






 数据仓库之父BillInmon和MaryLevins探讨了数据仓库和数据湖的演变。数据仓库解决了数据一致性问题,而数据湖提供了低成本存储。然而,两者都存在局限性,如数据湖的性能和质量问题。为了解决这些问题,出现了数据湖屋(datalakehouse)架构,它结合了数据仓库的结构和管理功能以及数据湖的低成本存储,支持开放访问、机器学习和高性能分析,旨在克服现有数据架构的挑战。
数据仓库之父BillInmon和MaryLevins探讨了数据仓库和数据湖的演变。数据仓库解决了数据一致性问题,而数据湖提供了低成本存储。然而,两者都存在局限性,如数据湖的性能和质量问题。为了解决这些问题,出现了数据湖屋(datalakehouse)架构,它结合了数据仓库的结构和管理功能以及数据湖的低成本存储,支持开放访问、机器学习和高性能分析,旨在克服现有数据架构的挑战。
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。
原始数据的挑战
随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找到在众多应用程序中使用哪个版本的数据才是正确的。如果用户没有找到并使用正确的数据,则可能做出错误的决定。
人们发现他们需要一种不同的架构方法来找到用于决策的正确数据。因此,数据仓库诞生了。
数据仓库
数据仓库导致不同的应用程序数据被放置在单独的地方。设计者必须围绕数据仓库建立一个全新的基础设施。
围绕数据仓库的分析基础设施包含以下内容:
•元数据(Metadata)– 一个关于数据位于何处的指南;•数据模型(A data model)– 数据仓库中数据的抽象;•数据血缘(Data lineage)– 数据仓库中数据的起源和转换;•摘要(Summarization)– 用于创建数据的算法工作的描述;•KPIs – 关键绩效指标在哪里;•ETL – 允许将应用程序数据转换为公司数据。
随着企业中数据(文本、物联网、图像、音频、视频等)的多样性增加,数据仓库的局限性变得明显。此外,机器学习(ML)和人工智能的兴起引入了迭代算法,这些算法需要直接访问数据,而不是基于 SQL。
公司的所有数据
一般情况下,数据仓库里面的数据是结构化的数据。但是现在公司中有许多其他的数据类型,包括结构化(Structured data)、文本数据(Textual data)以及非结构化(unstructured data)的数据。
结构化数据通常是组织为执行日常业务活动而生成的基于事务(transaction-based)的数据。文本数据是由公司内部发生的信件、电子邮件和对话生成的数据。非结构化数据是其他来源的数据,如物联网数据、图像、视频和基于模拟的数据。
数据湖
数据湖是企业中所有不同类型数据的集合。它已经成为企业存放所有数据的地方,因为它的低成本存储系统拥有一个文件 API,以通用和开放的文件格式保存数据,如 Apache Parquet 和 ORC。开放格式的使用也使得数据湖中的数据可以被其他分析引擎访问到,如机器学习系统。
最初构思数据湖时,人们认为只需要提取数据并将其放入数据湖即可。一旦进入数据湖,终端用户就可以一头扎进去,找到数据并进行分析。然而,企业很快发现,使用数据湖中的数据与仅仅将数据放入湖中完全是两码事。
由于缺乏一些关键特性,数据湖的许多承诺都没有实现:不支持事务,不保证数据质量,以及性能优化不佳。因此,企业中的大部分数据湖变成了数据沼泽(data swamps)。
当前数据架构面临的挑战
由于数据湖和数据仓库的局限性,常见的方法是使用多个系统——一个数据湖、几个数据仓库和其他专门的系统,这导致三个常见问题:
•缺乏开放性:数据仓库将数据转换为专有格式,这增加了将数据或工作负载迁移到其他系统的成本。由于数据仓库主要提供仅 SQL 的访问模式,因此很难运行其他分析引擎,如机器学习系统。此外,使用 SQL 直接访问数据仓库中的数据非常昂贵和缓慢,这使得与其他技术的集成变得非常困难。•对机器学习的支持有限:尽管有很多关于 ML 和数据管理融合的研究,但没有一个领先的机器学习系统,如 TensorFlow、PyTorch 和 XGBoost,能够很好地在仓库之上工作。与提取少量数据的 BI 系统不同,ML 系统使用复杂的非 SQL 代码处理大型数据集。对于这些用例,仓库供应商建议将数据导出到文件中,这进一步增加了系统的复杂性。•数据湖和数据仓库之间的强制权衡:超过90%的企业数据存储在数据湖中,这是因为数据湖使用廉价存储,从开放直接访问文件到低成本的灵活性。为了克服数据湖缺乏性能和质量的问题,企业将数据湖中的一小部分数据 ETL 到下游数据仓库,用于最重要的决策支持和 BI 应用。这种双系统架构需要对数据湖和数据仓库之间的 ETL 数据进行持续的工程处理。每个 ETL 步骤都有可能导致失败或引入 bug,从而降低数据质量,同时保持数据湖和数据仓库的一致性是非常困难和昂贵的。除了需要为持续的 ETL 支付费用外,用户还要为复制到仓库的数据支付两倍的存储成本。
data lakehouse 的诞生
当前,业界出现了一种称为 data lakehouse 的新型数据架构,它通过一种新的开放和标准化的系统设计来实现:其实现与数据仓库中类似的数据结构和数据管理功能,并将数据存放在数据湖使用的低成本存储系统中
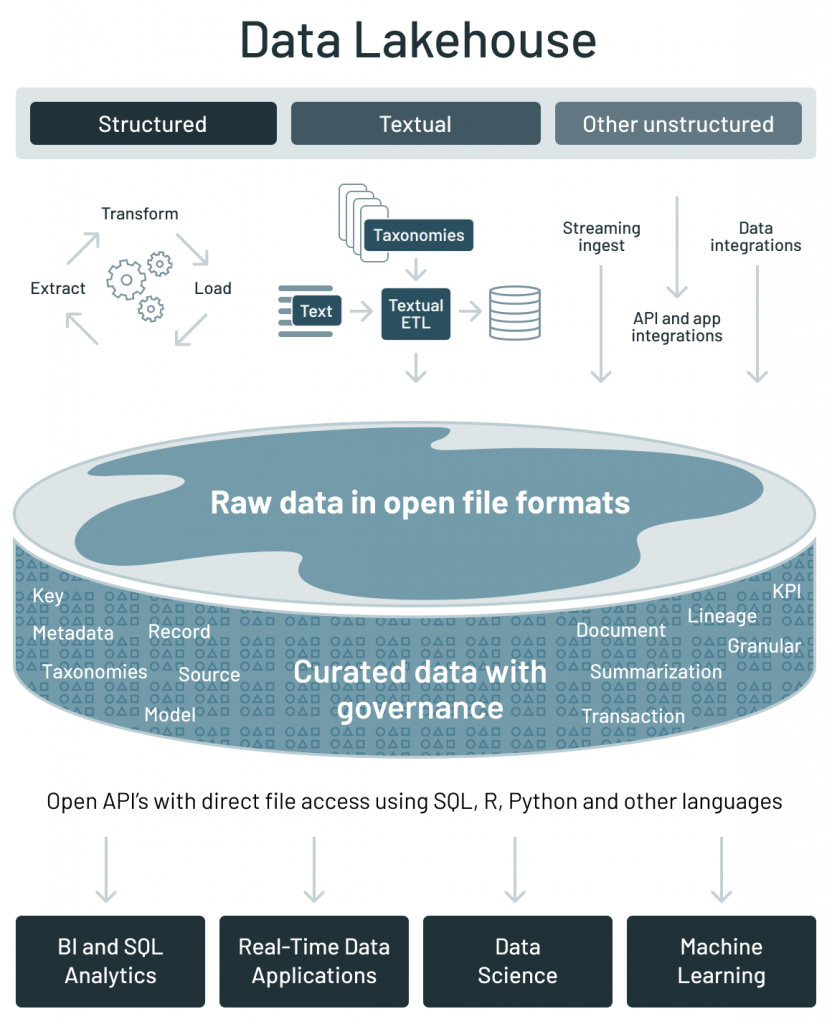
data lakehouse 架构解决了上一节讨论的当前数据架构的主要挑战:
•通过使用开放的数据存储格式(如 Apache Parquet)实现数据开放访问;•原生就支持数据科学和机器学习工作负载;•在低成本存储上提供一流的性能和可靠性。
以下是 data lakehouse 架构的主要优点:
开放性
•使用开放文件格式:基于开放和标准化的文件格式,如 Apache Parquet 和 ORC;•开放的 API:提供可以直接有效访问数据的开放 API,而不需要专有引擎和被厂商锁定;•语言支持:不仅支持 SQL 访问,还支持各种其他工具和引擎,包括机器学习和 Python/R 库
支持机器学习
•支持多种数据类型:为许多新的应用程序存储、精炼、分析和访问数据,包括图像、视频、音频、半结构化数据和文本;•高效的非 SQL 直接读取:使用 R 和 Python 库直接高效的访问大量数据,以运行机器学习实验;•对 DataFrame API 的支持:内置的声明式 DataFrame API 具有查询优化功能,可用于 ML 工作负载中的数据访问,因为诸如 TensorFlow,PyTorch 和XGBoost 的 ML 系统已采用 DataFrames 作为操作数据的主要抽象。•数据版本控制:提供数据快照,使数据科学和机器学习团队可以访问和还原到较早版本的数据,以进行审核和回滚或重现 ML 实验。
一流的性能和低成本的可靠性
•性能优化:通过利用文件统计信息,来启用各种优化技术,例如缓存,多维 clustering 和跳过无用数据;•模式增强和管理:支持星型/雪花模型等数据仓库模式架构,并提供健壮的数据治理和审计机制;•事务支持:当多方并发地读写数据(通常使用SQL)时,利用 ACID 事务来确保数据一致性;•低成本存储:Lakehouse 架构使用了低成本的对象存储,如 Amazon S3、Azure Blob 存储或 Google Cloud Storage。。
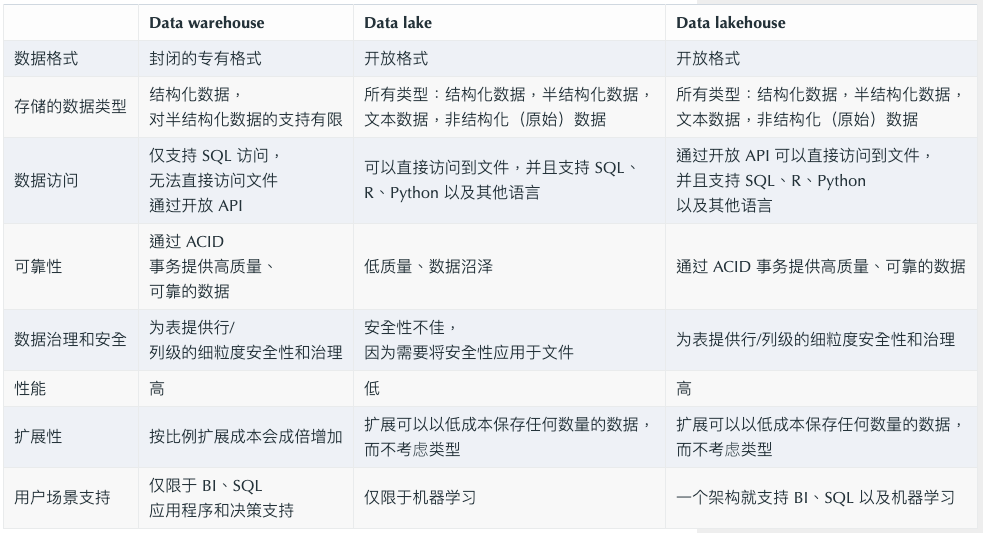
数据仓库、数据湖以及 data lakehouse 比较
data lakehouse 的影响
我们相信,data lakehouse 架构提供的机会,可以与我们在数据仓库市场的早期相媲美。data lakehouse 在开放环境中管理数据的独特能力,融合了企业各个部门的各种数据,并将数据湖中数据科学焦点与数据仓库中终端用户分析相结合,将为组织释放难以置信的价值。
本文翻译自《Evolution to the Data Lakehouse》:https://databricks.com/blog/2021/05/19/evolution-to-the-data-lakehouse.html

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









