数据分为四份
然后将每份读入内存,排序后写入硬盘
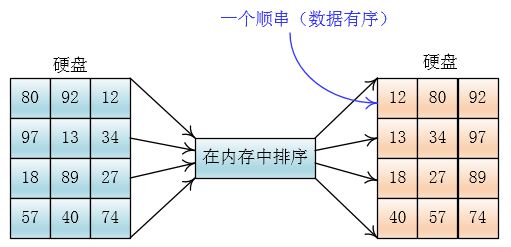
然后两两合并
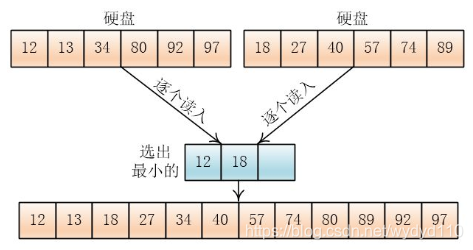
输出哪个元素,就在那个元素所在的顺串(或者叫组)再次读入元素
就这样,一直合并到两个顺串完,如果一个顺串先完,剩下另一个顺串,那么就将剩下的顺串直接拷贝到硬盘上
按照这个方法,把合并后的顺串继续合并,直到最终合并成一个总的顺串,排序结束
我听说硬盘的读写速度比内存要慢的多,按照这种排序那岂不是很慢?
为一个待排文件创建尽可能大的初始顺串,可以大大减少扫描遍数,外存读写次数和归并趟数。
3.1.2 例子2
3.2 多路归并——选择树
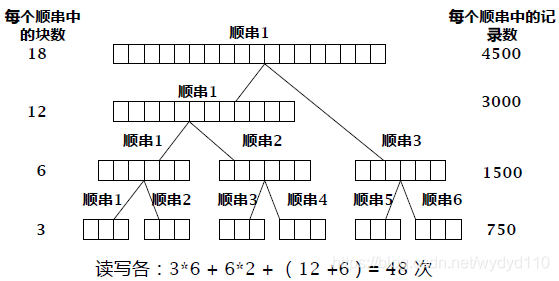
k 路归并是每次将 k 个顺串合并成一个排好序的顺串
以刚才的例子来看,这次我们假设内存大小可以容纳四个元素,我们一次对4个顺串进行归并(4路归并)
这样只需要一次合并就可以了,外存读写次数为24(12读+12写),比之前的48少了一半,于此同时我们也可以看到需要更大的内存了,内存之中选出最大值也会更耗时,所以要权衡选 k
在内存之中选最大(或最小)值时,可以选择一个元素与其他元素一个一个比,然后更新最值,但是效率会比较低,一般采取选择树来选择。
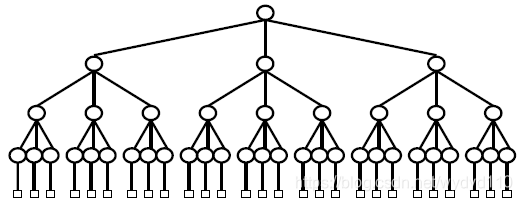
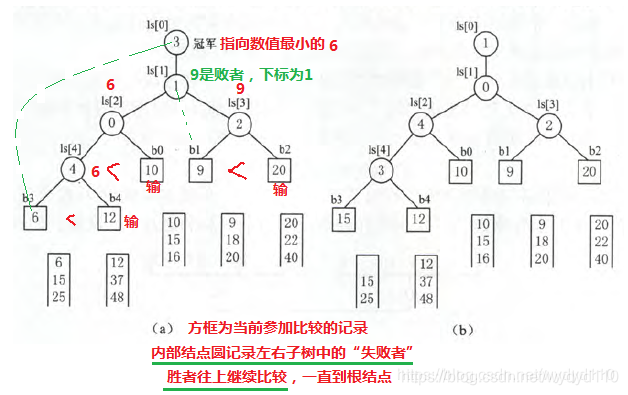
3.2.1 赢者树——完全二叉树
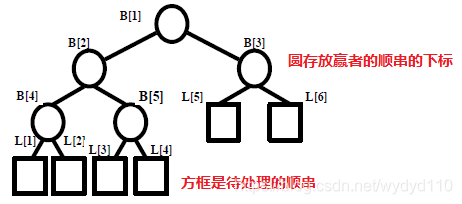
例子
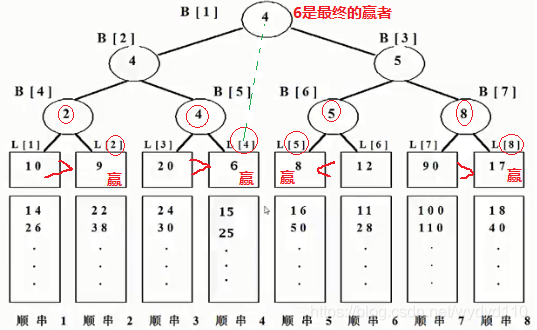
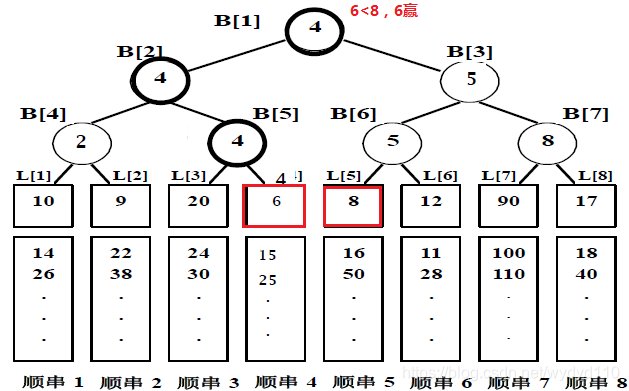
根结点所指向的L[4]记录具有最小的关键码值6,它所指的记录是顺串4的当前记录,该记录即为下一个要输出的记录。
3.2.2 败者树——完全二叉树
3.3 置换选择排序
对于顺串的构造,也就是第一次生成初顺串的时候,我们采取的办法是将划分好的每一份文件读入内存,排好序,然后输出到硬盘上形成初始顺串。
这样做的弊端就是初始顺串的个数和将文件划分好的份数是一样的
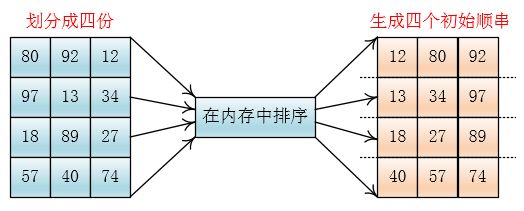
有没有一种生成更长的顺串,使得初始顺串的个数变的更少一些呢?答案是用置换选择排序
置换选择排序的大体思路就是读入一块数据到内存,将这些数据建立小根堆,然后输出最小值,再读入下一个元素
新元素 >= 刚才写出的元素,将其加入到最小堆中,重新调整堆
新元素 < =刚才写出的元素,交换堆顶与堆底元素,将其放入堆底,然后移出堆
3.3.1 例子1
我们读入三个数据在内存中,然后建立一个小根堆,然后写出最小值
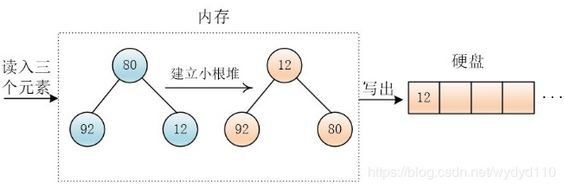
然后再读进来一个元素97,这个元素97>12,把 97 放到堆顶,调整堆,然后输出最小值80
继续读入13,此时13 < 刚才输出的元素 80 ,则交换堆底元素97 和 堆顶元素 80,然后将13放入堆底(覆盖80),并且将 13 移出堆(堆大小减一)
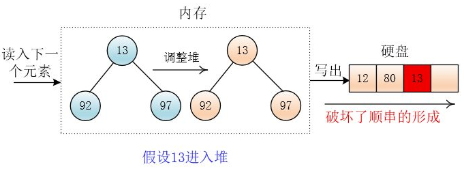
然后读入元素 34
读入元素18,仍然小于刚输出的97,此时堆顶与堆底重叠,将18放入堆底(堆顶)

此时第一个顺串就形成了,然后将之前未进入堆的三个元素重新建立成小根堆,然后按照同样的方法继续进行
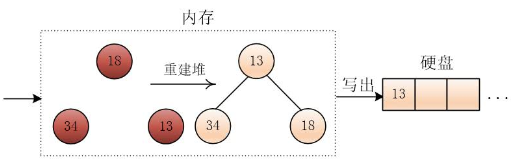
到最后,如果输入硬盘的数据读完了,只剩下一个小根堆,思路是一样的,一直选出最小值,输出
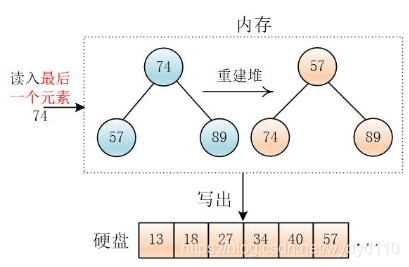
然后互换堆底与堆顶元素,再删除堆底元素,然后调整堆,输出最小值74
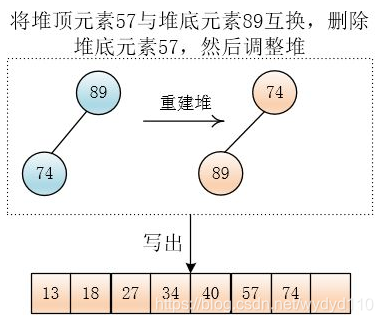
最后会生成另外一个顺串。这样只生成了两个初始顺串,比之前划分成四份生成四个初始顺串少了些,这样归并趟数也就少了
3.3.2 例子2
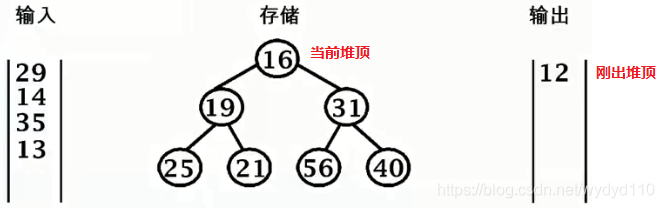
29 > 16, 输出16, 29进堆
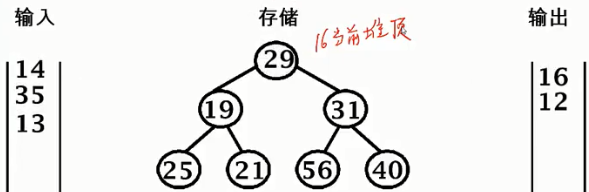
重新排列堆
14 < 19,14不能进入堆。输出19,14放入堆底,并忽略。
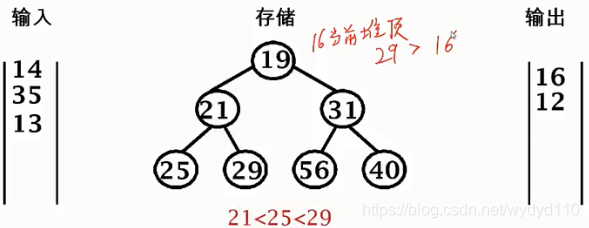
重新排列堆
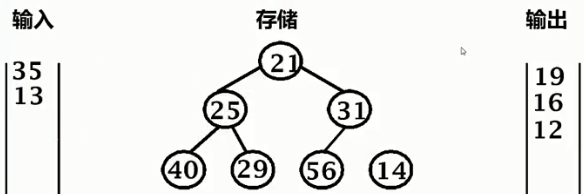
35 > 21,输出21,35进堆
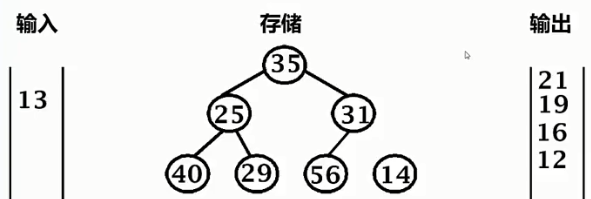
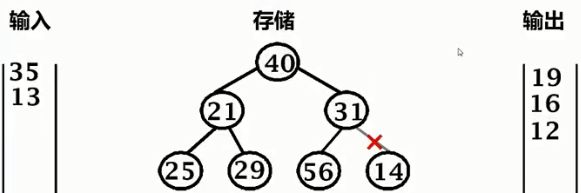
重新排列堆
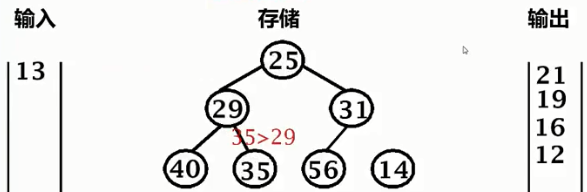
13 < 25,输出25,13压入堆底,暂时忽略
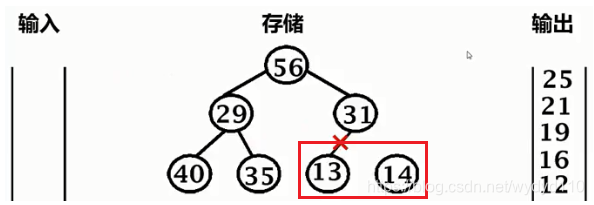
构造下一个顺串时,可以利用上13或14。堆的规模会越来越小,输出的顺串会越来越大。
3.3.3 总结
(1)置换选择排序算法得到的顺串长度并不相等。
(2)如果堆的大小是 M
- 一个顺串的最小长度就是 M 个记录
- 最好的情况下,例如输入为正序,有可能一次就把整个文件生成为一个顺串
- 平均情况下,置换选择排序算法可以形成长度为 2M 的顺串
3.4 扫雪机模型
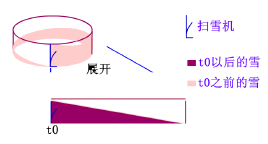
在一个下雪的日子,在一个圆形的跑道上有一个铲雪机在匀速地铲雪,下雪的速度也是匀速的,铲雪机的速度和下雪的速度刚好匹配,也就是说铲雪机从起始位置跑一圈后原来位置的雪的高度不变
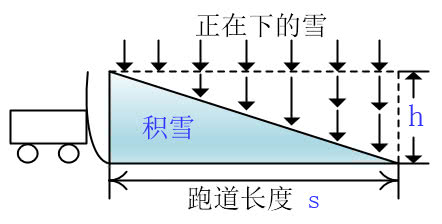
正如上图,跑了一圈后发现高度还是h,这时候就达到了一个动态平衡的状态,此时铲雪机前方的雪是一个斜坡
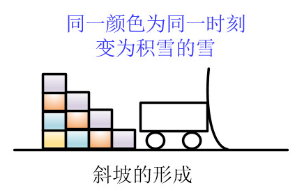
铲雪机不停地往前开,雪一直下,一部分落在了铲雪机上,一部分落在了铲雪机后面
此时铲雪机最前面的雪的高度一直都是h,因为前面有雪不断地落在斜坡上,所以铲雪机跑一圈铲的雪的总量为s*h,很显然是原来路上积雪的两倍

类比到我们的程序里,道路上的积雪就是我们内存中建的堆,需要我们输出最小值(清理),而不断下的雪就是新的输入,当输入随机的时候,大于等于刚输出值的元素被加入到堆中(落在铲车前被铲走),小于刚输出的元素被留下(落在铲车后面),产生的顺串的长度(铲的雪)就是内存中堆大小(道路上的积雪)的两倍了。
数据结构学完了吗?哪有学完的时候。
本文学习自
张铭《数据结构》
陆俊林《计算机组成原理》

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









