









这里写自定义目录标题


写在前面
多智能体+分布式训练非常非常吃内存,本文所附代码强烈建议使用高于32GB内存的机器进行训练
本项目分为两个部分:论文解读与代码实现。解读部分会尽量脱离公式谈谈自己的理解,代码实现部分会讲一讲实现的思路
QMIX 论文解读
多智能体的相关工作
Dec-POMDP
去中心化的部分可观测马尔科夫模型(Decentralized partially observable Markov decision progress,DEC-POMDP),是研究不确定性情况下多主体协同决策的重要模型。
由于其求解难度是 NEXP-complete,迄今为止尚没有有效的算法能求出其最优解,但是可以用强化学习来近似求解。
在多智能体强化学习中一种比较典型的学习模式为中心式训练,分布式执行,即在训练时利用所共享的信息来帮助更有效的分布式执行。然而,围绕如何最好地利用集中培训仍然存在着许多挑战。
其中一个挑战是如何表示和使用大多数强化学习方法学习的动作值函数。一方面,正确地捕捉主体行为的影响,需要一个集中的行动价值函数,它决定了全球状态和联合行动的条件。
另一方面,当存在多个 agent 时,这样的函数很难学习,即使可以学习,也无法提供明显的方法来提取分散的策略,允许每个智能体根据单个观察结果选择单个操作。
DRQN
将 DQN 与 LSTM 结合,主要是讲全连接层换成 LSTM 等循环神经网络,使得 DQN 具备了学习长时间序列的能力
IQL(Independent Q-Learning)
IQL(independent Q-learning)就是非常暴力的给每个智能体执行一个Q-learning算法,因为共享环境,并且环境随着每个智能体策略、状态发生改变,对每个智能体来说,环境是动态不稳定的,因此这个算法也无法收敛,但是在部分应用中也具有较好的效果。
放弃学习中心式 Q t o t Q_{tot} Qtot而转去对每个智能体学习一个独立的$Q_a}。但是这个方法不能表现出智能体之间的互动,而且每个智能体的训练会被其他智能体的探索和学习干扰。
VDN(Value Decomposition Networks)
VDN(value decomposition networks)也是采用对每个智能体的值函数进行整合,得到一个联合动作值函数。VDN假设中心式的Qtot可以分解为各个Qa的线性相加。
令 τ = ( τ 1 , . . . , τ n ) \tau=(\tau_1,...,\tau_n) τ=(τ1,...,τn)表示联合动作-观测历史,其中 τ i = ( a i , 0 , o i , 0 , . . . , a i , t − 1 , o i , t − 1 ) \tau_i=(a_{i,0},o_{i,0},...,a_{i,t-1},o_{i,t-1}) τi=(ai,0,oi,0,...,ai,t−1,oi,t−1)为动作-观测历史, a = ( a 1 , . . . , a n ) a=(a_1,...,a_n) a=(a1,...,an)表示联合动作。
Q t o t Q_{tot} Qtot为联合动作值函数, Q ( τ i , a i ; θ i ) Q(\tau_i,a_i;\theta_i) Q(τi,ai;θi)为智能体i的局部动作值函数,局部值函数只依赖于每个智能体的局部观测。
VDN采用的方法就是直接相加求和的方式
Q t o t = ∑ i = 1 n Q ( τ i , a i ; θ i ) Q_{tot}=\sum_{i=1}^{n}Q(\tau_i,a_i;\theta_i) Qtot=∑i=1nQ(τi,ai;θi)
虽然 Q ( τ i , a i ; θ i ) Q(\tau_i,a_i;\theta_i) Q(τi,ai;θi)不是用来估计累积期望回报的,但是这里依然叫它为值函数。
分布式的策略可以通过对每个 Q ( τ i , a i ; θ i ) Q(\tau_i,a_i;\theta_i) Q(τi,ai;θi)取max得到。
VDN假设中心式的 Q t o t Q_{tot} Qtot可以分解为各个 Q a Q_a Qa的线性相加,而QMIX可以视为VDN的拓展
QMIX
QMIX 以视为 VDN 的拓展不同于上面两种方式,论文中提出学习一个中心式但可分解的 Q t o t Q_{tot} Qtot 即 QMIX,可以以集中、端到端的方式训练分散的策略。
QMIX 结构
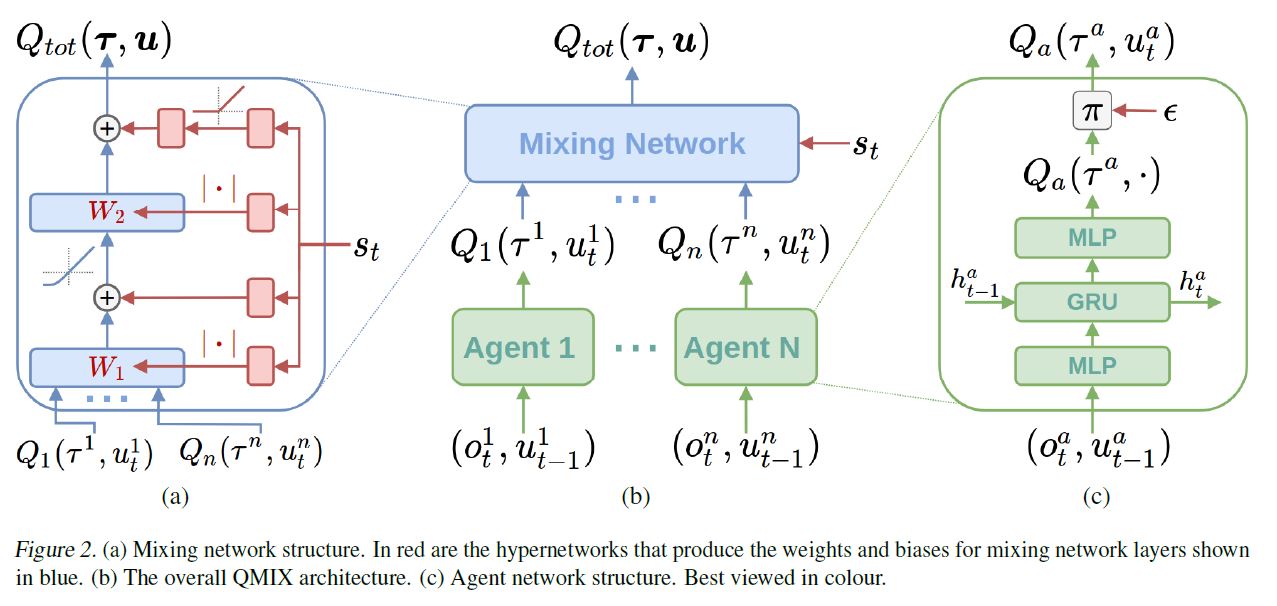
这是 QMIX 的模型结构,宏观的示意在图中,QMIX 由 agent 网络、Mixing 网络和一组 hypernetwork 超网络(由一个网络为另一个网络生成参数)组成的体系结构来表示 Q t o t Q_tot Qtot。
对于每一个智能体实现一个自己的 DRQN 网络,输入是自己的观察序列o和上一个动作u,计算得到自己的Q值,即图右。
Mixing 网络是一个前馈神经网络,接收所有的 Q a Q_a Qa,输出为 Q t o t Q_{tot} Qtot,为了满足单调性约束,混合网络的参数由单独的超参数网络生成,即图中左边红色方块,输入为全局状态信息,输出为混合网络的权重和偏置,权重需要满足大于等于0的要求,所以需要经过绝对值函数的激活层,当权重大于等于0时,才能满足最后的Qtot对于Qa的导数大于等于0。
核心——单调性约束
如果让能够评价整体策略优劣的中心式 Q t o t Q_{tot} Qtot对每个智能体取得的 Q a Q_a Qa的导数大于等于0
即 ∂ Q t o t ∂ Q a ≥ 0 \frac{\partial Q_{tot}}{\partial Q_{a}}\geq 0 ∂Qa∂Qtot≥0
如果满足上面的要求,求解最大化 Q t o t Q_{tot} Qtot等价于对每个 Q a Q_a Qa做最大化
这样做的好处:
- 求解 Q t o t Q_{tot} Qtot时更为方便,只需要对每个 Q a Q_a Qa做最大化即可
- 从 Q t o t Q_{tot} Qtot中可以显式地提取分布式执行的各个智能体的策略
在 aistudio 上运行 QMIX
在 PARL 的 example 中,同样有 QMIX 算法的实现与案例,感兴趣的童鞋可以参考一下
gitee:https://gitee.com/paddlepaddle/PARL/tree/develop/examples/qmix
github:https://github.com/PaddlePaddle/PARL/tree/develop/examples/qmix
环境准备
本文的项目地址(欢迎fork和star):
https://aistudio.baidu.com/aistudio/projectdetail/1698077
三个步骤:解压游戏的二进制文件、安装游戏接口与解压并放置地图
# 只解压一次
!unzip -P iagreetotheeula -q /home/aistudio/data/data72721/SC2.4.10.zip
# 重新启动环境时安装
!pip install git+https://gitee.com/wzduang/smac_copy.git
!mkdir StarCraftII/Maps
!unzip /home/aistudio/data/data76150/SMAC_Maps.zip
!mv SMAC_Maps StarCraftII/Maps
测试游戏环境
!python -m smac.examples.random_agents
QMIX 代码部分
执行部分
该部分采用了多线程,主要负责分布式地与环境进行交互,并通过管道将数据回传给训练部分
%%writefile runner.py
import qmix
from smac.env import StarCraft2Env
import numpy as np
import paddle
import paddle.nn.functional as F
from multiprocessing import Process, Lock, Pipe, Value
from threading import Thread
import time
class Transform:
def transform(self, tensor):
raise NotImplementedError
def infer_output_info(self, vshape_in, dtype_in):
raise NotImplementedError
class OneHot(Transform):
def __init__(self, out_dim):
self.out_dim = out_dim
def transform(self, tensor):
y_onehot = dense_to_onehot(tensor, num_classes=self.out_dim).squeeze()
return y_onehot.astype("float32")
def infer_output_info(self, vshape_in, dtype_in):
return (self.out_dim,), "float32"
def env_run(scenario, id, child_conn, locker, replay_buffer_size):
# 定义地图以及回放路径
env = StarCraft2Env(map_name=scenario, replay_dir="./replay/")
env_info = env.get_env_info()
# 进程 id
process_id = id
# 获取信息
action_n = env_info["n_actions"]
agent_nb = env_info["n_agents"]
state_shape = env_info["state_shape"]
obs_shape = env_info["obs_shape"] + agent_nb + action_n
#self.episode_limit = env_info['episode_limit']
agent_id_one_hot = OneHot(agent_nb)
actions_one_hot = OneHot(action_n)
agent_id_one_hot_array = []
for agent_id in range(agent_nb):
agent_id_one_hot_array.append(agent_id_one_hot.transform(np.array([agent_id])))
agent_id_one_hot_array = np.array(agent_id_one_hot_array)
actions_one_hot_reset = np.zeros((agent_nb, action_n), dtype="float32")
state_zeros = np.zeros(state_shape)
obs_zeros = np.zeros((agent_nb, obs_shape))
actions_zeros = np.zeros([agent_nb, 1])
reward_zeros = 0
agents_available_actions_zeros = np.zeros((agent_nb, action_n))
agents_available_actions_zeros[:,0] = 1
child_conn.send(id)
while True:
while True:
data = child_conn.recv()
if data == 'save':
env.save_replay()
child_conn.send('save ok.')
elif data == 'close':
env.close()
exit()
else:
break
locker.acquire()
env.reset()
locker.release()
episode_reward = 0
episode_step = 0
obs = np.array(env.get_obs())
obs = np.concatenate([obs, actions_one_hot_reset, agent_id_one_hot_array], axis=-1)
state = np.array(env.get_state())
terminated = False
while not terminated:
agents_available_actions = []
for agent_id in range(agent_nb):
agents_available_actions.append(env.get_avail_agent_actions(agent_id))
child_conn.send(["actions", obs, agents_available_actions])
actions = child_conn.recv()
reward, terminated, _ = env.step(actions)
agents_available_actions2 = []
for agent_id in range(agent_nb):
agents_available_actions2.append(env.get_avail_agent_actions(agent_id))
obs2 = np.array(env.get_obs())
actions_one_hot_agents = []
for action in actions:
actions_one_hot_agents.append(actions_one_hot.transform(np.array(action)))
actions_one_hot_agents = np.array(actions_one_hot_agents)
obs2 = np.concatenate([obs2, actions_one_hot_agents, agent_id_one_hot_array], axis=-1)
state2 = np.array(env.get_state())
child_conn.send(["replay_buffer", state, actions, [reward], [terminated], obs, agents_available_actions, 0])
episode_reward += reward
episode_step += 1
obs = obs2
state = state2
for _ in range(episode_step, replay_buffer_size):
child_conn.send(["actions", obs_zeros, agents_available_actions_zeros])
child_conn.send(["replay_buffer", state_zeros, actions_zeros, [reward_zeros], [True], obs_zeros, agents_available_actions_zeros, 1])
child_conn.recv()
child_conn.send(["episode_end", episode_reward, episode_step, env.win_counted])
class Runner:
def __init__(self, arglist, scenario, actors):
env = StarCraft2Env(map_name=scenario, replay_dir="./replay/")
env_info = env.get_env_info()
self.actors = actors
self.scenario = scenario
self.n_actions = env_info["n_actions"]
self.n_agents = env_info["n_agents"]
self.state_shape = env_info["state_shape"]
self.obs_shape = env_info["obs_shape"] + self.n_agents + self.n_actions
self.episode_limit = env_info['episode_limit']
self.qmix_algo = qmix.QMix(arglist.train, self.n_agents, self.obs_shape, self.state_shape, self.n_actions, 0.0005, replay_buffer_size=1000)
# 验证模式
if arglist.train == False:
self.qmix_algo.load_model('./saved/agents_' + str(arglist.load_episode_saved))
print('Load model agent ', str(arglist.load_episode_saved))
self.episode_global_step = 0
self.episode = 0
self.process_com = []
self.locker = Lock()
for idx in range(self.actors):
parent_conn, child_conn = Pipe()
Process(target=env_run, args=[self.scenario, idx, child_conn, self.locker, self.episode_limit]).start()
self.process_com.append(parent_conn)
for process_conn in self.process_com:
process_id = process_conn.recv()
print(process_id, " is ready !")
pass
def reset(self):
self.qmix_algo.on_reset(self.actors)
self.episodes = []
self.episode_reward = []
self.episode_step = []
self.replay_buffers = []
self.win_counted_array = []
episode_managed = self.episode
for _ in range(self.actors):
self.episodes.append(episode_managed)
self.episode_reward.append(0)
self.episode_step.append(0)
self.win_counted_array.append(False)
self.replay_buffers.append(qmix.ReplayBuffer(self.episode_limit))
episode_managed += 1
for process_conn in self.process_com:
process_conn.send("Go !")
def run(self):
episode_done = 0
process_size = len(self.process_com)
available_to_send = np.array([True for _ in range(self.actors)])
while True:
obs_batch = []
available_batch = []
actions = None
for idx, process_conn in enumerate(self.process_com):
data = process_conn.recv()
if data[0] == "actions":
obs_batch.append(data[1])
available_batch.append(data[2])
if idx == process_size - 1:
obs_batch = np.concatenate(obs_batch, axis=0)
available_batch = np.concatenate(available_batch, axis=0)
actions = self.qmix_algo.act(self.actors, paddle.to_tensor(obs_batch), paddle.to_tensor(available_batch))
elif data[0] == "replay_buffer":
self.replay_buffers[idx].add(data[1], data[2], data[3], data[4], data[5], data[6], data[7])
elif data[0] == "episode_end":
self.episode_reward[idx] = data[1]
self.episode_step[idx] = data[2]
self.win_counted_array[idx] = data[3]
available_to_send[idx] = False
episode_done += 1
if actions is not None:
for idx_proc, process in enumerate(self.process_com):
if available_to_send[idx_proc]:
process.send(actions[idx_proc])
if episode_done >= self.actors:
break
self.episode += self.actors
self.episode_global_step += max(self.episode_step)
self.qmix_algo.decay_epsilon_greddy(self.episode_global_step)
return self.replay_buffers
def save(self):
for process in self.process_com:
process.send('save')
data = process.recv()
print(data)
def close(self):
for process in self.process_com:
process.send('close')
def dense_to_onehot(labels_dense, num_classes=10):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_onehot = np.zeros((num_labels,num_classes))
# 展平的索引值对应相加,然后得到精确索引并修改 labels_onehot 中的每一个值
labels_onehot.flat[index_offset + labels_dense.ravel()] = 1
return labels_onehot
Overwriting runner.py
定义 agent 网络结构
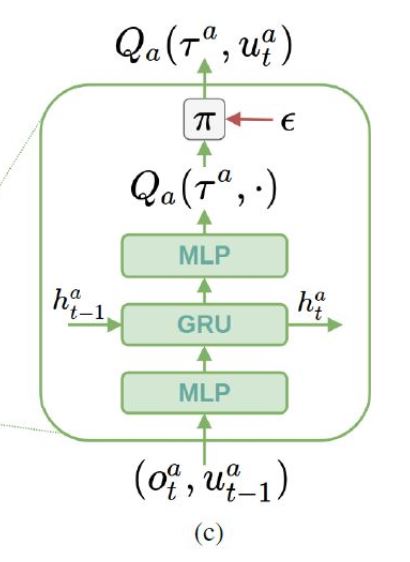
%%writefile rnn_agent.py
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class RNNAgent(nn.Layer):
def __init__(self, input_shape, rnn_hidden_dim=64, n_actions=1):
super(RNNAgent, self).__init__()
self.rnn_hidden_dim = rnn_hidden_dim
print('input_shape: ', input_shape)
self.fc1 = nn.Linear(input_shape, rnn_hidden_dim)
self.rnn = nn.GRUCell(rnn_hidden_dim, rnn_hidden_dim)
self.fc2 = nn.Linear(rnn_hidden_dim, n_actions)
def init_hidden(self):
return paddle.zeros([1, self.rnn_hidden_dim])
def forward(self, inputs, hidden_state):
x = F.relu(self.fc1(inputs))
h_in = hidden_state.reshape([-1, self.rnn_hidden_dim])
h, _ = self.rnn(x, h_in)
q = self.fc2(h)
return q, h
def update(self, agent):
self.load_dict(agent.state_dict())
Overwriting rnn_agent.py
Mixing 网络定义
%%writefile qmixer.py
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import numpy as np
class QMixer(nn.Layer):
def __init__(self, n_agents, state_shape, mixing_embed_dim=64):
super(QMixer, self).__init__()
self.n_agents = n_agents
self.state_dim = int(np.prod(state_shape))
self.embed_dim = mixing_embed_dim
self.hyper_w_1 = nn.Linear(self.state_dim, self.embed_dim * self.n_agents)
self.hyper_w_final = nn.Linear(self.state_dim, self.embed_dim)
# 隐藏层的偏置
self.hyper_b_1 = nn.Linear(self.state_dim, self.embed_dim)
# 最后一层的 V(s)
self.V = nn.Sequential(nn.Linear(self.state_dim, self.embed_dim),
nn.ReLU(),
nn.Linear(self.embed_dim, 1))
def forward(self, agent_qs, states):
bs = agent_qs.shape[0]
states = states.reshape([-1, self.state_dim])
agent_qs = agent_qs.reshape([-1, 1, self.n_agents])
# First layer
w1 = paddle.abs(self.hyper_w_1(states))
b1 = self.hyper_b_1(states)
w1 = w1.reshape([-1, self.n_agents, self.embed_dim])
b1 = b1.reshape([-1, 1, self.embed_dim])
hidden = F.elu(paddle.bmm(agent_qs, w1) + b1)
# Second layer
w_final = paddle.abs(self.hyper_w_final(states))
w_final = w_final.reshape([-1, self.embed_dim, 1])
# State-dependent bias
v = self.V(states).reshape([-1, 1, 1])
# Compute final output
y = paddle.bmm(hidden, w_final) + v
# Reshape and return
q_tot = y.reshape([bs, -1, 1])
return q_tot
def update(self, agent):
self.load_dict(agent.state_dict())
Overwriting qmixer.py
策略与训练部分
包括 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 探索,经验回放与 Qmix agent 主体
%%writefile qmix.py
import rnn_agent
import qmixer
import paddle
import paddle.nn.functional as F
from paddle.distribution import Categorical
import numpy as np
import random
from collections import deque
# 探索
class EpsilonGreedy:
def __init__(self, action_nb, agent_nb, final_step, epsilon_start=float(1), epsilon_end=0.05):
self.epsilon = epsilon_start
self.initial_epsilon = epsilon_start
self.epsilon_end = epsilon_end
self.action_nb = action_nb
self.final_step = final_step
self.agent_nb = agent_nb
def act(self, value_action, avail_actions):
if np.random.random() > self.epsilon:
action = value_action.argmax(axis=-1).detach().numpy()
else:
action = Categorical(avail_actions.cast("float32")).sample([1]).squeeze().cast("int64").detach().numpy()
return action
def epislon_decay(self, step):
progress = step / self.final_step
decay = self.initial_epsilon - progress
if decay <= self.epsilon_end:
decay = self.epsilon_end
self.epsilon = decay
# 经验回放
class ReplayBuffer(object):
def __init__(self, buffer_size, random_seed=314):
"""
The right side of the deque contains the most recent experiences
"""
self.buffer_size = buffer_size
self.count = 0
self.buffer = deque()
def add(self, s, a, r, t, obs, available_actions, filled):
experience = [s, a, r, t, obs, available_actions, np.array([filled])]
if self.count < self.buffer_size:
self.buffer.append(experience)
self.count += 1
else:
self.buffer.popleft()
self.buffer.append(experience)
def size(self):
return self.count
def sample_batch(self, batch_size):
batch = []
for idx in range(batch_size):
batch.append(self.buffer[idx])
batch = np.array(batch)
s_batch = np.array([_[0] for _ in batch], dtype='float32')
a_batch = np.array([_[1] for _ in batch], dtype='float32')
r_batch = np.array([_[2] for _ in batch])
t_batch = np.array([_[3] for _ in batch])
obs_batch = np.array([_[4] for _ in batch], dtype='float32')
available_actions_batch = np.array([_[5] for _ in batch], dtype='float32')
filled_batch = np.array([_[6] for _ in batch], dtype='float32')
return s_batch, a_batch, r_batch, t_batch, obs_batch, available_actions_batch, filled_batch
def clear(self):
self.buffer.clear()
self.count = 0
# 批量采样
class EpisodeBatch:
def __init__(self, buffer_size, random_seed=314):
self.buffer_size = buffer_size
self.count = 0
self.buffer = deque()
def reset(self):
pass
def add(self, replay_buffer):
if self.count < self.buffer_size:
self.buffer.append(replay_buffer)
self.count += 1
else:
self.buffer.popleft()
self.buffer.append(replay_buffer)
def _get_max_episode_len(self, batch):
max_episode_len = 0
for replay_buffer in batch:
_, _, _, t, _, _, _ = replay_buffer.sample_batch(replay_buffer.size())
for idx, t_idx in enumerate(t):
if t_idx == True:
if idx > max_episode_len:
max_episode_len = idx + 1
break
return max_episode_len
def sample_batch(self, batch_size):
batch = []
if self.count < batch_size:
batch = random.sample(self.buffer, self.count)
else:
batch = random.sample(self.buffer, batch_size)
episode_len = self._get_max_episode_len(batch)
s_batch, a_batch, r_batch, t_batch, obs_batch, available_actions_batch, filled_batch = [], [], [], [], [], [], []
for replay_buffer in batch:
s, a, r, t, obs, available_actions, filled = replay_buffer.sample_batch(episode_len)
s_batch.append(s)
a_batch.append(a)
r_batch.append(r)
t_batch.append(t)
obs_batch.append(obs)
available_actions_batch.append(available_actions)
filled_batch.append(filled)
filled_batch = np.array(filled_batch)
r_batch = np.array(r_batch)
t_batch = np.array(t_batch)
a_batch = np.array(a_batch)
obs_batch = np.array(obs_batch)
available_actions_batch = np.array(available_actions_batch)
return s_batch, a_batch, r_batch, t_batch, obs_batch, available_actions_batch, filled_batch, episode_len
def size(self):
return self.count
# Qmix agent
class QMix:
def __init__(self, training, agent_nb, obs_shape, states_shape, action_n, lr, gamma=0.99, batch_size=32, replay_buffer_size=10000, update_target_network=200, final_step=50000): #32
self.training = training
self.gamma = gamma
self.batch_size = batch_size
self.update_target_network = update_target_network
self.hidden_states = None
self.target_hidden_states = None
self.agent_nb = agent_nb
self.action_n = action_n
self.state_shape = states_shape
self.obs_shape = obs_shape
self.epsilon_greedy = EpsilonGreedy(action_n, agent_nb, final_step)
self.episode_batch = EpisodeBatch(replay_buffer_size)
self.agents = rnn_agent.RNNAgent(obs_shape, n_actions=action_n)
self.target_agents = rnn_agent.RNNAgent(obs_shape, n_actions=action_n)
self.qmixer = qmixer.QMixer(agent_nb, states_shape, mixing_embed_dim=32)
self.target_qmixer = qmixer.QMixer(agent_nb, states_shape, mixing_embed_dim=32)
self.target_agents.update(self.agents)
self.target_qmixer.update(self.qmixer)
self.params = list(self.agents.parameters())
self.params += self.qmixer.parameters()
clip_grad = paddle.nn.ClipGradByNorm(clip_norm=10)
self.optimizer = paddle.optimizer.RMSProp(parameters=self.params, learning_rate=lr, rho=0.99, epsilon=0.00001, grad_clip=clip_grad)
def save_model(self, filename):
paddle.save(self.agents.state_dict(), filename)
def load_model(self, filename):
self.agents.load_dict(paddle.load(filename))
self.agents.eval()
def _init_hidden_states(self, batch_size):
self.hidden_states = self.agents.init_hidden().unsqueeze(0).expand([batch_size, self.agent_nb, -1])
self.target_hidden_states = self.target_agents.init_hidden().unsqueeze(0).expand([batch_size, self.agent_nb, -1])
def decay_epsilon_greddy(self, global_steps):
self.epsilon_greedy.epislon_decay(global_steps)
def on_reset(self, batch_size):
self._init_hidden_states(batch_size)
def update_targets(self, episode):
if episode % self.update_target_network == 0 and self.training:
self.target_agents.update(self.agents)
self.target_qmixer.update(self.qmixer)
pass
def train(self):
if self.training and self.episode_batch.size() > self.batch_size:
for _ in range(2):
self._init_hidden_states(self.batch_size)
s_batch, a_batch, r_batch, t_batch, obs_batch, available_actions_batch, filled_batch, episode_len = self.episode_batch.sample_batch(self.batch_size)
r_batch = r_batch[:, :-1]
a_batch = a_batch[:, :-1]
t_batch = t_batch[:, :-1]
filled_batch = filled_batch[:, :-1]
mask = (1 - filled_batch) * (1 - t_batch)
r_batch = paddle.to_tensor(r_batch, dtype="float32")
t_batch = paddle.to_tensor(t_batch, dtype="float32")
mask = paddle.to_tensor(mask, dtype="float32")
a_batch = paddle.to_tensor(a_batch, dtype="int64")
mac_out = []
for t in range(episode_len):
obs = obs_batch[:, t]
obs = np.concatenate(obs, axis=0)
obs = paddle.to_tensor(obs, dtype="float32")
agent_actions, self.hidden_states = self.agents(obs, self.hidden_states)
agent_actions = agent_actions.reshape([self.batch_size, self.agent_nb, -1])
mac_out.append(agent_actions)
mac_out = paddle.stack(mac_out, axis=1)
_a_batch = F.one_hot(a_batch.detach(), mac_out[:, :-1].shape[-1]).squeeze(-2)
chosen_action_qvals = mac_out[:, :-1]
chosen_action_qvals = chosen_action_qvals.multiply(_a_batch).sum(-1)
target_mac_out = []
for t in range(episode_len):
obs = obs_batch[:, t]
obs = np.concatenate(obs, axis=0)
obs = paddle.to_tensor(obs, dtype="float32")
agent_actions, self.target_hidden_states = self.target_agents(obs, self.target_hidden_states)
agent_actions = agent_actions.reshape([self.batch_size, self.agent_nb, -1])
target_mac_out.append(agent_actions)
target_mac_out = paddle.stack(target_mac_out[1:], axis=1)
available_actions_batch = paddle.to_tensor(available_actions_batch)
_condition_ = paddle.zeros(target_mac_out.shape)
_condition_ = _condition_ - 9999999
target_mac_out = paddle.where(available_actions_batch[:, 1:] == 0, _condition_, target_mac_out)
target_max_qvals = target_mac_out.max(axis=3)
states = paddle.to_tensor(s_batch, dtype="float32")
chosen_action_qvals = self.qmixer(chosen_action_qvals, states[:, :-1])
target_max_qvals = self.target_qmixer(target_max_qvals, states[:, 1:])
yi = r_batch + self.gamma * (1 - t_batch) * target_max_qvals
td_error = (chosen_action_qvals - yi.detach())
mask = mask.expand_as(td_error)
masked_td_error = td_error * mask
loss = (masked_td_error ** 2).sum() / mask.sum()
print('loss:', loss.numpy().item())
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
def act(self, batch, obs, agents_available_actions):
value_action, self.hidden_states = self.agents(paddle.to_tensor(obs, dtype="float32"), self.hidden_states)
condition = paddle.zeros(value_action.shape)
condition = condition - int(1e10)
value_action = paddle.where(agents_available_actions == 0, condition, value_action)
if self.training:
value_action = self.epsilon_greedy.act(value_action, agents_available_actions)
else:
value_action = np.argmax(value_action.numpy(), -1)
value_action = value_action.reshape([batch, self.agent_nb, -1])
return value_action
Overwriting qmix.py
主函数部分(负责定义与调度)
训练时使用
python main.py --train
验证时
python main.py --load-episode-saved xxx --scenario xxx
分别代表加载的模型编号与地图名
%%writefile main.py
from smac.env import StarCraft2Env
import numpy as np
import qmix
import paddle
import os
import argparse
from time import gmtime, strftime
from visualdl import LogWriter
import runner
def main(arglist):
# 用于保存
max_reward = 15
current_time = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
writer = LogWriter(log_dir='./logs/' + current_time + '-snake', comment= "Star Craft II")
# 线程数
actors = 15
if arglist.train == False:
actors = 1
env_runner = runner.Runner(arglist, arglist.scenario, actors)
while arglist.train or env_runner.episode < 1:
env_runner.reset()
replay_buffers = env_runner.run()
for replay_buffer in replay_buffers:
env_runner.qmix_algo.episode_batch.add(replay_buffer)
env_runner.qmix_algo.train()
for episode in env_runner.episodes:
env_runner.qmix_algo.update_targets(episode)
for idx, episode in enumerate(env_runner.episodes):
if episode % int(1e6) == 0 and arglist.train:
env_runner.qmix_algo.save_model('./saved/agents_' + str(episode))
if env_runner.episode_reward[idx] >= max_reward:
max_reward = env_runner.episode_reward[idx]
env_runner.qmix_algo.save_model('./saved/agents_reward_'+ str(env_runner.episode_reward[idx]) + "_" + str(episode))
pass
print(env_runner.win_counted_array)
for idx, episode in enumerate(env_runner.episodes):
print("Total reward in episode {} = {} and global step: {}".format(episode, env_runner.episode_reward[idx], env_runner.episode_global_step))
if arglist.train:
writer.add_scalar('Reward', paddle.to_tensor(env_runner.episode_reward[idx]), episode)
writer.add_scalar('Victory', paddle.to_tensor(env_runner.win_counted_array[idx]), episode)
if arglist.train == False:
env_runner.save()
env_runner.close()
def parse_args():
parser = argparse.ArgumentParser('SCII parser for QMIX')
parser.add_argument('--train', action='store_true')
parser.add_argument('--load-episode-saved', type=int, default=105500)
parser.add_argument('--scenario', type=str, default="6h_vs_8z")
return parser.parse_args()
if __name__ == "__main__":
try:
os.mkdir('./saved')
except OSError:
print ("Creation of the directory failed")
else:
print ("Successfully created the directory")
arglist = parse_args()
main(arglist)
Overwriting main.py
开始训练
建议使用 visual 打开 run 文件夹进行训练曲线的监测,当训练收敛并稳定时(指 reward 达到最高的 20 左右),手动终止训练
!python main.py --train
训练效果
8 枪兵 vs 8 枪兵
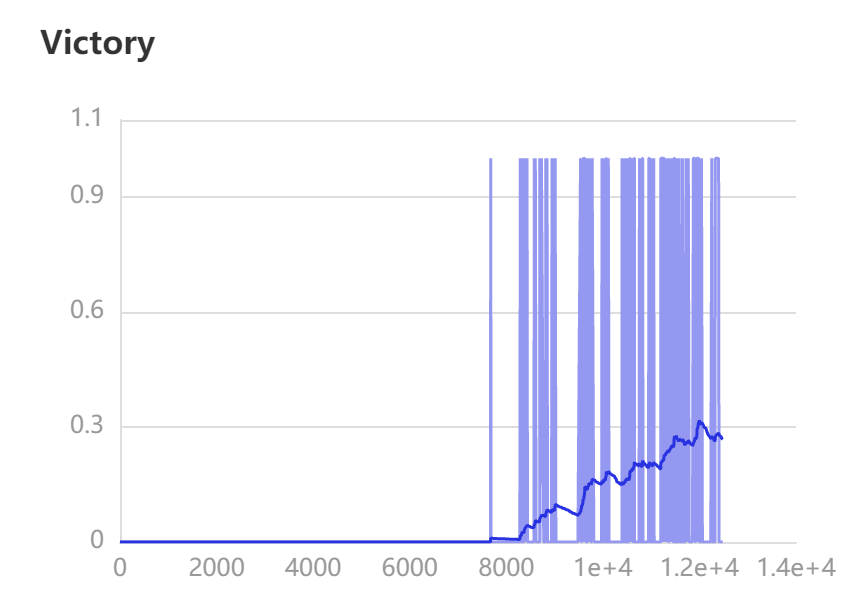 # 训练效果展示
# 训练效果展示
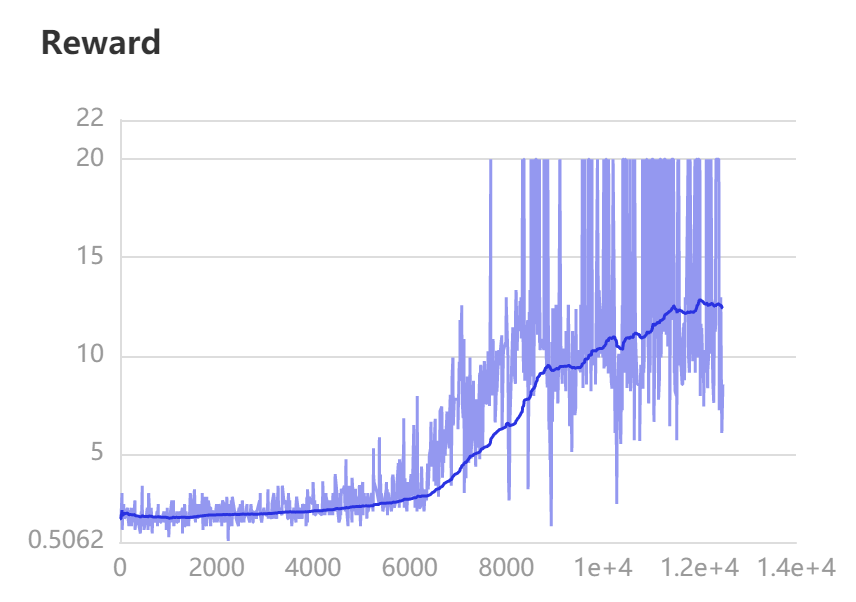
结果可视化
安装星际争霸II,打开回放文件,就可以直接查看完整过程了
这里放出我训练的效果
用QMIX玩星际争霸(枪兵8v8)
个人简介
姓名:王子瑞
四川大学本科2018级电气工程学院自动化专业在读
感兴趣的方向:游戏AI(不完美信息博弈与深度增强学习),机器人应用,视觉SLAM,视觉深度学习
目前主要学习方向:自动控制算法,传统图像处理,强化学习,轻量化模型与边缘设备部署
AgentMaker 代码仓库:https://github.com/AgentMaker

















 8603
8603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









