







本文主要讲解了Linux内核二层数据包接收流程,
使用的内核的版本是2.6.32.27
为了方便理解,
本文采用整体流程图加伪代码的方式
从内核高层面上梳理了二层数据包接收的流程,
希望可以对大家有所帮助。
阅读本文章假设大家对C语言有了一定的了解
整体流程如下:
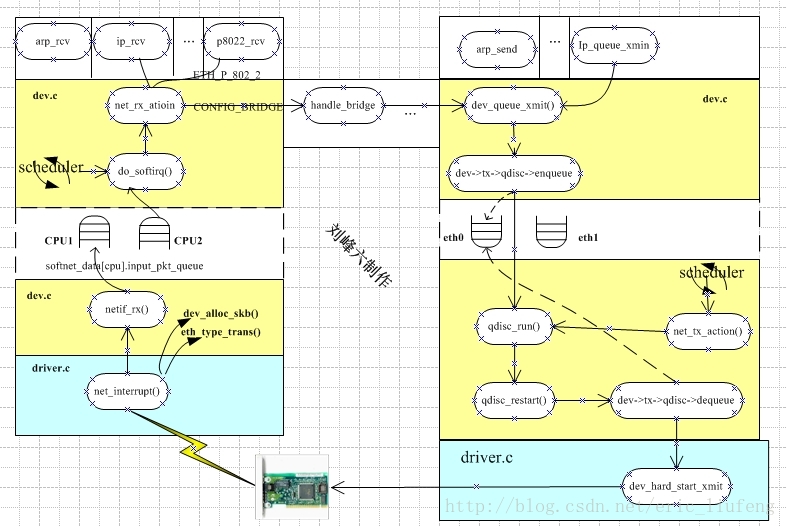
数据报文接收流程伪代码分析如下
- /*在基于中断收发报文的网卡设备驱动中,
- * 当有数据报文进来的时候,使用net_interrupt()进行中断触发
- *如 isa-skeleton设备驱动中*/
- static int __init netcard_probe1(struct net_device *dev, int ioaddr)
- {
- /*注册net_interrupt为中断处理历程*/
- int irqval = request_irq(dev->irq, &net_interrupt, 0, cardname, dev);
- if (irqval) {
- printk("%s: unable to get IRQ %d (irqval=%d).\n",
- dev->name, dev->irq, irqval);
- goto out;
- }
- //......
- return err;
- }
- static irqreturn_t net_interrupt(int irq, void *dev_id)
- {
- //......
- if (status & RX_INTR) {
- /* Got a packet(s). */
- /*使用NET_RX实现进行发送数据报文*/
- net_rx(dev);
- }
- #if TX_RING
- if (status & TX_INTR) {
- /* Transmit complete. */
- net_tx(dev);
- np->stats.tx_packets++;
- netif_wake_queue(dev);
- }
- #endif
- return IRQ_RETVAL(handled);
- }
- /* We have a good packet(s), get it/them out of the buffers. */
- static void
- net_rx(struct net_device *dev)
- {
- /*使用dev_alloc_skb来分配skb,并把数据报文复制到skb中*/
- skb = dev_alloc_skb(pkt_len);
- if (skb == NULL) {
- //......
- }
- skb->dev = dev;
- /* 'skb->data' points to the start of sk_buff data area. */
- memcpy(skb_put(skb,pkt_len), (void*)dev->rmem_start, pkt_len);
- /* or */
- insw(ioaddr, skb->data, (pkt_len + 1) >> 1);
- /*调用netif_rx将数据报文交给上层处理*/
- netif_rx(skb);
- return;
- }
- DEFINE_PER_CPU(struct netif_rx_stats, netdev_rx_stat) = { 0, };
- /*完成中断处理过程*/
- int netif_rx(struct sk_buff *skb)
- {
- struct softnet_data *queue;
- unsigned long flags;
- /*取得当前时间存储在skb->tstamp中*/
- if (!skb->tstamp.tv64)
- net_timestamp(skb);
- /*
- * The code is rearranged so that the path is the most
- * short when CPU is congested, but is still operating.
- */
- local_irq_save(flags);
- /*取得当前CPU的softnet_data,*/
- queue = &__get_cpu_var(softnet_data);
- if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
- if (queue->input_pkt_queue.qlen) {
- enqueue:
- /*将SKB放入到softnet_data[CPU].input_pkt_queue中
- *一旦数据包出于该对列,中断就处理完成了*/
- __skb_queue_tail(&queue->input_pkt_queue, skb);
- local_irq_restore(flags);
- return NET_RX_SUCCESS;
- }
- /*如果queue->input_pkt_queue.qlen中已经有上次的数据包,
- *发起NET_RX_SOFTIRQ软中断,由软中断的处理函数net_rx_action进行发送*/
- napi_schedule(&queue->backlog);
- {
- __napi_schedule(n)
- {
- list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);
- __raise_softirq_irqoff(NET_RX_SOFTIRQ);
- }
- }
- goto enqueue;
- }
- __get_cpu_var(netdev_rx_stat).dropped++;
- local_irq_restore(flags);
- kfree_skb(skb);
- return NET_RX_DROP;
- }
- /*注册软中断NET_RX_SOFTIRQ的处理函数为net_rx_action*/
- static int __init net_dev_init(void)
- {
- open_softirq(NET_RX_SOFTIRQ, net_rx_action);
- }
- /*必须要有NAPI的POLL么?没有NAPI的POLL回调怎么送往协议栈*/
- static void net_rx_action(struct softirq_action *h)
- {
- struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
- while (!list_empty(list)) {
- struct napi_struct *n;
- n = list_entry(list->next, struct napi_struct, poll_list);
- /*调用每款驱动对NAPI注册的POLL函数,如pcnet32_poll
- *在POLL函数的RX部分里面,会调用netif_receive_skb将
- *数据包交给协议栈处理*/
- work = n->poll(n, weight);
- WARN_ON_ONCE(work > weight);
- budget -= work;
- local_irq_disable();
- /* Drivers must not modify the NAPI state if they
- * consume the entire weight. In such cases this code
- * still "owns" the NAPI instance and therefore can
- * move the instance around on the list at-will.
- */
- if (unlikely(work == weight)) {
- if (unlikely(napi_disable_pending(n))) {
- local_irq_enable();
- napi_complete(n);
- local_irq_disable();
- } else
- list_move_tail(&n->poll_list, list);
- }
- netpoll_poll_unlock(have);
- }
- out:
- local_irq_enable();
- #ifdef CONFIG_NET_DMA
- /*
- * There may not be any more sk_buffs coming right now, so push
- * any pending DMA copies to hardware
- */
- dma_issue_pending_all();
- #endif
- return;
- softnet_break:
- __get_cpu_var(netdev_rx_stat).time_squeeze++;
- __raise_softirq_irqoff(NET_RX_SOFTIRQ);
- goto out;
- }
- /*在RX部分里,会调用*/
- static int pcnet32_poll(struct napi_struct *napi, int budget)
- {
- /*RX部分*/
- work_done = pcnet32_rx(dev, budget);
- {
- pcnet32_rx_entry()
- {
- netif_receive_skb(skb);
- }
- }
- /*TX部分*/
- pcnet32_tx(dev);
- return work_done;
- }
- int netif_receive_skb(struct sk_buff *skb)
- {
- struct packet_type *ptype, *pt_prev;
- struct net_device *orig_dev;
- pt_prev = NULL;
- /*看看ptype_all中有没有相应的协议进行相应的协议处理,一般这里没有注册的协议,但是可以加入我们的分析钩子函数*/
- list_for_each_entry_rcu(ptype, &ptype_all, list) {
- if (ptype->dev == null_or_orig || ptype->dev == skb->dev || ptype->dev == orig_dev) {
- if (pt_prev)
- /*协议分发函数*/
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = ptype;
- }
- }
- /*处理网桥配置的数据报文*/
- skb = handle_bridge(skb, &pt_prev, &ret, orig_dev);
- if (!skb)
- goto out;
- skb = handle_macvlan(skb, &pt_prev, &ret, orig_dev);
- if (!skb)
- goto out;
- /*对ptype_base表中的协议进行遍历,如果找到对应的协议,送往对应的协议栈进行处理*/
- type = skb->protocol;
- list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
- if (ptype->type == type && (ptype->dev == null_or_orig || ptype->dev == skb->dev || ptype->dev == orig_dev)) {
- if (pt_prev)
- /*协议分发函数*/
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = ptype;
- }
- }
- if (pt_prev) {
- ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
- }
- else
- {
- kfree_skb(skb);
- ret = NET_RX_DROP;
- }
- out:
- rcu_read_unlock();
- return ret;
- }
- /*调用相应协议的func进行处理*/
- static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev)
- {
- return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
- }
- /*在af_inet.c文件中对IPV4的处理注册为ip_rcv,所以IPV4对应的FUNC为ip_rcv*/
- static struct packet_type ip_packet_type __read_mostly = {
- .type = cpu_to_be16(ETH_P_IP),
- .func = ip_rcv,
- };
- /*
- * Main IP Receive routine.
- */
- int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
- {
- //......
- }
从分析的伪代码可以看出,
数据包接受的时候,可以基于2中方式触发:1 收发中断 2 NAPI的轮询机制
这里没有分析驱动代码对硬件的操作,
这部分代码在设备驱动程序中,本文举例了2款网卡代码 pcnet32 和 isa-skeleton,
当硬件接受完毕之后就进入dev层面进行内核的总体调度,这也是上面伪代码分析的重点。
当软中断被触发后,内核会回调每款驱动注册的poll函数钩子,进而进行首发处理,
在POLL的RX阶段中,会对报文进行分类送往不同的协议进行处理,
这里举例ipv4的处理入口ip_rcv(),但是没有深入进去,后面的文章中将进行细致讲解。
最后在POLL的TX阶段里面,对已经处理好的发送队列中的数据进行发送,
在该阶段中会将数据报文映射到PCI DMA的发送ring中,并且调用netif_wake_queue(dev),
来通知高层调用device注册的 ndo_hard_start_xmit函数进行硬件发送,
后面发送的处理流程请参考我的上一篇博客:
<<Linux内核数据包的发送传输>>(http://blog.csdn.net/eric_liufeng/article/details/10252857)
original link:http://blog.csdn.net/eric_liufeng/article/details/10286593















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









