






 本文介绍了QMIX模型,一种针对VDN在多智能体强化学习中局限性的改进方法。QMIX通过考虑个体和全局状态,设计了混合网络和超网络结构,确保Qtot与每个智能体的Q值正相关,从而提升决策质量。实验结果展示了QMIX在StarCraftII环境中的协作性能提升。
本文介绍了QMIX模型,一种针对VDN在多智能体强化学习中局限性的改进方法。QMIX通过考虑个体和全局状态,设计了混合网络和超网络结构,确保Qtot与每个智能体的Q值正相关,从而提升决策质量。实验结果展示了QMIX在StarCraftII环境中的协作性能提升。
论文链接:QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning (mlr.press)
代码参考:Welcome to XuanCe’s documentation! — XuanCe v1.0 documentation
动机
主要是面对VDN的几个缺陷:
1.通过简单地将各智能体的个体价值函数相加来近似总体动作价值函数,这种方法限制了它能表示的动作价值函数的复杂度。
2.VDN没有利用训练时可用的额外全局状态信息s,这可能导致在需要这些信息以提高决策质量的环境中性能受限。
VDN的全局Q值只是线性相加:
但简单的线性组合并不能很好的拟合Qtot,可能需要复杂的非线性组合智能体的价值函数来扩展可表示的动作价值函数的类别。Qmix的设计理念基于这个式子:
τ是个体观测轨迹,ui是个体动作。Qmix假设如果每个智能体都选择使得自己个体Q最大的动作,那么这些动作的组合将会是使得整个系统的Qtot最大的动作组合。
这个假设只用满足这个前提即可,那就是Qtot和每个智能体的Q正相关:
这样的情况下,个体Q同时最大时一定有Qtot最大。
模型结构
基于上面的假设,Qmix最后的网络结构:
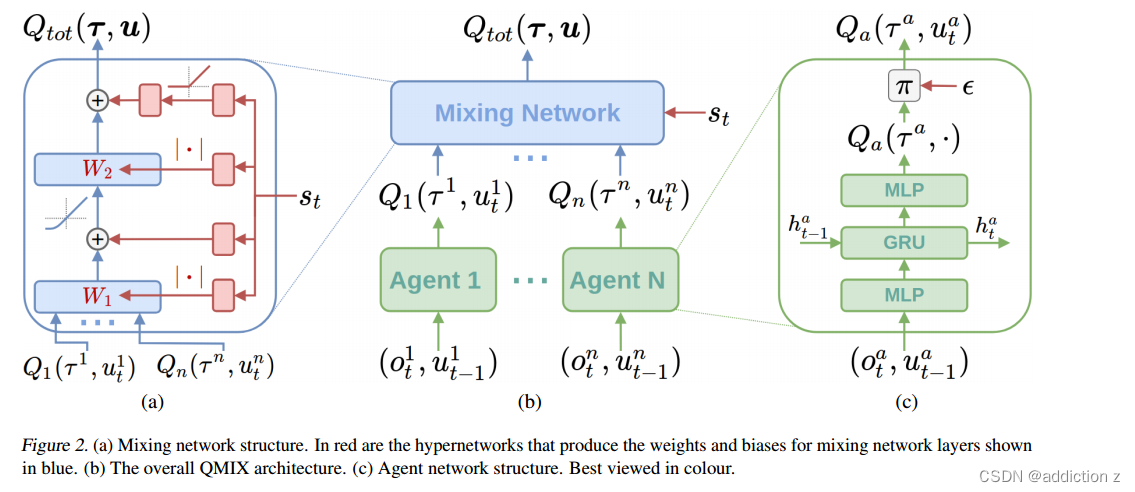 总共有三种网络:
总共有三种网络:
1.智能体网络:采用MLP-GRU-MLP的结构,GRU用于处理时间序列。
2.混合网络:用于将输入的Q值混合成Qtot
3.超网络:用于学习混合网络的权重和偏置
这是混合网络的结构:
class QMIX_mixer(nn.Module):
def __init__(self, dim_state, dim_hidden, dim_hypernet_hidden, n_agents, device):
super(QMIX_mixer, self).__init__()
self.device = device
self.dim_state = dim_state
self.dim_hidden = dim_hidden
self.dim_hypernet_hidden = dim_hypernet_hidden
self.n_agents = n_agents
self.hyper_w_1 = nn.Sequential(nn.Linear(self.dim_state, self.dim_hypernet_hidden),
nn.ReLU(),
nn.Linear(self.dim_hypernet_hidden, self.dim_hidden * self.n_agents)).to(device)#第一层权重超网
self.hyper_w_2 = nn.Sequential(nn.Linear(self.dim_state, self.dim_hypernet_hidden),
nn.ReLU(),
nn.Linear(self.dim_hypernet_hidden, self.dim_hidden)).to(device)#第二层权重超网
self.hyper_b_1 = nn.Linear(self.dim_state, self.dim_hidden).to(device)#第一层偏置超网
self.hyper_b_2 = nn.Sequential(nn.Linear(self.dim_state, self.dim_hypernet_hidden),
nn.ReLU(),
nn.Linear(self.dim_hypernet_hidden, 1)).to(device)
#第二层偏置超网
def forward(self, values_n, states):
states = torch.as_tensor(states, dtype=torch.float32, device=self.device)
states = states.reshape(-1, self.dim_state)
agent_qs = values_n.reshape(-1, 1, self.n_agents)
# First layer
w_1 = torch.abs(self.hyper_w_1(states))
w_1 = w_1.view(-1, self.n_agents, self.dim_hidden)
b_1 = self.hyper_b_1(states)
b_1 = b_1.view(-1, 1, self.dim_hidden)
hidden = F.elu(torch.bmm(agent_qs, w_1) + b_1)#批量矩阵乘法
# Second layer
w_2 = torch.abs(self.hyper_w_2(states))
w_2 = w_2.view(-1, self.dim_hidden, 1)
b_2 = self.hyper_b_2(states)
b_2 = b_2.view(-1, 1, 1)
# Compute final output
y = torch.bmm(hidden, w_2) + b_2
# Reshape and return
q_tot = y.view(-1, 1)
return q_tot算权重的时候的第二层加了一个ReLU函数,把定义域为负的部分修正了。使得Qtot关于每个Q总是正相关的
由链式法则有:
由ReLU的导数有:,而且W1和W2的计算都经过了abs层,所以此处W1>0,W2>0,该式严格大于0,所以Qtot和Q值正相关成立。
网络训练:
智能体网络,混合网络,超网络的参数都采用该式:
训练过程除了加的超网以及混合网络,其余和VDN基本相同。
实验:
找到xuance库的examples文件夹,找到qmix,想跑环境的yaml里改参数,parallel是并行环境数量,内存大的可以多设,不然设成2到4就好不然容易爆内存。benchmark模式是训练-测试-训练-测试-训练...模式,run则是只训练或者只测试。想看运行video的话,benchmark模式下把render改成True,或run模式下render和test_mode均设为True。最后运行qmix_sc2.py就好了。
跑的starcraft2的环境。这个游戏有这样几种角色:
c:Colossus(巨像) m:Marines(海军陆战队员) s: Stalkers(追猎者) z:Zealots(狂热者)他们需要协作击败敌人。
实验的结果:(如3m就是3个海军陆战队员)

自上而下为3m环境下训练0step,50000step,100000step的表现,可以看到经过训练,友军已经可以在无伤亡的情况下击败敌军了。




















 6900
6900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









