







| 基于用户(项目)协同过滤
输入:训练集用户列表U,训练集电影列表I,评分矩阵R,邻居数目K,测试集用户列表UT 输出:给每位用户(共计N位用户)产生一个推荐列表,其中包含M部电影
|
| UCF: Start: //构建用户相似度矩阵 For user For query Calculate sim(ux,uy) End for End for
//使用计算好的用户相似度 构建用户相似度矩阵SM //推荐流程 For user and //找到用户向量 Forming user vector with each row of R expressing the watching list of user , containing movies //选择K位邻居 Select K users as the neighbors of with whose is bigger than other inSM //每位邻居都有一些电影想推荐出去 For neighbor-user //每位邻居对某个待推荐电影的评分 For movie and Calculate End for End for //推荐预测评分最大的几个电影 Select M movies whose End for End
|

一般问题:
问:矩阵太大放不下怎么办?
答:可以使用其他数据结构来模拟一个矩阵,这些结构获得的空间比矩阵大得多,如hashtable,list。虽然这些结构都是一维的,但是通过互相嵌套,可以存放二维空间的数据。如下面的代码
| Int64 userid, itemid ;//用户id,电影id int rate;//用户对电影的评分,和上面的两个id应该以一个结构体的形式一起出现,为了方便写成了三个分离的数字 Hashtable h_matrix=new Hashtable();//用户-电影评分矩阵 Void store_to_hashtable(userid, itemid, rate, h_matrix)//将某个用户对某个电影的评分写入哈希表 { If(h_matrix.containskeys(userid))//如果矩阵中已经有了这个用户的部分评分记录 { Hashtable temp_row=(hashtable) h_matrix[userid];//读取这些记录 If(temp_row.containskey(itemid))//如果矩阵中已经记录了这个用户对这个电影的评分 { temp_row.remove(itemid); temp_row.add(itemid,rate); //重置评分,或者什么都不做也可以 } Else//如果没有这个用户对这个电影的评分 { temp_row.add(itemid,rate);//将评分写到哈希表中 } } Else//如果没有这个用户的评分记录 { Hashtable temp_row= new Hashtable(); temp_row.add(item,rate);//新建这个用户的针对这个电影的评分记录 h_matrix.add(a,temp_row);//新建这个用户的评分记录 } } |
用上面的方法可以实现大矩阵的存储,当我们需要找到某一行某一列的元素时,需要先锁定行对应的userid的key值,将这个key值对应的value放到一个temp的hashtable上,再查找列对应的itemed的key值,这个key值对应的就是评分了。
1. 数据存储
a) 采用Hashtable存储数据,程序中文件位置
String fileTrain="E:\\dataSet\\u1train.base"; //训练集
StringfileTest="E:\\dataSet\\u1test.test"; //测试集
可以根据需要更改。
b) 采用倒排的处理方法

大写字母表示user,小写字母表示movie item.
2. 相似度计算(余弦相似度方法)
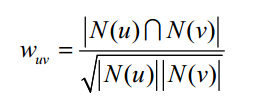
3. 评测指标
a) 召回率
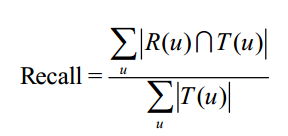
b) 准确率
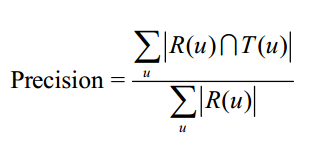
上述指标中
R(u):对用户u推荐N个物品
T(u):用户u在测试集上喜欢的物品集合
参考资料:















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









