






Linux数据包接收流程
硬中断处理
⾸先当数据帧从⽹线到达⽹卡上的时候,第⼀站是⽹卡的接收队列。⽹卡在分配给⾃⼰的RingBuffer 中寻找可⽤的内存位置,找到后 DMA 引擎会把数据 DMA 到⽹卡之前关联的内存⾥,这个时候 CPU 都是⽆感的。当 DMA 操作完成以后,⽹卡会向 CPU 发起⼀个硬中断,通知 CPU 有数据到达。
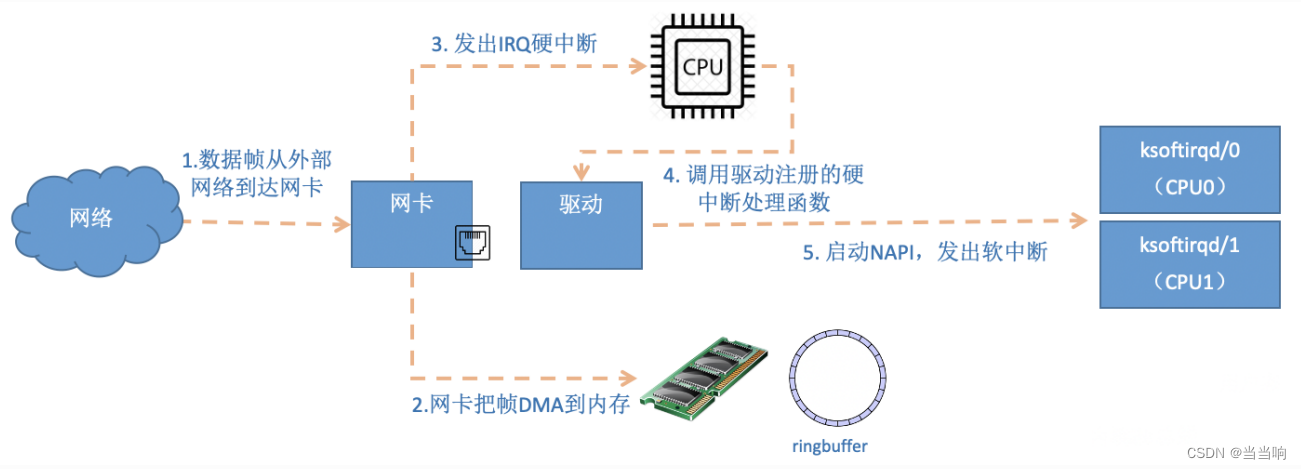
注意:当RingBuffer满的时候,新来的数据包将给丢弃。ifconfig查看⽹卡的时候,可以⾥⾯有个overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过ethtool命令来加⼤环形队列的⻓度。
在启动⽹卡⼀节,我们说到了⽹卡的硬中断注册的处理函数是igb_msix_ring。
//file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previousinterrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
igb_write_itr 只是记录⼀下硬件中断频率(据说⽬的是在减少对 CPU 的中断频率时⽤到)。顺着 napi_schedule 调⽤⼀路跟踪下去, __napi_schedule => ____napi_schedule
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
这⾥我们看到, list_add_tail 修改了 CPU 变量 softnet_data ⾥的 poll_list ,将驱动napi_struct 传过来的 poll_list 添加了进来。其中 softnet_data 中的 poll_list 是⼀个双向列表,其中的设备都带有输⼊帧等着被处理。紧接着 _raise_softirq_irqoff 触发了⼀个软中断 NET_RX_SOFTIRQ, 这个所谓的触发过程只是对⼀个变量进⾏了⼀次或运算⽽已。
void __raise_softirq_irqoff(unsigned int nr) {
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
我们说过,Linux 在硬中断⾥只完成简单必要的⼯作,剩下的⼤部分的处理都是转交给软中断的。通过上⾯代码可以看到,硬中断处理过程真的是⾮常短。只是记录了⼀个寄存器,修改了⼀下下 CPU 的 poll_list,然后发出个软中断。就这么简单,硬中断⼯作就算是完成了。
ksoftirqd 内核线程处理软中断
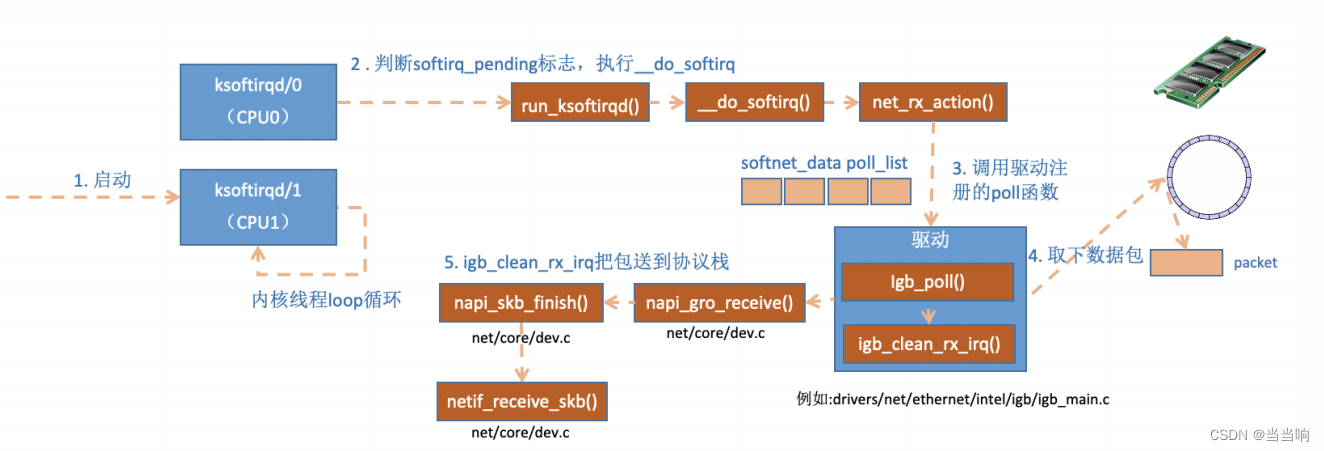
内核线程初始化的时候,我们介绍了 ksoftirqd 中两个线程函数 ksoftirqd_should_run 和run_ksoftirqd 。其中 ksoftirqd_should_run 代码如下:
static int ksoftirqd_should_run(unsigned int cpu) {
return local_softirq_pending();
}
#define local_softirq_pending() \
__IRQ_STAT(smp_processor_id(), __softirq_pending)
这⾥看到和硬中断中调⽤了同⼀个函数 local_softirq_pending 。使⽤⽅式不同的是硬中断位置是为了写⼊标记,这⾥仅仅只是读取。如果硬中断中设置了 NET_RX_SOFTIRQ ,这⾥⾃然能读取的到。接下来会真正进⼊线程函数中 run_ksoftirqd 处理:
static void run_ksoftirqd(unsigned int cpu) {
local_irq_disable();
if (local_softirq_pending()) {
__do_softirq();
rcu_note_context_switch(cpu);
local_irq_enable();
cond_resched();
return;
}
local_irq_enable();
}
在 __do_softirq 中,判断根据当前 CPU 的软中断类型,调⽤其注册的 action ⽅法。
asmlinkage void __do_softirq(void) {
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
...
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
...
}
h++;
pending >>= 1;
} while (pending);
}
这⾥需要注意⼀个细节,硬中断中设置软中断标记,和 ksoftirq 的判断是否有软中断到达,都是基于 smp_processor_id() 的。这意味着只要硬中断在哪个 CPU 上被响应,那么软中断也是在这个 CPU 上处理的。所以说,如果你发现你的 Linux 软中断 CPU 消耗都集中在⼀个核上的话,做法是要把调整硬中断的 CPU 亲和性,来将硬中断打散到不同的 CPU 核上去。
我们再来把精⼒集中到这个核⼼函数 net_rx_action 上来。
//file:net/core/dev.c
static void net_rx_action(struct softirq_action *h) {
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
......
n = list_first_entry(&sd->poll_list, structnapi_struct, poll_list);
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
budget -= work;net_rx_action
}
}
有同学问在硬中断中添加设备到 poll_list,会不会重复添加呢?答案是不会的,在软中断处理函数 net_rx_action 这⾥⼀进来就调⽤ local_irq_disable 把所有的硬中断都给关了,不会让硬中断重复添加 poll_list 的机会。在硬中断的处理函数中本身也有类似的判断机制,打磨了⼏⼗年的内核考虑在细节考虑上还是很完善的。
函数开头的 time_limit 和 budget 是⽤来控制 net_rx_action 函数主动退出的,⽬的是保证⽹络包的接收不霸占 CPU 不放。 等下次⽹卡再有硬中断过来的时候再处理剩下的接收数据包。其中 budget 可以通过内核参数调整。 这个函数中剩下的核⼼逻辑是获取到当前 CPU变量 softnet_data,对其 poll_list 进⾏遍历, 然后执⾏到⽹卡驱动注册到的 poll 函数。对于igb ⽹卡来说,就是 igb 驱动⾥的 igb_poll 函数了。
/**
* igb_poll - NAPI Rx polling callback
* @napi: napi polling structure
* @budget: count of how many packets we should handle
**/
static int igb_poll(struct napi_struct *napi, int budget) {
...
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget);
...
}
在读取操作中, igb_poll 的重点⼯作是对 igb_clean_rx_irq 的调⽤。
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget) {
...
do {
/* retrieve a buffer from the ring */
skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
}
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
}
igb_fetch_rx_buffer和 igb_is_non_eop 的作⽤就是把数据帧从 RingBuffer 上取下来。为什么需要两个函数呢?因为有可能帧要占多个 RingBuffer,所以是在⼀个循环中获取的,直到帧尾部。获取下来的⼀个数据帧⽤⼀个 sk_buff 来表示。收取完数据以后,对其进⾏⼀些校验,然后开始设置 sbk 变量的 timestamp, VLAN id, protocol 等字段。接下来进⼊到napi_gro_receive 中:
//file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) {
skb_gro_reset_offset(skb);
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
dev_gro_receive 这个函数代表的是⽹卡 GRO 特性,可以简单理解成把相关的⼩包合并成⼀个⼤包就⾏,⽬的是减少传送给⽹络栈的包数,这有助于减少 CPU 的使⽤量。我们暂且忽略,直接看 napi_skb_finish , 这个函数主要就是调⽤了 netif_receive_skb 。
//file: net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb) {
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb(skb))
ret = GRO_DROP;
break;
......
}
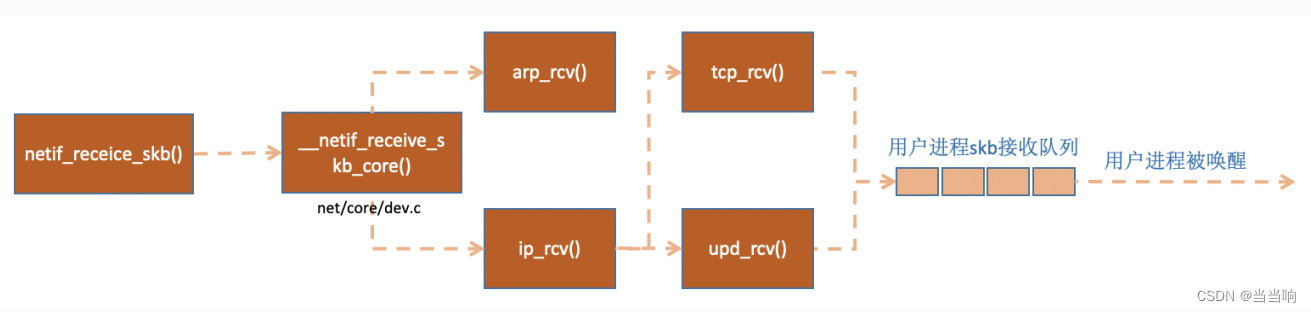
在 netif_receive_skb 中,数据包将被送到协议栈中。
⽹络协议栈处理
netif_receive_skb 函数会根据包的协议,假如是 udp 包,会将包依次送到 ip_rcv(), udp_rcv() 协议处理函数中进⾏处理。
//file: net/core/dev.c
int netif_receive_skb(struct sk_buff *skb) {
//RPS处理逻辑,先忽略
......
return __netif_receive_skb(skb);
}
static int __netif_receive_skb(struct sk_buff *skb) {
......
ret = __netif_receive_skb_core(skb, false);
}
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) {
......
//pcap逻辑,这⾥会将数据送⼊抓包点。tcpdump就是从这个⼊⼝获取包的
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
......
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&(ptype->dev == null_or_dev || ptype->dev == skb- >dev
|| ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
}
在 netif_receive_skb_core 中,我看着了原来经常使⽤的 tcpdump 的抓包点,很是激动,看来读⼀遍源代码时间真的没⽩浪费。接着 netif_receive_skb_core 取出protocol,它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列 表。 ptype_base 是⼀个 hash table,在协议注册⼩节我们提到过。ip_rcv 函数地址就是存 在这个 hash table 中的。
//file: net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) {
......
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
pt_prev->func 这⼀⾏就调⽤到了协议层注册的处理函数了。对于 ip 包来讲,就会进⼊到ip_rcv (如果是arp包的话,会进⼊到arp_rcv)。
IP 协议层处理
我们再来⼤致看⼀下 linux 在 ip 协议层都做了什么,包⼜是怎么样进⼀步被送到 udp 或 tcp协议处理函数中的。
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) {
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
}
这⾥ NF_HOOK 是⼀个钩⼦函数,当执⾏完注册的钩⼦后就会执⾏到最后⼀个参数指向的函数ip_rcv_finish 。
static int ip_rcv_finish(struct sk_buff *skb) {
......
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph- >saddr,iph->tos, skb->dev);
...
}
......
return dst_input(skb);
}
跟踪 ip_route_input_noref 后看到它⼜调⽤了 ip_route_input_mc 。 在ip_route_input_mc 中,函数 ip_local_deliver 被赋值给了 dst.input , 如下:
//file: net/ipv4/route.c
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr, u8 tos, struct net_device *dev, int our)
{
if (our) {
rth->dst.input= ip_local_deliver;
rth->rt_flags |= RTCF_LOCAL;
}
}
所以回到 ip_rcv_finish 中的 return dst_input(skb) 。
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb) {
return skb_dst(skb)->input(skb);
}
skb_dst(skb)->input 调⽤的 input ⽅法就是路由⼦系统赋的 ip_local_deliver。
//file: net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb) {
/*
* Reassemble IP fragments.
*/
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb- >dev, NULL,ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct sk_buff *skb) {
......
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
ret = ipprot->handler(skb);
}
}
如协议注册⼩节看到 inet_protos 中保存着 tcp_v4_rcv() 和 udp_rcv() 的函数地址。这⾥将会根据包中的协议类型选择进⾏分发,在这⾥ skb 包将会进⼀步被派送到更上层的协议中,udp 和 tcp。
总结
⽹络模块是 Linux 内核中最复杂的模块了,看起来⼀个简简单单的收包过程就涉及到许多内核 组件之间的交互,如⽹卡驱动、协议栈,内核 ksoftirqd 线程等。
看起来很复杂,本⽂想通过源码 + 图示的⽅式,尽量以容易理解的⽅式来将内核收包过程讲清楚。现在让我们再串⼀串整个收包过程。
当⽤户执⾏完 recvfrom 调⽤后,⽤户进程就通过系统调⽤进⾏到内核态⼯作了。如果接收队列没有数据,进程就进⼊睡眠状态被操作系统挂起。这块相对⽐较简单,剩下⼤部分的戏份都是由 Linux 内核其它模块来表演了。
⾸先在开始收包之前,Linux 要做许多的准备⼯作:
-
创建ksoftirqd线程,为它设置好它⾃⼰的线程函数,后⾯就指望着它来处理软中断呢。
-
协议栈注册,linux要实现许多协议,⽐如arp,icmp,ip,udp,tcp,每⼀个协议都会将⾃⼰的处理函数注册⼀下,⽅便包来了迅速找到对应的处理函数
-
⽹卡驱动初始化,每个驱动都有⼀个初始化函数,内核会让驱动也初始化⼀下。在这个初始化过程中,把⾃⼰的DMA准备好,把NAPI的poll函数地址告诉内核
-
启动⽹卡,分配RX,TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要⼯作,当上⾯都 ready 之后,就可以打开硬中断,等待数据包的到来了。
当数据到到来了以后,第⼀个迎接它的是⽹卡:
- ⽹卡将数据帧 DMA 到内存的 RingBuffer 中,然后向 CPU 发起中断通知
- CPU 响应中断请求,调⽤⽹卡启动时注册的中断处理函数
- 中断处理函数⼏乎没⼲啥,就发起了软中断请求
- 内核线程 ksoftirqd 线程发现有软中断请求到来,先关闭硬中断
- ksoftirqd 线程开始调⽤驱动的 poll 函数收包
- poll 函数将收到的包送到协议栈注册的 ip_rcv 函数中
- ip_rcv 函数再将包送到 udp_rcv 函数中(对于 tcp 包就送到 tcp_rcv )
参考链接:
推荐一个零声学院后台服务器免费公开课,个人觉得老师讲得不错,分享给大家:
https://course.0voice.com/v1/course/intro?courseId=5&agentId=0














 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









