








一、贝叶斯分类简介
1. 贝叶斯分类原理
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。贝叶斯分类是一种利用概率统计知识进行分类的算法,其分类原理是贝叶斯定理。贝叶斯定理是由18世纪概率论和决策论的早期研究者Thomas Bayes发明的,故用其名字命名为贝叶斯定理。
贝叶斯定理(Bayes’theorem)是概率论中的一个结果,它与随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理能够告诉我们如何利用新证据修改已有的看法。通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的。然而,这两者是具有确定的关系,贝叶斯定理就是这种关系的陈述。
假设X、Y是一对随机变量,它们的联合概率P(X=x,Y=y)是指X取值x且Y取值y的概率,条件概率是指一个随机变量在另一个随机变量取值已知的情况下取某一特定值的概率。例如,条件概率P(Y=y|X=x)是指在变量X取值x的情况下,变量Y取值y的概率。X和Y的联合概率和条件概率满足如下关系:
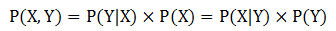
对此变形,可得到下面的公式,称为贝叶斯定理:
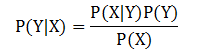
贝叶斯定理很有用,因为它允许我们用先验概率P(Y)、条件概率P(X|Y)和证据P(X)来表示后验概率。来看一个例子,考虑两队之间的足球比赛:队0和队1,假设65%的比赛队0胜出,剩余的比赛队1获胜。队0获胜的比赛中有30%是在队1的主场,而队1取胜的比赛中75%是主场获胜。如果下一场比赛在队1的主场进行,哪支球队最有可能胜出呢?
贝叶斯定理可以用来解决这个预测问题。用随机变量X代表东道主,随机变量Y代表比赛的胜利者。X和Y可在集合{0,1}中取值。那么问题中给出的信息可总结如下:
- 队0取胜的概率是P(Y=0)=0.65;
- 队1取胜的概率是P(Y=1)=1-P(Y=0)=0.35;
- 队1取胜时作为东道主的概率是P(X=1|Y=1)=0.75;
- 队0取胜时队1作为东道主的概率是P(X=1|Y=0)=0.3。
我们的目的是计算P(Y=1|X=1),即队1在主场获胜的概率,并与P(Y=0|X=1)比较。应用贝叶斯定理得到:
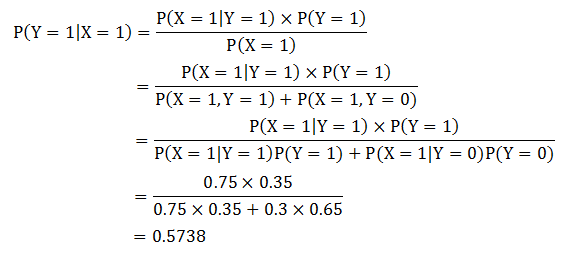
而P(Y=0|X=1)=1-P(Y=1|X=1)=0.4262。因为P(Y=1|X=1)>P(Y=0|X=1),所以,队1更有机会赢得下一场比赛。
2. 朴素贝叶斯分类原理
在贝叶斯分类器中,朴素贝叶斯最为常用。朴素贝叶斯分类是一种十分简单的分类算法,其思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。可见这种分类方法的思想真的很朴素。
朴素贝叶斯分类器建立在一个类条件独立性假设(朴素假设)基础之上:给定类节点(变量)后,各属性节点(变量)之间相互独立。根据朴素贝叶斯的类条件独立假设,则有:
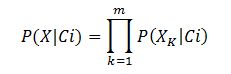
条件概率 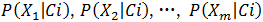
朴素贝叶斯分类的正式步骤如下:
步骤1:设 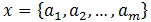
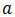
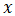
步骤2:有类别集合 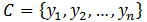
步骤3:计算 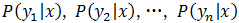
步骤4:如果 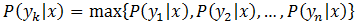
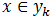
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1) 找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2) 统计得到在各类别下各个特征属性的条件概率估计,即:
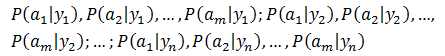
3) 如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
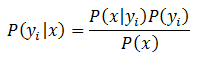
因为分母对于所有类别为常数,因此只要将分子最大化即可,因为各个特征属性是条件独立的,所以有:
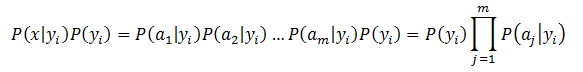
根据上述分析,朴素贝叶斯分类的流程可以由图1表示(暂时不考虑验证)。
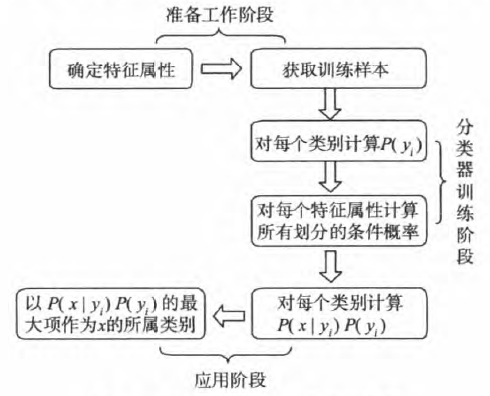
图1 朴素贝叶斯算法分类流程图
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段:准备工作阶段。这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当的划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量在很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段:分类器训练阶段。这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并记录结果。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段:应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
朴素贝叶斯算法成立的前提是各属性之间相互独立。当数据集满足这种独立性假设时,分类的准确度较高,否则可能较低。另外,该算法没有分类规则输出。
3. 朴素贝叶斯分类器举例
考虑表1中的数据集:
ID | 有房 | 婚姻状况 | 年收入 | 拖欠贷款 |
1 | 是 | 单身 | 120K | 否 |
2 | 否 | 已婚 | 100K | 否 |
3 | 否 | 单身 | 70K | 否 |
4 | 是 | 已婚 | 120K | 否 |
5 | 否 | 离婚 | 95K | 是 |
6 | 否 | 已婚 | 60K | 否 |
7 | 是 | 离婚 | 220K | 否 |
8 | 否 | 单身 | 85K | 是 |
9 | 否 | 已婚 | 75K | 否 |
10 | 否 | 单身 | 90K | 是 |
表1 贷款分类问题的朴素贝叶斯分类器
我们可以计算每个特征属性的类条件概率:
- P(有房=是|No)=3/7
- P(有房=否|No)=4/7
- P(有房=是|Yes)=0
- P(有房=否|Yes)=1
- P(婚姻状况=单身|No)=2/7
- P(婚姻状况=离婚|No)=1/7
- P(婚姻状况=已婚|No)=4/7
- P(婚姻状况=单身|Yes)=2/3
- P(婚姻状况=离婚|Yes)=1/3
- P(婚姻状况=已婚|Yes)=0
年收入是连续变量。我们可以假设连续变量服从某种概率分布,然后使用训练数据估计分布的参数。高斯分布通常用来表示连续属性的类条件概率分布。该分布有两个参数,均值 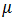
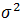
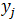
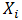
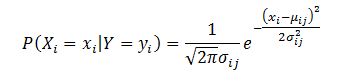
参数 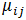
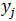
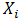
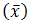
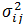
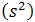
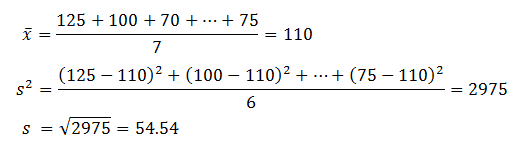
给定一测试记录,收入等于120K,其类条件概率计算如下:
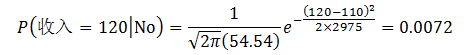
为了预测测试记录 X=(有房=否, 婚姻状况=已婚, 年收入=120K) 的类标号,需要计算后验概率P(No|X)和P(Yes|X)。每个类的先验概率可以通过属于该类的训练记录所占的比例来估计。因为有3个记录属于类Yes,7个记录属于类No,所以P(Yes)=0.3,P(No)=0.7。类条件概率计算如下:
P(X|No)=P(有房=否|No)×P(婚姻状况=已婚|No)×P(年收入=120K|No)=4/7×4/7×0.0072=0.0024
P(X|Yes)=P(有房=否|Yes)×P(婚姻状况=已婚|Yes)×P(年收入=120K|Yes) =1×0×1.2× 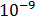
放到一起可得到类No的后验概率P(No|X)=a×7/10×0.024=0.0016a,其中a=1/P(X)是个常量。同理,可以得到类Yes的后验概率等于0,因为它的类条件概率等于0。因为P(No|X)>P(Yes|X),所以记录分类为No。
4. 朴素贝叶斯特点
朴素贝叶斯分类器一般具有以下特点:
- 简单、高效、健壮。面对孤立的噪声点,朴素贝叶斯分类器是健壮的,因为在从数据中估计条件概率时,这些点被平均,另外朴素贝叶斯分类器也可以处理属性值遗漏问题。而面对无关属性,该分类器依然是健壮的,因为如果Xi是无关属性,那么P(Xi|Y)几乎变成了均匀分布,Xi的类条件概率不会对总的后验概率的计算产生影响。
- 相关属性可能会降低朴素贝叶斯分类器的性能,因为对这些属性,条件独立的假设已不成立。
二、MADlib中朴素贝叶斯分类相关函数
MADlib提供的朴素贝叶斯分类(Naive Bayes Classification)模块仍然处于早期开发阶段。将来的版本会解决一些问题,并且接口和实现可能会发生变化。MADlib的朴素贝叶斯分类使用最大似然或拉普拉斯平滑估计先验概率。对于数字属性,可以使用高斯平滑来估计先验概率,然后使用这些参数对新数据进行分类。
1. 训练函数
对于仅具有分类属性的数据,使用以下函数预计算先验概率:
create_nb_prepared_data_tables ( trainingSource,
trainingClassColumn,
trainingAttrColumn,
numAttrs,
featureProbsName,
classPriorsName
)对于包含分类属性和数字属性的数据,使用以下形式的函数预先计算数字属性的高斯参数(均值和方差),并估计分类属性和数字属性的先验概率。
create_nb_prepared_data_tables ( trainingSource,
trainingClassColumn,
trainingAttrColumn,
numericAttrsColumnIndices,
numAttrs,
featureProbsName,
numericAttrParamsName,
classPriorsName
)用作训练的数据源应具有以下形式:
{TABLE|VIEW} trainingSource (
...
trainingClassColumn INTEGER,
trainingAttrColumn INTEGER[] OR NUMERIC[] OR FLOAT8[],
...
)numericAttrsColumnIndices应该是TEXT类型的,指定为与数字属性对应的trainingAttrColumn数组中的索引数组(从1开始)。
函数的两个输出表为:
- featureProbsName:存储特征的先验概率。
- classPriorsName:存储先验类别。
除这两个输出表之外,如果使用指定数字属性的函数,则会创建一个附加表numericAttrParamsName,该表存储数字属性的高斯参数。
2. 分类函数
如果数据只包含分类属性,以下函数执行朴素贝叶斯分类:
create_nb_classify_view ( featureProbsName,
classPriorsName,
classifySource,
classifyKeyColumn,
classifyAttrColumn,
numAttrs,
destName
)对于具有数字属性的数据,使用以下版本:
create_nb_classify_view ( featureProbsName,
classPriorsName,
classifySource,
classifyKeyColumn,
classifyAttrColumn,
numAttrs,
numericAttrParamsName,
destName
)待分类数据应具有以下形式:
{TABLE|VIEW} classifySource (
...
classifyKeyColumn ANYTYPE,
classifyAttrColumn INTEGER[],
...
)该函数创建destName视图,将classifyKeyColumn映射为朴素贝叶斯分类。
3. 概率函数
如果数据只包含分类属性,以下函数计算朴素贝叶斯概率:
create_nb_probs_view( featureProbsName,
classPriorsName,
classifySource,
classifyKeyColumn,
classifyAttrColumn,
numAttrs,
destName
)对于具有数字属性的数据,使用以下版本:
create_nb_probs_view( featureProbsName,
classPriorsName,
classifySource,
classifyKeyColumn,
classifyAttrColumn,
numAttrs,
numericAttrParamsName,
destName
)函数创建destName视图,将classifyKeyColumn及其每个类别映射为朴素贝叶斯概率。
4. 即席计算
通过执行即席调用,函数create_nb_classify_view()和create_nb_probs_view()可以在没有预计算步骤的情况下以即席方式使用。这种情况下,要替换函数的‘featureProbsName’和‘classPriorsName’参数。
如果数据只包含分类属性,则替换为‘trainingSource’、‘trainingClassColumn’、‘trainingAttrColumn’。如果数据还包含数字属性,则替换为‘trainingSource’、‘trainingClassColumn’、‘trainingAttrColumn’、‘numericAttrsColumnIndices’。
三、示例
我们将利用MADlib的朴素贝叶斯分类相关函数解决根据天气情况预测是否打高尔夫球的问题。问题描述及其已知数据参见“MADlib——基于SQL的数据挖掘解决方案(21)——分类之KNN”。
1. 准备训练数据
drop table if exists nb_train_data;
create table nb_train_data (
id integer,
data float8[],
label integer
);
insert into nb_train_data values
(1, '{1,85,85,0}', 0), (2, '{1,80,90,1}', 0), (3, '{2,83,78,0}', 1),
(4, '{3,70,96,0}', 1), (5, '{3,68,80,0}', 1), (6, '{3,65,70,1}', 0),
(7, '{2,64,65,1}', 1), (8, '{1,72,95,0}', 0), (9, '{1,69,70,0}', 1),
(10,'{3,75,80,0}', 1), (11,'{1,75,70,1}', 1), (12,'{2,72,90,1}', 1),
(13,'{2,81,75,0}', 1), (14,'{3,71,80,1}', 0); 2. 准备测试数据
drop table if exists nb_test_data;
create table nb_test_data
( id integer,
data float8[]
);
insert into nb_test_data values
(1, '{1,73.57,80.29,0}'),
(2, '{2,73.57,80.29,0}'),
(3, '{3,73.57,80.29,0}'),
(4, '{1,73.57,80.29,1}'),
(5, '{2,73.57,80.29,1}'),
(6, '{3,73.57,80.29,1}'); 3. 预计算先验概率
drop table exists categ_feature_probs, numeric_attr_params, class_priors;
select madlib.create_nb_prepared_data_tables
( 'nb_train_data',
'label',
'data',
'array[2,3]',
4,
'categ_feature_probs',
'numeric_attr_params',
'class_priors' );一共四个属性列,其中温度与湿度为数字属性。
4. 查询预计算输出表
dm=# select * from categ_feature_probs;
class | attr | value | cnt | attr_cnt
-------+------+-------+-----+----------
0 | 4 | 0 | 2 | 2
1 | 4 | 1 | 3 | 2
0 | 1 | 2 | 0 | 3
1 | 1 | 3 | 3 | 3
1 | 4 | 0 | 6 | 2
0 | 4 | 1 | 3 | 2
0 | 1 | 1 | 3 | 3
0 | 1 | 3 | 2 | 3
1 | 1 | 1 | 2 | 3
1 | 1 | 2 | 4 | 3
(10 rows)
dm=# select * from numeric_attr_params;
class | attr | attr_mean | attr_var
-------+------+------------------+------------------
0 | 3 | 84 | 92.5
1 | 2 | 73 | 38
1 | 3 | 78.2222222222222 | 97.6944444444444
0 | 2 | 74.6 | 62.3
(4 rows)
dm=# select * from class_priors;
class | class_cnt | all_cnt
-------+-----------+---------
0 | 5 | 14
1 | 9 | 14
(2 rows)5. 建立朴素贝叶斯分类视图并检查结果
drop view if exists classify_view;
select madlib.create_nb_classify_view
( 'categ_feature_probs',
'class_priors',
'nb_test_data',
'id',
'data',
4,
'numeric_attr_params',
'classify_view');
select * from classify_view order by key;结果:
key | nb_classification
-----+-------------------
1 | {1}
2 | {1}
3 | {1}
4 | {0}
5 | {1}
6 | {1}
(6 rows)6. 查看每个分类的概率
drop view if exists probs_view;
select madlib.create_nb_probs_view
( 'categ_feature_probs',
'class_priors',
'nb_test_data',
'id',
'data',
4,
'numeric_attr_params',
'probs_view' );
select * from probs_view;结果:
key | class | nb_prob
-----+-------+--------------------
1 | 0 | 0.362026631050167
1 | 1 | 0.637973368949833
2 | 0 | 0.0784425398146124
2 | 1 | 0.921557460185388
3 | 0 | 0.241963818929579
3 | 1 | 0.758036181070421
4 | 0 | 0.569722510817469
4 | 1 | 0.430277489182531
5 | 0 | 0.165701829732561
5 | 1 | 0.834298170267439
6 | 0 | 0.426867064147249
6 | 1 | 0.573132935852751
(12 rows)7. 执行即席计算
drop view if exists classify_view;
select madlib.create_nb_classify_view
( 'nb_train_data',
'label',
'data',
'array[2,3]',
'nb_test_data',
'id',
'data',
4,
'classify_view');
select * from classify_view order by key;结果:
key | nb_classification
-----+-------------------
1 | {1}
2 | {1}
3 | {1}
4 | {0}
5 | {1}
6 | {1}
(6 rows)查看每个分类的概率:
drop view if exists probs_view;
select madlib.create_nb_probs_view
( 'nb_train_data',
'label',
'data',
'array[2,3]',
'nb_test_data',
'id',
'data',
4,
'probs_view' );
select * from probs_view;结果:
key | class | nb_prob
-----+-------+--------------------
1 | 0 | 0.362026631050167
1 | 1 | 0.637973368949833
2 | 0 | 0.0784425398146124
2 | 1 | 0.921557460185388
3 | 0 | 0.241963818929579
3 | 1 | 0.758036181070421
4 | 0 | 0.569722510817469
4 | 1 | 0.430277489182531
5 | 0 | 0.165701829732561
5 | 1 | 0.834298170267439
6 | 0 | 0.426867064147249
6 | 1 | 0.573132935852751
(12 rows)即席计算的结果与先进行预计算再计算分类的结果完全一致。















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









