






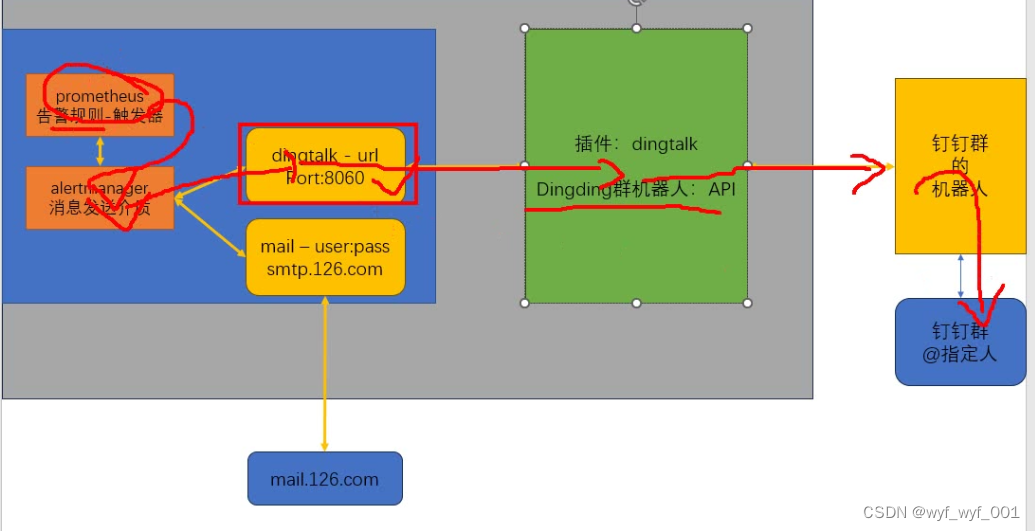
报警过程
一、实验准备
1、准备两台虚拟机
2、虚拟机连通互联网
二、实验步骤
1、Prometheus-server端
1.1下载并安装Prometheus Server服务
$ rz promethues.zip
$ unzip promethues.zip
# 单独解压缩Prometheus软件,完成安装
$ tar -xf prometheus-2.14.0.linux-amd64.tar.gz
$ cd prometheus-2.14.0.linux-amd64/
$ tree ./
# Prometheus安装非常简单,解压缩复制到自定义目录下即可,约定成俗的习惯:/usr/local/prometheus
$ cp -r prometheus-2.14.0.linux-amd64/ /usr/local/prometheus
1.2 编写Prometheus service启动脚本
$ cat>/usr/local/prometheus/prometheus.service<<EOF
[Unit]
Description=Prometheus
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/usr/local/prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
1.3 添加启动脚本到systemd启动管理中
$ ln -s /usr/local/prometheus/prometheus.service /lib/systemd/system/
$ systemctl daemon-reload
$ systemctl start prometheus
$ systemctl enable prometheus
$ netstat -antp | grep LISTEN | grep :9090
tcp6 0 0 :::9090 :::* LISTEN 37984/prometheus
1.4 使用Windows浏览器访问192.168.152.13:9090,进行测试。
1.5 配置文件讲解
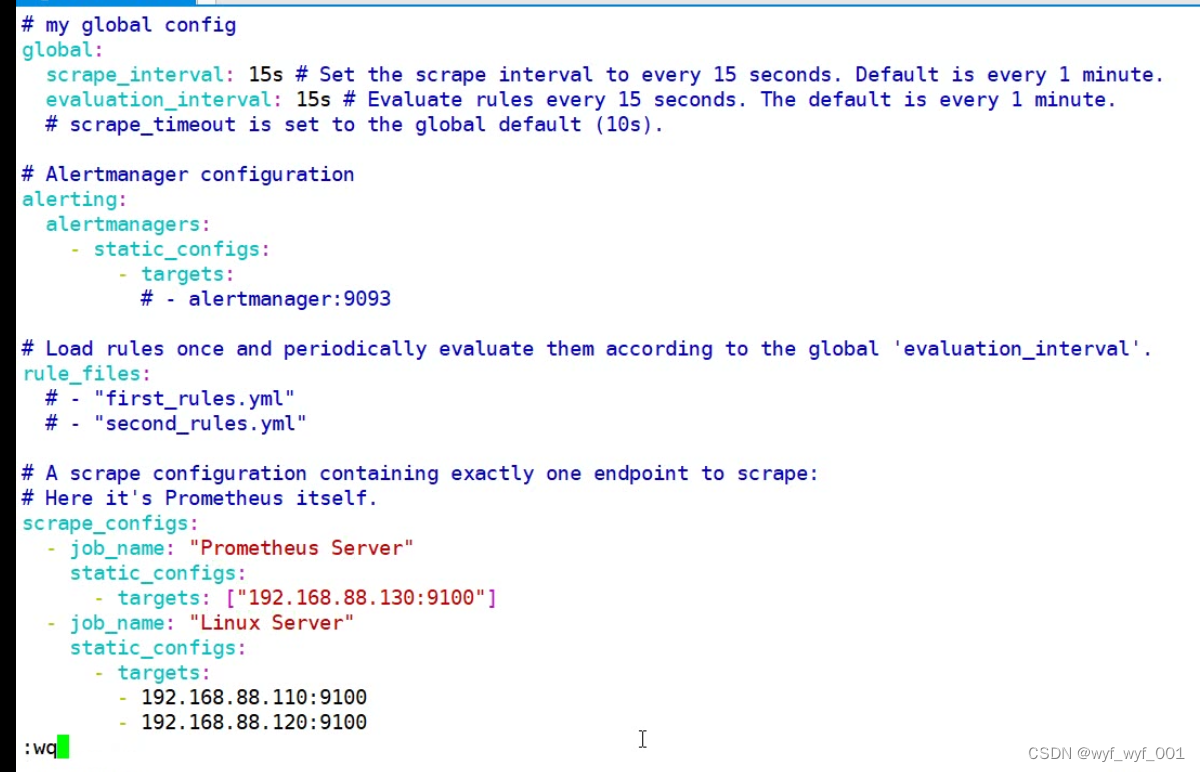
# 配置文件(原版未改)
$ vim /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# -----------------------------------------------------------------------------------------------
# 配置文件关键词介绍(由于alertmanager、exporter等都未安装,相关配置后面详细讲)
global: # 全局配置 (如果有内部单独设定,会覆盖这个参数)
scrape_interval: 15s
# 全局默认的数据拉取间隔
evaluation_interval: 15s
# 全局默认的规则(主要是报警规则)拉取间隔
scrape_timeout: 10s
# 全局默认的单次数据拉取超时间,默认不开启,当报context deadline exceeded错误时需要在特定的job下配置该字段,注意:scrape_timeout时间不能大于scrape_interval,否则Prometheus将会报错。
alerting: # 告警插件定义,这里会设定alertmanager这个报警插件。
rule_files: # 告警规则,按照设定参数进行扫描加载,用于自定义报警规则(类似触发器trigger),其报警媒介由alertmanager插件实现。
scrape_configs: # 采集配置,配置数据源,包含分组job_name以及具体target,又分为静态配置和服务发现。
1.6 浏览器查看会有两个主机名群组,点击status ---target
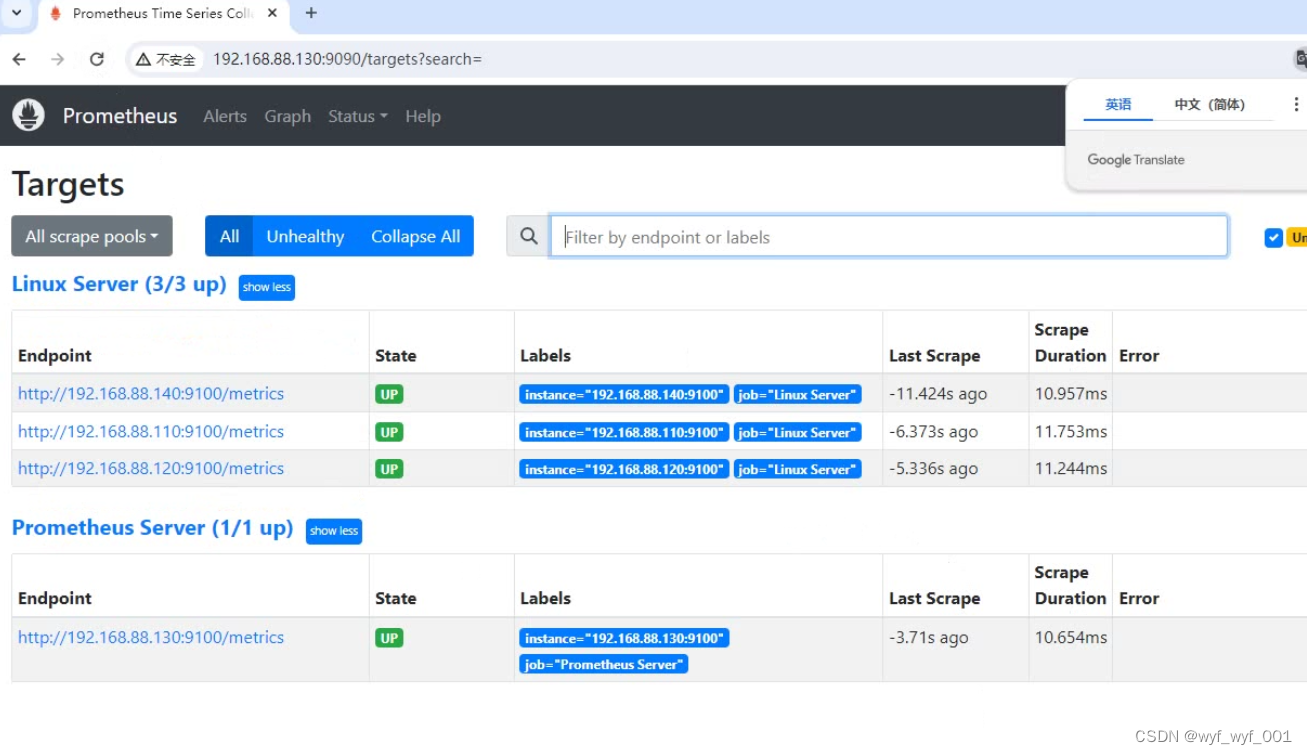
2、Prometheus - Node Exporter部署
2.1 解压缩并安装Node Exporter
$ tar -xf node_exporter-0.18.1.linux-amd64.tar.gz
$ cp -r node_exporter-0.18.1.linux-amd64 /usr/local/node_exporter
2.2 编写Node Exporter启动脚本
$ cat>/usr/local/node_exporter/node_exporter.service<<EOF
[Unit]
Description=Node Exporter
After=network.target
Wants=network-online.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
2.3 添加启动脚本到systemd启动管理中
$·
$ systemctl daemon-reload
$ systemctl start node_exporter
$ systemctl enable node_exporter
$ netstat -antp | grep LISTEN | grep :9100
tcp6 0 0 :::9100 :::* LISTEN 38150/node_exporter
#windows 浏览器访问192.168.152.14:9100,查看效果
2.5 服务器端也安装一个Prometheus - Node Exporter进行数据监控
$ scp -r node_exporter/ 192.168.152.13:/usr/loca/
2.6 修改服务器监控配置文件
$ ln -s /usr/local/node_exporter/node_exporter.service /lib/systemd/system/
$ systemctl daemon-reload
$ systemctl start node_exporter
$ systemctl enable node_exporter
$ vim /usr/local/prometheus/prometheus.yml
#添加监控项targets:["192.168.152.13:9100","192.168.152.14"]
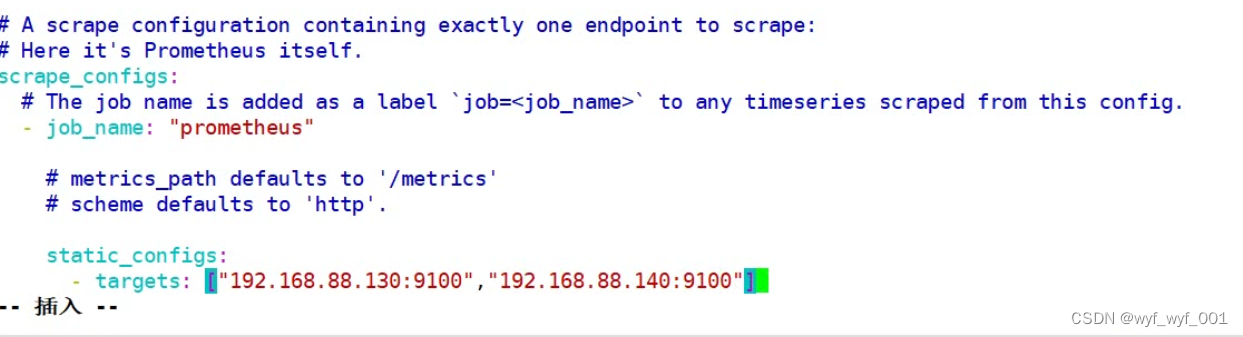
$ systemctl restart prometheus
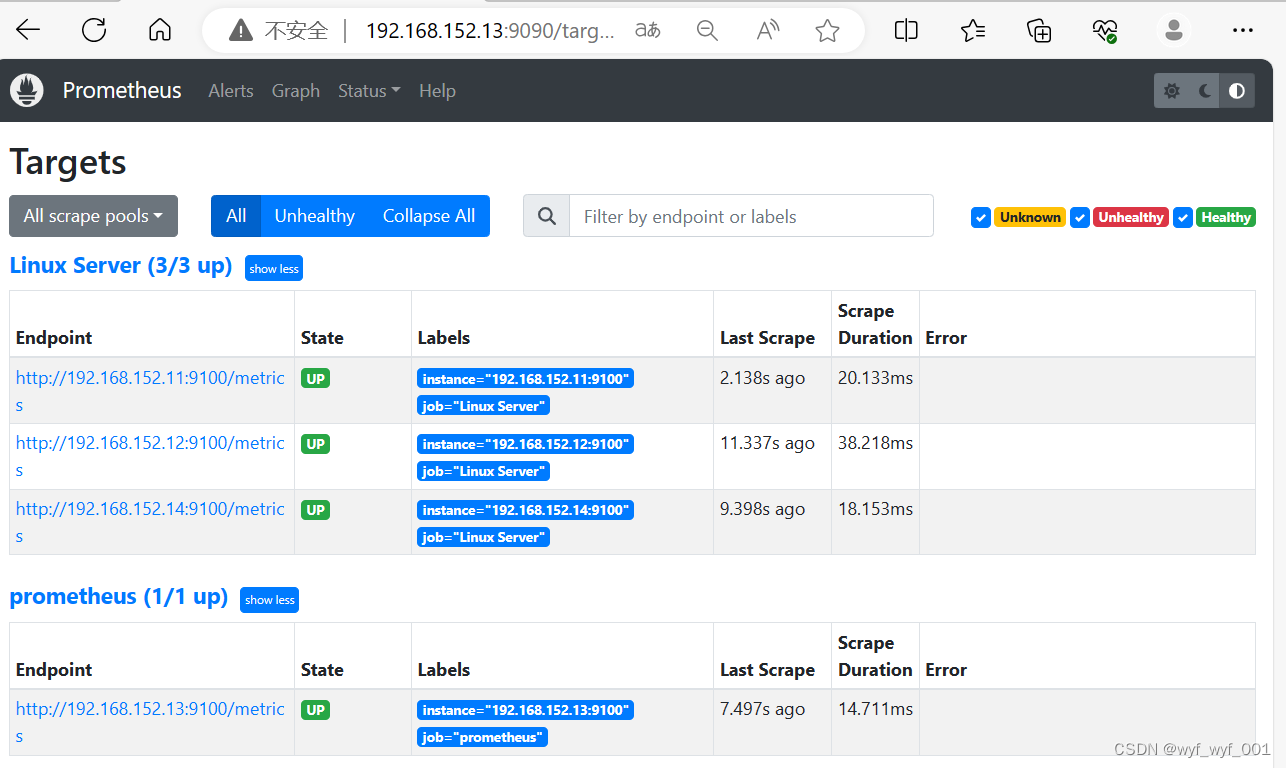
#在访问浏览器,刷新浏览器,点击Status---Targets
3、Prometheus - Grafana部署
3.1. 下载并安装Prometheus Server服务
$ tar -xf grafana-10.2.2.linux-amd64.tar.gz
$ cp -r grafana-v10.2.2 /usr/local/grafana
3.2. 编写Prometheus service启动脚本
$ cat>/usr/local/grafana/grafana-server.service<<EOF
[Unit]
Description=Grafana Server
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/usr/local/grafana
ExecStart=/usr/local/grafana/bin/grafana-server
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
3.3. 添加启动脚本到systemd启动管理中
$ ln -s /usr/local/grafana/grafana-server.service /lib/systemd/system/
$ systemctl daemon-reload
$ systemctl start grafana-server
$ systemctl enable grafana-server
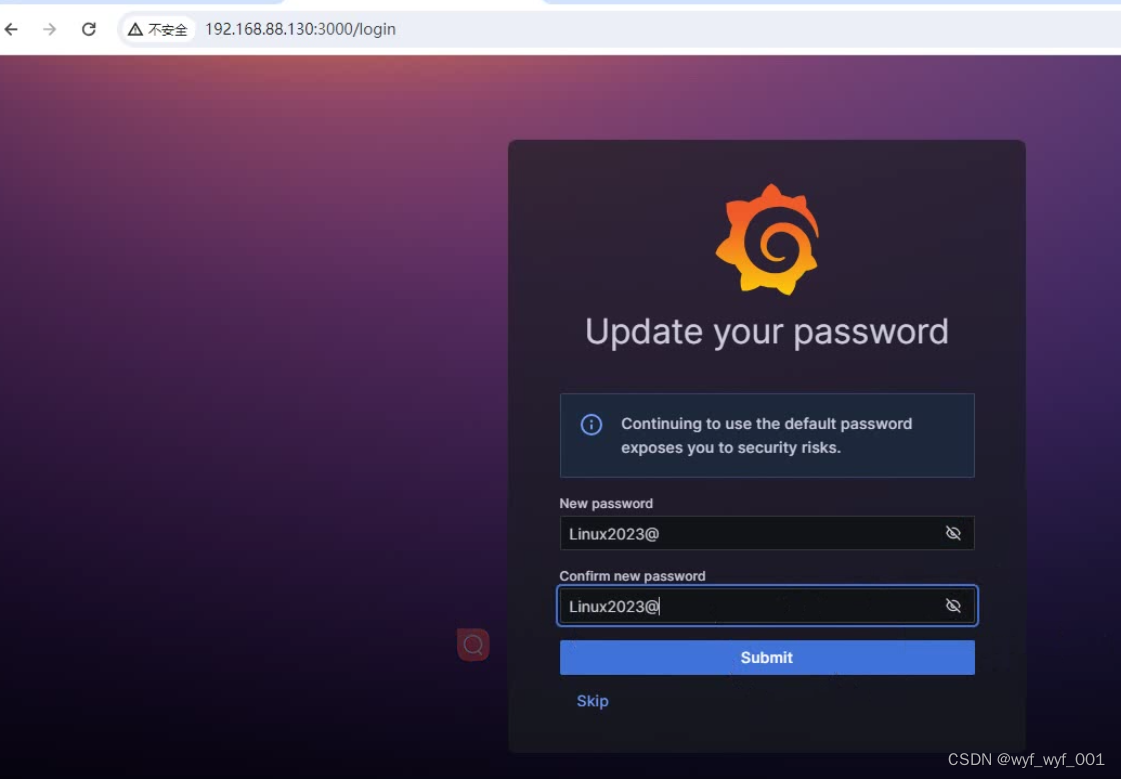
3.4. web访问:http://192.168.152.13:3000/login
登录grafana,账号:admin,密码:admin,随后填写新密码,和确认新密码,符合密码三原则。
3.5. 安装监控Linux系统资源模板
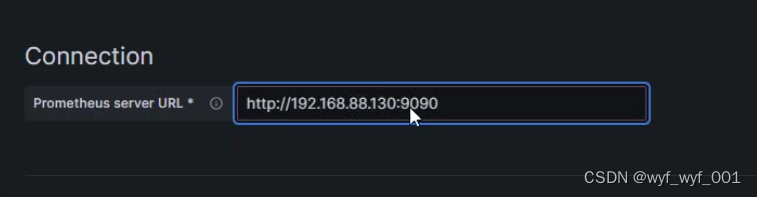
#点击DATA SOURCES----Prometheus----Name(填写名称Prometheus)-----Prometheus server ULR(http://192.168.152.13:9090)---save & test
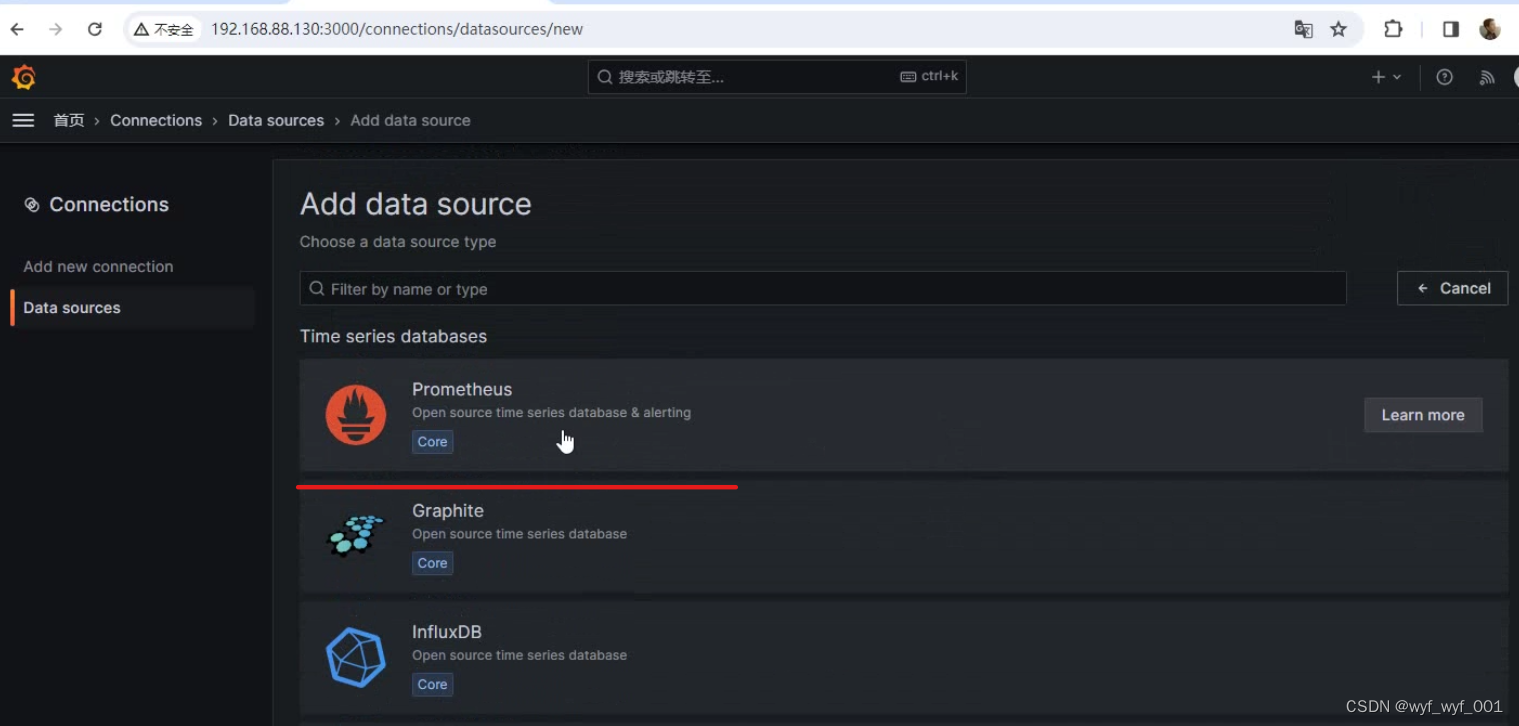
模板号:8919,由于图形模板作者会更新版本,软件版本和图形模板由于版本变更导致不兼容,要让软件跟随图形模板进行更新。
#右上角点击+号,导入仪表板—8919—load—Prometheus选择添加的数据源—import导入。
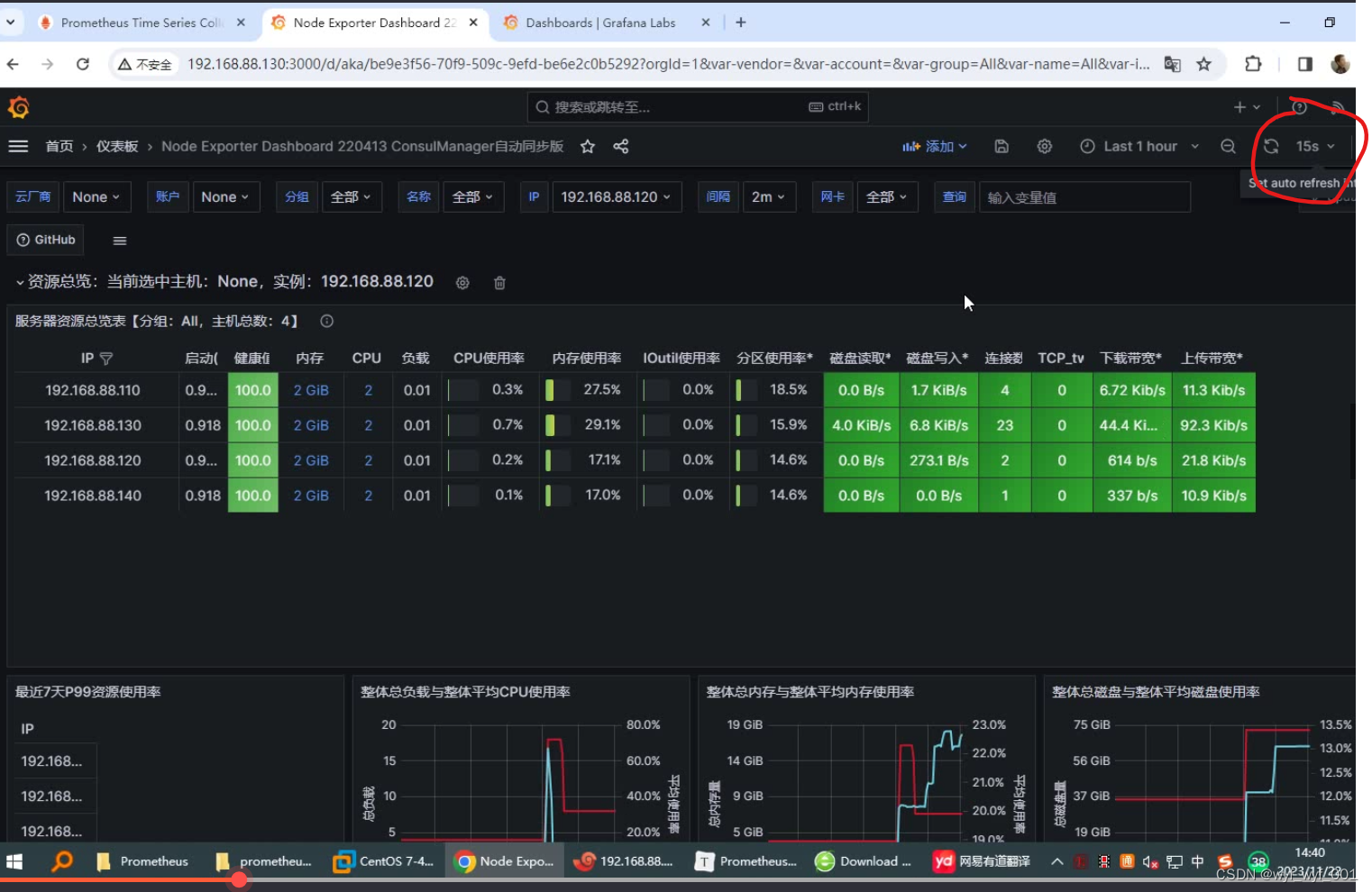
3.6. 效果展示——设置刷新时间为15秒
4、Prometheus - AlertManager部署(报警配置)
1、alertmanager组件安装
4.1 下载并安装alertmanager组件
$ tar -xf alertmanager-0.20.0.linux-amd64.tar.gz
$ cp -r alertmanager-0.20.0.linux-amd64 /usr/local/alertmanager
4.2 编写alertmanager启动脚本
$cat>/usr/local/alertmanager/alertmanager.service<<EOF
[Unit]
Description=Alertmanager
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/usr/local/alertmanager
ExecStart=/usr/local/alertmanager/alertmanager
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
4.3 添加启动脚本到systemd启动管理中
$ 100ln -s /usr/local/alertmanager/alertmanager.service /lib/systemd/system/
$ systemctl daemon-reload
$ systemctl start alertmanager
$ netstat -anpt |grep 9093
#默认没有被Prometheus调用,需要修改peometheus配置文件调用alertmanager组件
2、 alertmanager组件安装(邮件报警)
4.4 修改配置文件 - 实现基于邮件的报警(备份原始的,覆盖修改)
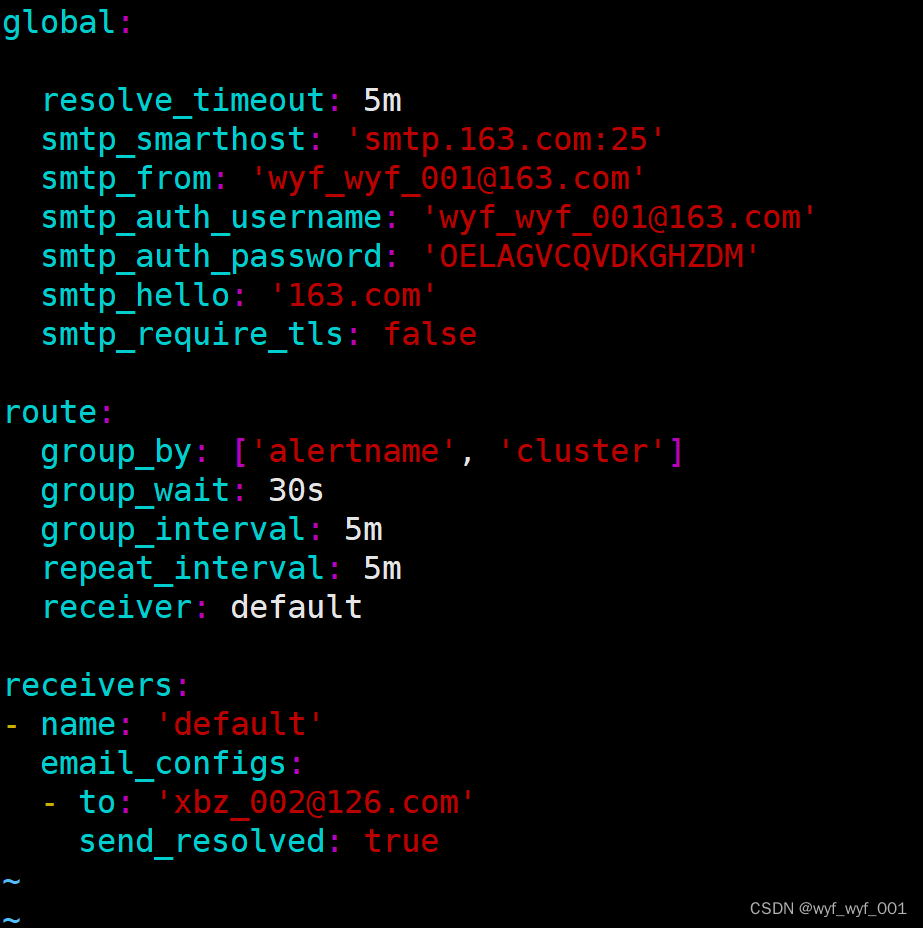
$ vim /usr/local/alertmanager/alertmanager.yml
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'wyf_wyf_001@163.com'
smtp_auth_username: 'wyf_wyf_001@163.com'
smtp_auth_password: 'OELAGVCQVDKGHZDM'
# 需要去网页端申请第三方登录专属密码
smtp_hello: '163.com'
smtp_require_tls: false
route:
group_by: ['alertname', 'cluster']
group_wait: 30s
group_interval: 5m
repeat_interval: 5m
receiver: default
receivers:
- name: 'default'
email_configs:
- to: 'xbz_002@126.com'
send_resolved: true
4.5 添加报警规则,进行效果测试
# 修改 /usr/local/prometheus/prometheus.yml 文件添加规则文件
$ vim /usr/local/prometheus/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.152.130:9093 #服务器IP和端口
rule_files:
- "rules/*rules.yml"
# 创建并修改 /usr/local/prometheus/rules/node1_rules.yml 文件添加监控规则

$ mkdir /usr/local/prometheus/rules/
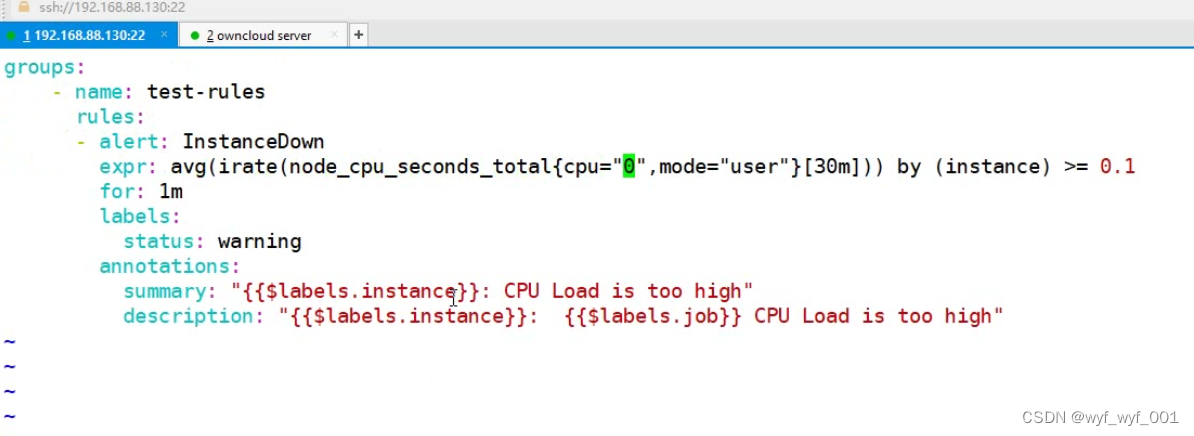
$ vim /usr/local/prometheus/rules/test_rules.yml
groups:
- name: test-rules
rules:
- alert: InstanceDown
expr: avg(irate(node_cpu_seconds_total{cpu="0",mode="user"}[30m])) by (instance) >= 0.1
#30分钟内用户消耗CPU的平均每分钟增量百分比大于等于0.1
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.instance}}: CPU Load is too high"
description: "{{$labels.instance}}: {{$labels.job}} CPU Load is too high"
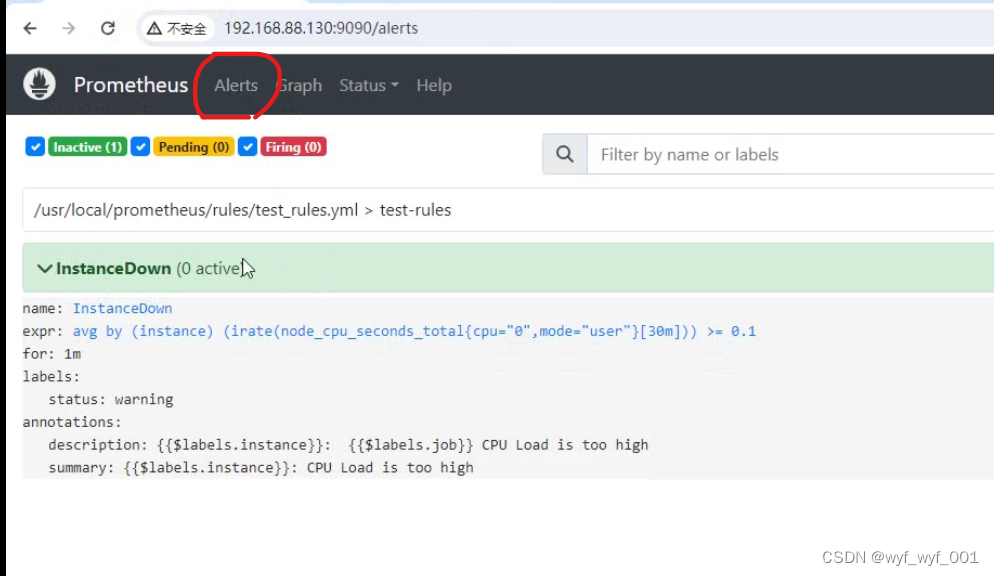
$ systemctl restart prometheus alertmanager
#浏览器查看是否有报警添加成功
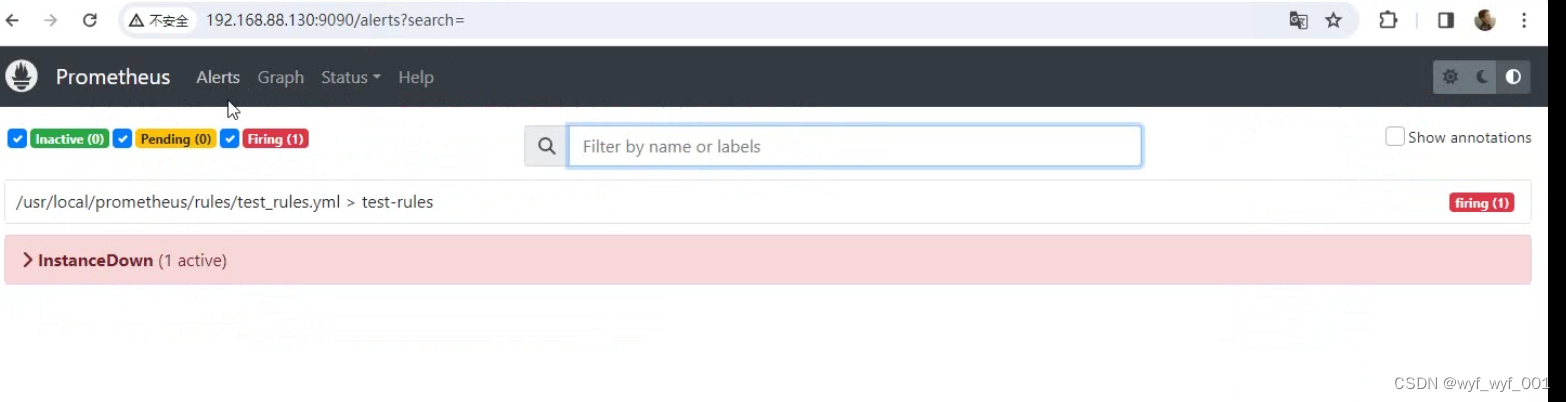
4.6 在被监控的机器上增加负载
$dd if=/dev/zero of=/dev/null & #可以多执行几次。
4.7 浏览器查看web页面有报警。
4.8 在Prometheus-server上继续创建报警模版
$ cd /usr/local/prometheus/rules
$vim test2_rules.yml
groups:
- name: test
rules:
- alert: CPU负载1分钟告警
expr: node_load1 / count (count (node_cpu_seconds_total) without (mode)) by (instance, job) > 2.5
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} 1分钟CPU负载(当前值: {{ $value }})"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job!~"(IDC-GPU|hw-nodes-prod-ES|nodes-test-GPU|nodes-dev-GPU)"}[30m])) by (instance) > 0.85
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU使用率告警 "
description: "{{$labels.instance}} CPU使用率超过85%(当前值: {{ $value }} )"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job=~"(IDC-GPU|hw-nodes-prod-ES)"}[30m])) by (instance) > 0.9
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} CPU使用率超过90%(当前值: {{ $value }})"
- alert: 内存使用率告警
expr: (1-node_memory_MemAvailable_bytes{job!="IDC-GPU"} / node_memory_MemTotal_bytes{job!="IDC-GPU"}) * 100 > 60
labels:
level: critical
annotations:
summary: "{{ $labels.instance }} 可用内存不足告警"
description: "{{$labels.instance}} 内存使用率已达90% (当前值: {{ $value }})"
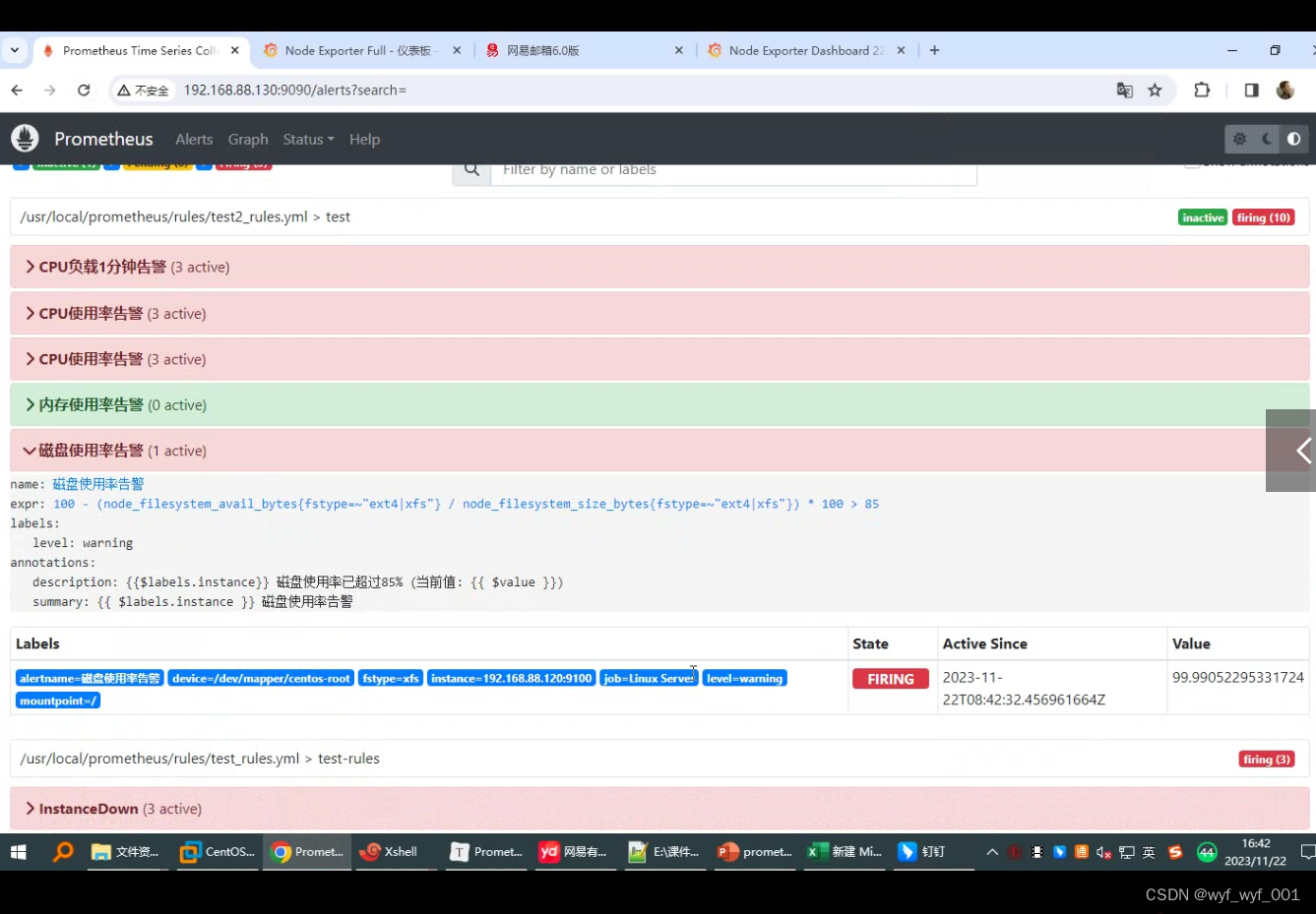
- alert: 磁盘使用率告警
expr: 100 - (node_filesystem_avail_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*" } / node_filesystem_size_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*"}) * 100 > 85
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} 磁盘使用率告警"
description: "{{$labels.instance}} 磁盘使用率已超过85% (当前值: {{ $value }})"
$systemctl restart prometheus
$浏览再次查看会多几个报警
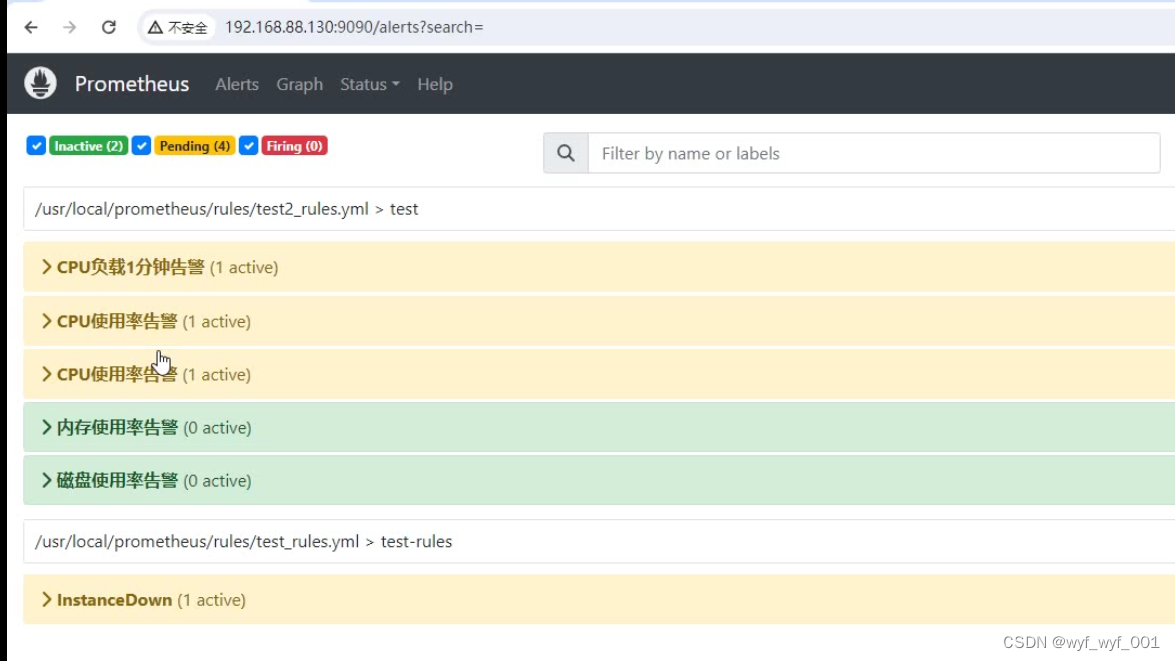
3、钉钉报警
1、在钉钉上添加机器人设置机器人名称——勾选加签——复制加签密钥(保存一份)——复制API接口
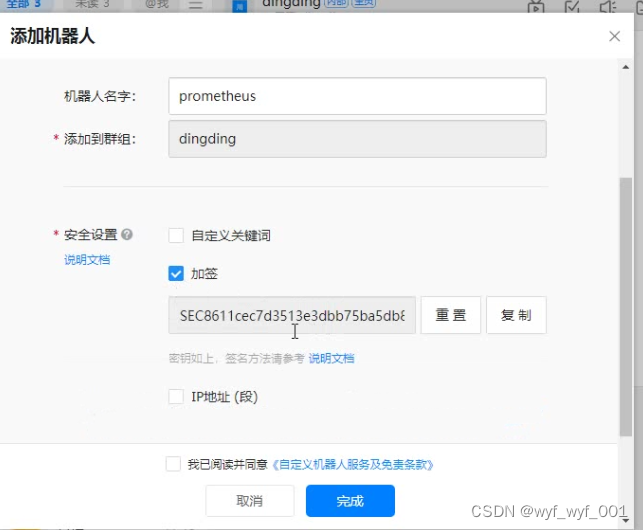
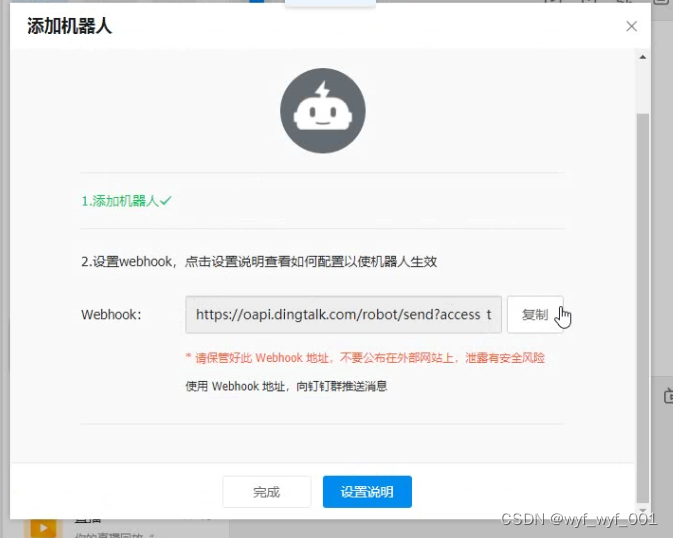
加签密钥:SEC445e54a9c3a877038ce302bfe07c1c511fe76c5034b4d05bddae2a5fb5fadef3
api接口:https://oapi.dingtalk.com/robot/send?access_token=fa20ed62eb9ed8dc06d3078399e55ca15266ad96dc3280482b1e903eafd707d7
2、在Prometheus-server上安装钉钉插件
$ tar -xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
$ cp -r prometheus-webhook-dingtalk-2.1.0.linux-amd64 /usr/local/dingtalk/
# 创建 service 启动文件
$ cd /usr/local/dingtalk/
$ vim dingtalk.service
[Unit]
Description=dingtalk
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/usr/local/dingtalk/
ExecStart=/usr/local/dingtalk/prometheus-webhook-dingtalk
Restart=on-failure
[Install]
WantedBy=multi-user.target
3、修改钉钉插件的配置文件
$ mv config.example.yml config.yml
$ vim config.yml
#取消templates和下一行的注释,开启调用告警模版的位置
#url:后面填写钉钉的APL接口位置
secret:后面填写钉钉的密钥
mobiles:后面填写钉钉报警手机号
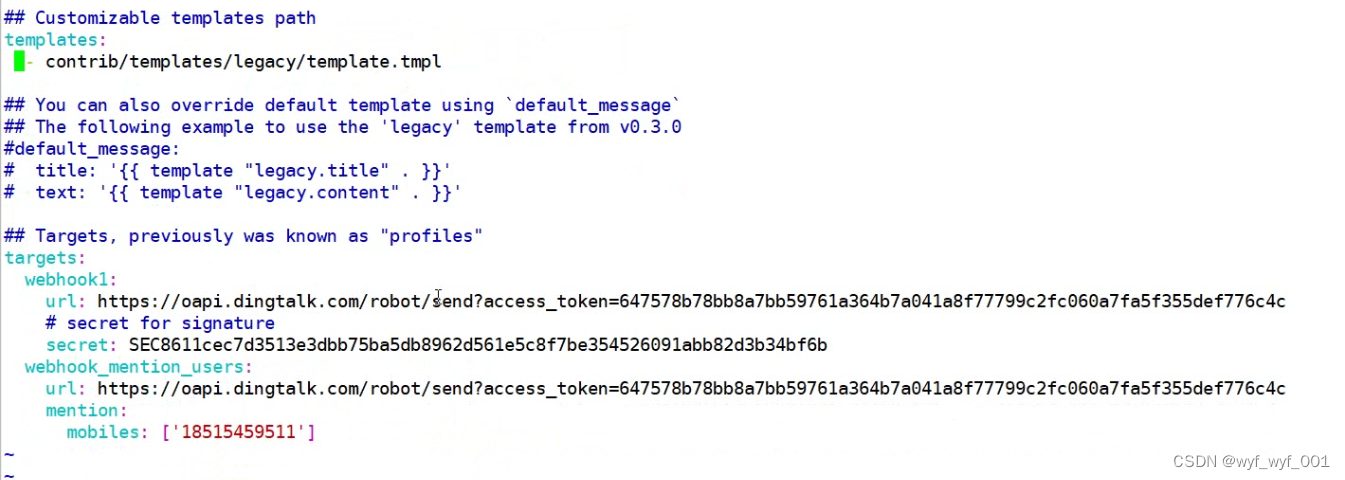
$ cd /usr/local/dingtalk/contrib/template/legacy
$vim template.tmpl
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
{{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
**告警名称**: {{ index .Annotations "title" }}
**告警级别**: {{ .Labels.severity }}
**告警主机**: {{ .Labels.instance }}
**告警信息**: {{ index .Annotations "description" }}
**告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
{{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
**告警名称**: {{ index .Annotations "title" }}
**告警级别**: {{ .Labels.severity }}
**告警主机**: {{ .Labels.instance }}
**告警信息**: {{ index .Annotations "description" }}
**告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**恢复时间**: {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
{{ end }}{{ end }}
{{ define "default.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "default.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
{{ template "default.title" . }}
{{ template "default.content" . }}
$ ln -s /usr/local/dingtalk/dingtalk.service /lib/systemd/system
$ systemctl daemon-reload
$ systemctl start dingtalk
$netstat -anpt |grep 8060 #查看8060端口
4、修改Prometheus报警组件的配置文件,让获取到的消息能发送给钉钉插件
$vim /usr/local/alertmanager/alertmanager.yml
#在最下面添加
webhook_configs:
- url: 'http://192.168.152.13:8060/dingtalk/webhook1/send'
send_resolved: true
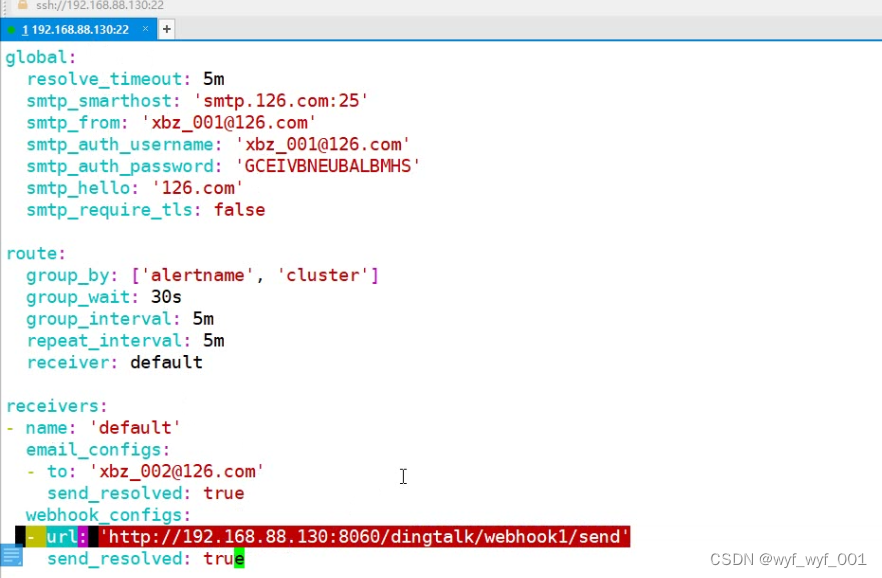
$ systemctl restart alertmanager
$ netstat -anpt |grep 9093
5、11和12主机制造报警条件
$ dd if=/dev/zero of=/dev/null & #多执行几次。查看报警。
$ dd if=/dev/zero of=/a.txt bs=1G count=16















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









