







目录
欢迎关注我的博客!26届java选手,一起加油💘💦👨🎓😄😂
轻量化人群标签数据采集与Redis BitMap应用
最近在学习一个拼团项目中涉及到的人群模块的设计,写下一些实现与思考。
为什么需要人群标签?
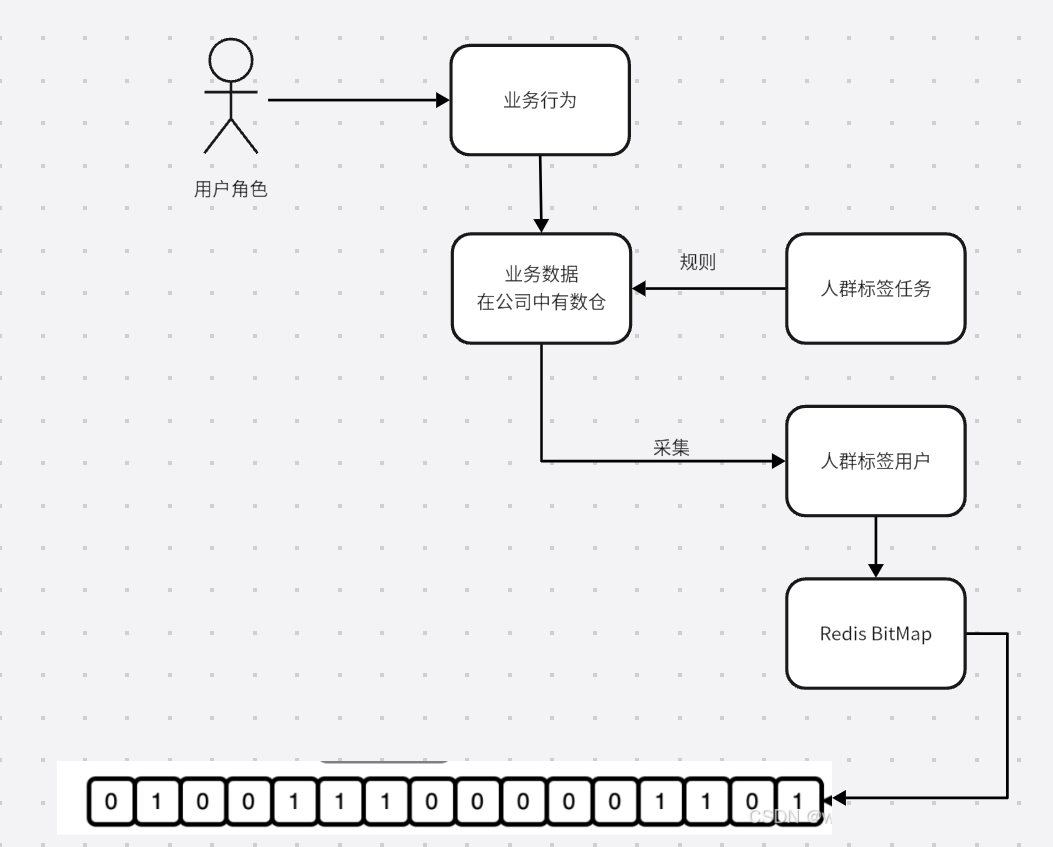
在电商平台中,精准的用户运营是提升转化率的核心。比如,拼多多需要通过用户行为(如拼团参与次数、消费金额)筛选目标人群,定向发放优惠券或推送活动通知。然而,面对海量用户数据(如百万级用户ID),传统数据库查询效率低、存储成本高,因此需要一种轻量化、高性能的解决方案。
设计思路:轻量化人群标签系统
1. 核心目标
- 低成本存储:用最小内存存储百万级用户ID的标签数据。
- 快速查询:支持实时判断用户是否属于某个人群标签。
- 可扩展性:支持多标签组合运算(如“同时满足标签A和标签B的用户”)。
2. 技术选型:Redis BitMap
- BitMap(位图):每个二进制位(bit)表示一个用户是否拥有标签,内存占用极低。
- 例如:100万用户仅需约122KB内存(100万/8/1024)。
- 位运算:通过
AND/OR操作快速计算交集、并集,适合多标签组合筛选。 - 原子操作:Redis的
SETBIT和GETBIT命令保证高并发下的数据一致性。
3. 数据链路设计
业务数据(拼团记录) → 数据库存储 → 标签计算 → 写入Redis BitMap → 运营投放
在实际业务中会有专门的记录用户标签的数据。
技术实现:代码级拆解
1. 人群标签任务调度
通过TagService.execTagBatchJob执行标签计算任务:
public void execTagBatchJob(String tagId, String batchId) {
// 1. 查询批次任务配置(如标签类型、统计时间范围)
CrowdTagsJobEntity jobEntity = repository.queryCrowdTagsJobEntity(tagId, batchId);
// 2. 模拟数仓数据采集(实际场景从数仓读取)
List<String> userIdList = getMockUserIds();
// 示例用户列表
// 3. 写入数据库
Redis BitMap for (String userId : userIdList) {
repository.addCrowdTagsUserId(tagId, userId);
}
// 4. 更新标签统计量
repository.updateCrowdTagsStatistics(tagId, userIdList.size()); }- 批次ID(batchId):用于区分同一标签的多次计算任务(如修复数据后重跑)。
2. 用户ID与BitMap索引映射
在TagRepository中,用户ID通过哈希函数映射到BitMap的索引位置:
public void addCrowdTagsUserId(String tagId, String userId) {
// 1. 写入数据库(持久化存储)
crowdTagsDetailDao.addCrowdTagsUserId(tagId, userId);
// 2. 写入Redis
BitMap RBitSet bitSet = redisService.getBitSet(tagId);
int index = redisService.getIndexFromUserId(userId);
// 用户ID → 哈希索引
bitSet.set(index, true);
}- 索引映射:
- 用户ID(字符串)通过哈希函数转换为整数(如
MurmurHash)。 - 对哈希值取模(如
userId.hashCode() % 1_000_000),确保索引在BitMap范围内。
- 用户ID(字符串)通过哈希函数转换为整数(如
default int getIndexFromUserId(String userId) {
try {
// 步骤1:获取 MD5 哈希算法实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 步骤2:计算用户ID的 MD5 哈希值
byte[] hashBytes = md.digest(userId.getBytes(StandardCharsets.UTF_8));
// 步骤3:将哈希值转换为正整数
BigInteger bigInt = new BigInteger(1, hashBytes);
// 步骤4:对最大值取模,确保索引在合理范围内
return bigInt.mod(BigInteger.valueOf(Integer.MAX_VALUE)).intValue();
} catch (NoSuchAlgorithmException e) {
// 异常处理:MD5算法不存在时抛出运行时异常
throw new RuntimeException("MD5 algorithm not found", e);
}
}3. BitMap的读写验证
通过测试用例验证数据是否正确写入:
@Test public void test_get_tag_bitmap() {
RBitSet bitSet = redisService.getBitSet("RQ_KJHKL98UU78H66554GFDV");
log.info("用户 wuwuw是否存在?{}", bitSet.get(redisService.getIndexFromUserId("xiaofuge"))); // 预期 true
log.info("用户 gudebai 是否存在{}",bitSet.get(redisService.getIndexFromUserId("gudebai"))); // 预期 false }效果与优势
1. 存储成本对比
| 存储方式 | 100万用户内存占用 | 查询性能 |
|---|---|---|
| MySQL 索引表 | 约50MB | 毫秒级(带索引) |
| Redis Set | 约16MB | 毫秒级 |
| Redis BitMap | 122KB | 微秒级 |
2. 查询场景示例
- 定向发券:判断用户是否属于“高活跃拼团用户”标签(
GETBIT操作)。 - 组合筛选:找出“近30天消费满100元且参与3次拼团”的用户(
BITOP AND运算)。
3. 运营价值
- 精准投放:运营人员可通过标签快速圈定目标用户,提升活动转化率。
- 实时性:BitMap支持实时更新和查询,适合动态调整投放策略。
总结与扩展
1. 轻量化设计的意义
- 低成本验证:在小规模数据下验证技术方案,避免过早依赖数仓。
- 快速迭代:通过拼团数据快速生成标签,缩短需求上线周期。
2. 未来扩展方向
- 复杂规则支持:引入规则引擎解析
tagRule(如JSON配置),动态生成标签。 - 数据源扩展:集成订单、浏览行为等多维度数据,丰富标签类型。
- 自动化调度:结合Quartz定时任务,定期更新标签数据。
通过本文,可以为你快速掌握如何在小规模数据下构建高效的人群标签系统提供一些思路。

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









