








一、Cox比例风险回归简介
Cox比例风险回归模型(Cox’s proportional hazards regression model),简称Cox回归模型,由英国统计学家D.R.Cox于1972年提出,主要用于肿瘤和其它慢性病的预后分析,也可用于队列研究的病因探索。
1. 基本概念
- 生存函数:又称累计生存率,简称生存率,常用S(t)表示。代表被观察对象的生存时间大于t时刻的概率,实际中t时刻的取值估算公式为:S(t) ≈ 生存时间长于t的患者数 / 患者总数
- 死亡概率函数:简称为死亡概率,常用F(t)表示。代表一个被观察对象从开始观察到时间t为止的死亡概率,它与生存函数的关系为:F(t) = 1 - S(t)。
- 死亡密度函数:简称为密度函数,用f(t)表示。代表所有被观察对象在t时刻的瞬时死亡率。
- 风险函数:即生存时间已达到t的一群被观察对象在t时刻的瞬时死亡率,用h(t)表示。代表已存活到时间t的每个观察对象从t到t+∆t这一非常小的区间内死亡的概率极限,它与生存函数、死亡密度函数的关系为:h(t) = f(t) / S(t)。
2. Cox回归模型结构
Cox回归模型不直接考察生存函数与协变量(影响因素)的关系,而是用风险函数作为因变量。设有n名病人(i=1,2,...,n),第i名病人的生存时间为 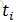
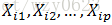
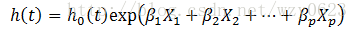
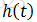

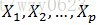
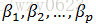
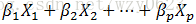
- 回归系数
时,协变量的取值越大,风险函数
的值越大,表示病人死亡的风险越大。
- 回归系数
时,表示协变量对风险函数
没有影响。
- 回归系数
时,协变量的取值越大,风险函数
的值越小,表示病人死亡的风险越小。
3. Cox回归模型的前提条件
Cox回归模型必须满足比例风险假设(Proportional Hazards Assumption,PHA):
(1)任何两个个体的风险函数之比,即风险比(HazardRatio,HR)保持一个恒定的比例,而与时间t无关。
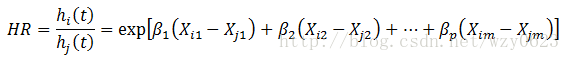
(2)模型中协变量的效应不随时间改变而改变。
检查某协变量是否满足PHA,最简单的方法是观察该变量分组的生存曲线。若生存曲线交叉,表示不满足PHA,此时可采用分层比例风险模型。
4. 参数估算与假设检验
Cox回归的参数估计同逻辑回归分析一样采用最大似然估计法。其基本思想是先建立偏似然函数或对数偏似然函数,求偏似然函数或对数偏似然函数达到极大时参数的取值,即为参数的最大似然估计值。
假设检验的方法有时协变量法、线性相关检验法、加权残差Score法等。这三种检验法有较高的准确率,且三种方法的检验效能相近。MADlib的Cox模型PHA检验函数使用线性相关检验法实现。
5. Cox模型的注意事项
- 研究的协变量在被研究对象中的分布要适中,否则会给回归参数的估计带来困难。
- Cox模型应用较灵活,被观察对象进入研究队列的早晚、时间长短可以不一致,但如果研究的变量随时间而变化,可以采用时依协变量模型进行分析。
- 样本含量不宜过小,一般应在40例以上,经验上的做法是样本含量为协变量个数的5-20倍。
- 尽管可以分析删失数据,但在观察时,要尽量避免观察对象的失访,过多失访容易造成结果的偏倚。
- Cox模型对异常值较为敏感,所以在进行模型拟合时要注意拟合优度的检验。
二、MADlib中Cox比例风险回归相关函数
1. 训练函数
(1) 语法
coxph_train( source_table,
output_table,
dependent_variable,
independent_variable,
right_censoring_status,
strata,
optimizer_params
) (2) 参数
参数名称 | 数据类型 | 描述 |
source_table | VARCHAR | 包含训练数据的源表名。 |
output_table | VARCHAR | 保存模型的输出表名,主输出表列和概要输出表列分别如表2、表3所示。 |
dependent_variable | VARCHAR | 因变量名称,指死亡时间,不需要对数据进行预排序。 |
independent_variable | VARCHAR | 自变量名称数组。 |
right_censoring_status(可选) | VARCHAR | 缺省值为TRUE。表示右删失状态的字符串,如果无删失则为TRUE,否则为FALSE。该参数可以包含是右删失状态的列名,或者是一个可以对每个观察值进行评估的布尔表达式,如‘column_name < 10’。 |
strata(可选) | VARCHAR | 缺省值为NULL,不做任何分层,可以是逗号分隔的列名。 |
optimizer_params(可选) | VARCHAR | 缺省值为NULL,此时使用缺省的优化参数:max_iter=100, optimizer=newton, tolerance=1e-8, array_agg_size=10000000, sample_size=1000000。应该是一个逗号分隔的‘key=value’字符串,参数含义如下: l max_iter:最大迭代数。如果迭代次数达到此数值则停止计算,这通常意味着无法收敛。 l optimizer:优化方法,当前仅支持‘newton’。 l tolerance:停止条件。当连续两次迭代的对数似然值之差小于此参数,计算已经收敛并停止。 l array_agg_size:为了加速计算,将原始数据表切分成多个数据片,每片数据聚合成一个大行。计算处理时,整个大行被导入内存以提高运算速度。此参数控制一个大行中包含多少数据,参数值越大速度越快,但由于PostgreSQL数据库的限制,一个大行的大小不能超过1G。 l sample_size:为了将数据切分成大致相等的片,先进行数据采样,然后利用采样数据找出断点。该参数值越大,产生的断点越精确。 |
表1 coxph_train函数参数说明
列名 | 数据类型 | 描述 |
Coef | FLOAT8[] | 回归系数向量。 |
loglikelihood | FLOAT8 | 极大似然估计的对数似然值。 |
std_err | FLOAT8[] | 回归系数标准差向量。 |
stats | FLOAT8[] | 回归系数统计向量。 |
p_values | FLOAT8[] | 回归系数p值向量。 |
hessian | FLOAT8[] | Hessian矩阵。 |
num_iterations | INTEGER | 优化器执行的迭代次数。 |
表2 coxph_train函数主输出表列说明
训练函数在产生输出表的同时,还会创建一个名为<output_table>_summary的概要表,具有以下列:
列名 | 数据类型 | 描述 |
method | VARCHAR | 'coxph',描述模型的字符串。 |
source_table | VARCHAR | 源表名。 |
out_table | VARCHAR | 模型表名。 |
dependent_varname | VARCHAR | 因变量表达式。 |
independent_varname | VARCHAR | 自变量表达式。 |
right_censoring_status | VARCHAR | 右删失状态。 |
Strata | VARCHAR | 分层列。 |
num_processed | INTEGER | 处理行数。 |
num_missing_rows_skipped | INTEGER | 跳过行数。 |
表3 coxph_train函数概要输出表列说明
2. 比例风险假设检验函数
cox_zph()函数检验Cox回归的比例风险假设,它通过计算coxph_train()输出模型中残差与时间的相关性验证比例风险假设。
(1) 语法
cox_zph(cox_model_table, output_table)(2) 参数
- cox_model_table:TEXT类型,包含Cox模型的表名,应该是coxph_train()函数的输出表。
- output_table:TEXT类型,保存测试结果的表名,主输出表列和残差输出表列分别如表4、表5所示。
列名 | 数据类型 | 描述 |
covariate | TEXT | 协变量。 |
rho | FLOAT8[] | 生存时间与Schoenfeld残差相关系数向量。 |
chi_square | FLOAT8[] | 相关分析卡方检验统计量。 |
p_value | FLOAT8[] | 卡方统计双尾p值。 |
表4 cox_zph函数输出表列说明
检验函数还创建一个保存残差值的输出表,名为<output_table>_residual,具有以下列:
列名 | 数据类型 | 描述 |
<dep_column_name> | FLOAT8 | 原始源表中存在的时间值(因变量)。 |
residual | FLOAT8[] | 原始协变量与coxph_train模型中的期望协变量之差。 |
scaled_residual | FLOAT8[] | 由系数的方差来衡量的残差值。 |
表5 cox_zph函数残差输出表列说明
3. 预测函数
(1) 语法
coxph_predict(model_table,
source_table,
id_col_name,
output_table,
pred_type,
reference) (2) 参数
参数名称 | 数据类型 | 描述 |
model_table | TEXT | 包含cox模型的表名。 |
source_table | TEXT | 包含预测数据的表名。 |
id_col_name | TEXT | id列名。 |
output_table | TEXT | 存储预测结果的输出表名,输出表具有以下列: l id:TEXT类型,id列。 l predicted_result:FLOAT8类型,基于预测类型参数值的预测结果。 |
pred_type(可选) | TEXT | 预测类型。缺省为‘linear_predictors’,可以是‘linear_predictors’、‘risk’或‘terms’。 l linear_predictors:计算自变量和系数的点积,也即预后指数。 l risk:预后指数预测结果的指数值。 l terms:每个协变量与它们相应的系数值的乘积,不求和。 |
reference(可选) | TEXT | 用于中心预测。可以为‘strata’、‘overall’,缺省值为‘strata’。 |
表6 coxph_predict函数参数说明
注:Cox回归模型的因变量是风险函数,因此与其它模型的预测函数不同,它不直接返回生存时间的预测值。
三、示例
1. 查看联机帮助
select madlib.coxph_train();
-- 训练函数用法
select madlib.coxph_train('usage');
-- 示例
select madlib.coxph_train('example'); 2. 建立测试数据表并装载原始数据
drop table if exists sample_data;
create table sample_data (
id integer not null, -- 逻辑主键
grp double precision, -- 分组(治疗方法)
wbc double precision, -- 白细胞值
timedeath integer, -- 生存天数
status boolean -- 结局
);
copy sample_data from stdin with delimiter '|';
1 | 0 | 1.45 | 35 | t
2 | 0 | 1.47 | 34 | t
3 | 0 | 2.2 | 32 | t
4 | 0 | 1.78 | 25 | t
5 | 0 | 2.57 | 23 | t
6 | 0 | 2.32 | 22 | t
7 | 0 | 2.01 | 20 | t
8 | 0 | 2.05 | 19 | t
9 | 0 | 2.16 | 17 | t
10 | 0 | 3.6 | 16 | t
11 | 1 | 2.3 | 15 | t
12 | 0 | 2.88 | 13 | t
13 | 1 | 1.5 | 12 | t
14 | 0 | 2.6 | 11 | t
15 | 0 | 2.7 | 10 | t
16 | 0 | 2.8 | 9 | t
17 | 1 | 2.32 | 8 | t
18 | 0 | 4.43 | 7 | t
19 | 0 | 2.31 | 6 | t
20 | 1 | 3.49 | 5 | t
21 | 1 | 2.42 | 4 | t
22 | 1 | 4.01 | 3 | t
23 | 1 | 4.91 | 2 | t
24 | 1 | 5 | 1 | t
\.说明:在这个假设的生存分析案例中,将24名患者分为两组(如模拟两种治疗方法)进行观察。协变量有两个,分组与白细胞值,样本量是协变量个数的12倍。因变量为生存天数。所有患者结局已知,不存在删失情况。
3. 训练模型
drop table if exists sample_cox, sample_cox_summary;
select madlib.coxph_train( 'sample_data',
'sample_cox',
'timedeath',
'array[grp,wbc]',
'status'
); 4. 查看回归结果
\x on
select * from sample_cox;结果:
-[ RECORD 1 ]--+----------------------------------------------------------------------------
coef | {2.54407073265254,1.67172094779487}
loglikelihood | -37.8532498733
std_err | {0.677180599294897,0.387195514577534}
z_stats | {3.7568570855419,4.31751114064138}
p_values | {0.000172060691513886,1.5779844638453e-05}
hessian | {{2.78043065745617,-2.25848560642414},{-2.25848560642414,8.50472838284472}}
num_iterations | 5经过5次迭代后求得两个协变量的回归系数。z检验得到的p值很小,说明样本间的差异由抽样误差所致的概率极小,具有显著统计意义。
5. 检验所得模型的PHA
drop table if exists sample_zph_output, sample_zph_output_residual;
select madlib.cox_zph( 'sample_cox',
'sample_zph_output'
);
select * from sample_zph_output; 结果:
-[ RECORD 1 ]-----------------------------------------
covariate | array[grp,wbc]
rho | {0.00237308357328641,0.037560056884043}
chi_square | {0.000100675718191977,0.0232317400546175}
p_value | {0.991994376850758,0.878855984657948} madlib.cox_zph函数使用卡方线性相关法检验比例风险假设是否成立。它的原理很简单:如果数据满足比例风险假设,则Schoenfeld残差和生存时间的秩次之间无相关性。计算步骤按以下3步进行:①用未删失数据计算每个协变量Schoenfeld残差;②将未删失的生存时间排序,并以新变量(协变量残差)记录秩次1、2、3...,如出现相同生存时间(结点),则以平均秩次记录。③进行假设检验,检验Schoenfeld残差和生存时间秩次间的相关性(原假设为H0:r=0,无相关性)。若原假设被拒绝,则表明数据不满足比例风险假设。
从本例的检验p值结果看,协变量对应的双尾p值接近于1,说明应该接受原假设,模型满足比例风险假设。
6. 用模型进行预测
本例使用源数据表演示预测。
(1)条目预测
\x off
drop table if exists sample_pred_terms;
select madlib.coxph_predict('sample_cox',
'sample_data',
'id',
'sample_pred_terms',
'terms');
select id, terms, sum(c) linear_predictors
from (select id, terms, unnest(terms) c
from sample_pred_terms) t
group by id, terms
order by linear_predictors;结果:
id | terms | linear_predictors
----+------------------------------------------+--------------------
1 | {-0.848023577550848,-2.12308560369949} | -2.97110918125034
2 | {-0.848023577550848,-2.08965118474359} | -2.93767476229444
4 | {-0.848023577550848,-1.57141769092718} | -2.41944126847803
7 | {-0.848023577550848,-1.18692187293436} | -2.03494545048521
8 | {-0.848023577550848,-1.12005303502256} | -1.96807661257341
9 | {-0.848023577550848,-0.936163730765128} | -1.78418730831598
3 | {-0.848023577550848,-0.869294892853333} | -1.71731847040418
19 | {-0.848023577550848,-0.685405588595898} | -1.53342916614675
6 | {-0.848023577550848,-0.668688379117949} | -1.5167119566688
5 | {-0.848023577550848,-0.250758142169231} | -1.09878171972008
14 | {-0.848023577550848,-0.200606513735385} | -1.04863009128623
15 | {-0.848023577550848,-0.0334344189558975} | -0.881457996506746
16 | {-0.848023577550848,0.133737675823589} | -0.714285901727259
12 | {-0.848023577550848,0.267475351647179} | -0.580548225903669
13 | {1.6960471551017,-2.03949955630974} | -0.343452401208047
10 | {-0.848023577550848,1.47111443405949} | 0.623090856508639
11 | {1.6960471551017,-0.702122798073847} | 0.99392435702785
17 | {1.6960471551017,-0.668688379117949} | 1.02735877598375
21 | {1.6960471551017,-0.501516284338462} | 1.19453087076323
18 | {-0.848023577550848,2.85864282072923} | 2.01061924317838
20 | {1.6960471551017,1.28722512980205} | 2.98327228490375
22 | {1.6960471551017,2.15652002265538} | 3.85256717775708
23 | {1.6960471551017,3.66106887567077} | 5.35711603077247
24 | {1.6960471551017,3.81152376097231} | 5.507570916074
(24 rows)条目预测的输出是一个协变量数组,每个元素值是对应协变量与回归系数的点积。
(2)预后指数预测
\x off
drop table if exists sample_pred;
select madlib.coxph_predict('sample_cox',
'sample_data',
'id',
'sample_pred');
select id, linear_predictors, exp(linear_predictors) risk
from sample_pred order by linear_predictors; 结果:
id | linear_predictors | risk
----+--------------------+--------------------
1 | -2.97110918125034 | 0.0512464372091503
2 | -2.93767476229444 | 0.052988797150351
4 | -2.41944126847803 | 0.0889713146524469
7 | -2.03494545048521 | 0.130687611255372
8 | -1.96807661257341 | 0.139725343898993
9 | -1.78418730831598 | 0.167933483703554
3 | -1.71731847040418 | 0.179546963459175
19 | -1.53342916614675 | 0.215794402223054
6 | -1.5167119566688 | 0.219432204682558
5 | -1.09878171972008 | 0.33327686110022
14 | -1.04863009128623 | 0.350417460388247
15 | -0.881457996506746 | 0.414178600294289
16 | -0.714285901727259 | 0.489541567796517
12 | -0.580548225903669 | 0.559591499901242
13 | -0.343452401208048 | 0.709317242984782
10 | 0.623090856508639 | 1.86468261037507
11 | 0.99392435702785 | 2.70181658768287
17 | 1.02735877598375 | 2.79367735395697
21 | 1.19453087076323 | 3.30200833843654
18 | 2.01061924317838 | 7.46794038691976
20 | 2.98327228490375 | 19.7523463121038
22 | 3.85256717775708 | 47.1138577624205
23 | 5.35711603077247 | 212.112338046552
24 | 5.507570916074 | 246.551504798816
(24 rows) 可以看到,1的风险度最小,24的风险度最大,并且预后指数预测的结果,就是对条目预测结果数组的元素求和而得。
(3)风险预测
drop table if exists sample_pred_risk;
select madlib.coxph_predict('sample_cox',
'sample_data',
'id',
'sample_pred_risk',
'risk');
select * from sample_pred_risk order by risk;结果:
id | risk
----+--------------------
1 | 0.0512464372091503
2 | 0.052988797150351
4 | 0.0889713146524469
7 | 0.130687611255372
8 | 0.139725343898993
9 | 0.167933483703554
3 | 0.179546963459175
19 | 0.215794402223054
6 | 0.219432204682558
5 | 0.33327686110022
14 | 0.350417460388247
15 | 0.414178600294289
16 | 0.489541567796517
12 | 0.559591499901242
13 | 0.709317242984782
10 | 1.86468261037507
11 | 2.70181658768287
17 | 2.79367735395697
21 | 3.30200833843654
18 | 7.46794038691976
20 | 19.7523463121038
22 | 47.1138577624205
23 | 212.112338046552
24 | 246.551504798816
(24 rows) 可以看到,风险预测就是预后指数结果的指数值。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









