







降维也是一种无监督学习的问题。所谓的降维,就是将高维度的数据降低到低维度空间,同时降维之后的数据又能够很好的表征原来数据的特性。
以具体的例子来说明一下什么是降维:
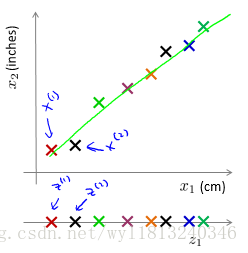
比如我们使用厘米和英尺表示同一物体的长度,如果我们使用一个仪器测量的结果单位是厘米,另一个仪器测量单位是英尺,两种仪器对同一物体测量的结果可能不完全相同(由于误差和精度),但是如果直接将两个特征都作为该物体长度的特征又很冗余,所以我们可以将上述二维的数据将至一维(具体怎么实现见下文)。
二维数据降至一维:找到一条直线,将二维向量投影到该直线上,达到数据从二维(x1,x2)降至一维(z1)的目的。
将三维的数据降至二维:将三维向量投影到一个二维平面上,迫使所有的数据都落在同一个平面上,从而实现从三维(x1,x2,x3)将至二维(z1,z2)。
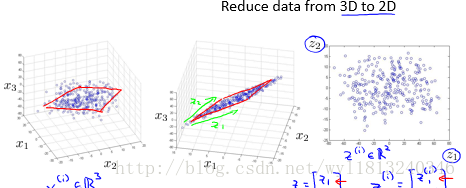
同样地,可以实现从任何维度的数据将至任何想要的维度。
降维的两个功能:
1. 数据的压缩。从上面例子中可以看出,明显对数据进行了压缩。
2. 数据的可视化。对于我们来说我们最多能够可视化一个三维的画面,但是有些数据的维度大于三维,使得我们没办法可视化,但是使用降维的办法可以实现将原来的数据将至三维、二维甚至一维,从而有助于可视化显示。但是降维之后产生新特征的意义就必须有我们自己去发现了。
主成分分析(Principal Component Analysis, PCA):
PCA是最常见的降维算法。它的思想为:找到一个由一系列方向向量组成的低维平面,当我们把所有的数据投射到该低维平面时,我们希望投射平均均方误差尽可能地小。投射误差是从特征向量向该低维平面做垂线的长度。
下面我们以二维为例,来对概念进行形象化表示:
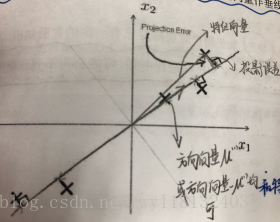
PCA方法的问题描述:
对于将n维数据降至k维来说,我们的目标就是找到向量 u1,u2,...,uk 使得总的投射误差最小。
PCA算法的过程如下:
1. 均值归一化(特征的缩放)。需要计算出所有特征的均值,然后令 xj=xj−uj ,同时如果特征是不同数量级上,我们还需要将其除以标准差。
2. 计算协方差矩阵 Σ :
3.计算协方差矩阵 Σ 的特征值:
在matlab中可以利用奇异值分解来求解,函数形式为:[U,S,V]=svd(sigma),同时也可以使用eig(sigma)来求解,但是对于半正定矩阵的sigma来说,svd更加具有数据的稳定性。
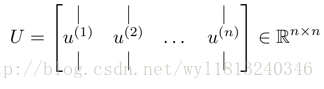
4. 获取符合要求的新的特征向量。
上式中的U就是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们想从n为将至k维,我们只需要从U中选取前k个向量,获得一个n*k的矩阵 Ureduce ,然后通过 Ureduce 获得符合要求的新的特征向量 zi :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3943
3943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









