






一、HOG描述与SVM简介
方向梯度直方图(英语:Histogram of oriented gradient,简称HOG)是应用在计算机视觉和图像处理领域,用于目标检测的特征描述器。这项技术是用来计算局部图像梯度的方向信息的统计值。
HOG理论基础及优点
HOG描述器最重要的思想是:在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。具体的实现方法是:首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。为了提高性能,我们还可以把这些局部直方图在图像的更大的范围内(我们把它叫区间或block)进行对比度归一化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
优点:
首先,由于HOG方法是在图像的局部细胞单元上操作,所以它对图像几何的(geometric)和光学的(photometric)形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,作者通过实验发现,在粗的空域抽样(coarse spatial sampling)、精细的方向抽样(fine orientation sampling)以及较强的局部光学归一化(strong local photometric normalization)等条件下,只要行人大体上能够保持直立的姿势,就容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。综上所述,HOG方法是特别适合于做图像中的行人检测的。
支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。
二、微笑识别
流程为定位人脸->构建HOG特征->SVM训练
1.代码
导入包和图片
# 导入包
import numpy as np
import cv2
import dlib
import random#构建随机测试集和训练集
from sklearn.svm import SVC #导入svm
from sklearn.svm import LinearSVC #导入线性svm
from sklearn.pipeline import Pipeline #导入python里的管道
import os
import joblib#保存模型
from sklearn.preprocessing import StandardScaler,PolynomialFeatures #导入多项式回归和标准化
import tqdm
folder_path='F:/picture/second/genki4k/'
label='labels.txt'#标签文件
pic_folder='files/'#图片文件路径
获得特征点检测器
#获得默认的人脸检测器和训练好的人脸68特征点检测器
def get_detector_and_predicyor():
#使用dlib自带的frontal_face_detector作为我们的特征提取器
detector = dlib.get_frontal_face_detector()
"""
功能:人脸检测画框
参数:PythonFunction和in Classes
in classes表示采样次数,次数越多获取的人脸的次数越多,但更容易框错
返回值是矩形的坐标,每个矩形为一个人脸(默认的人脸检测器)
"""
#返回训练好的人脸68特征点检测器
predictor = dlib.shape_predictor('F:/picture/shape_predictor_68_face_landmarks.dat')
return detector,predictor
#获取检测器
detector,predictor=get_detector_and_predicyor()
截取面部
def cut_face(img,detector,predictor):
#截取面部
img_gry=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
rects = detector(img_gry, 0)
if len(rects)!=0:
mouth_x=0
mouth_y=0
landmarks = np.matrix([[p.x, p.y] for p in predictor(img,rects[0]).parts()])
for i in range(47,67):#嘴巴范围
mouth_x+=landmarks[i][0,0]
mouth_y+=landmarks[i][0,1]
mouth_x=int(mouth_x/20)
mouth_y=int(mouth_y/20)
#裁剪图片
img_cut=img_gry[mouth_y-20:mouth_y+20,mouth_x-20:mouth_x+20]
return img_cut
else:
return 0#检测不到人脸返回0
提取特征值
#提取特征值
def get_feature(files_train,face,face_feature):
for i in tqdm.tqdm(range(len(files_train))):
img=cv2.imread(folder_path+pic_folder+files_train[i])
cut_img=cut_face(img,detector,predictor)
if type(cut_img)!=int:
face.append(True)
cut_img=cv2.resize(cut_img,(64,64))
#padding:边界处理的padding
padding=(8,8)
winstride=(16,16)
hogdescrip=hog.compute(cut_img,winstride,padding).reshape((-1,))
face_feature.append(hogdescrip)
else:
face.append(False)#没有检测到脸的
face_feature.append(0)
筛选
def filtrate_face(face,face_feature,face_site): #去掉检测不到脸的图片的特征并返回特征数组和相应标签
face_features=[]
#获取标签
label_flag=[]
with open(folder_path+label,'r') as f:
lines=f.read().splitlines()
#筛选出能检测到脸的,并收集对应的label
for i in tqdm.tqdm(range(len(face_site))):
if face[i]:#判断是否检测到脸
#pop之后要删掉当前元素,后面的元素也要跟着前移,所以每次提取第一位就行了
face_features.append(face_feature.pop(0))
label_flag.append(int(lines[face_site[i]][0]))
else:
face_feature.pop(0)
datax=np.float64(face_features)
datay=np.array(label_flag)
return datax,datay
SVM
def PolynomialSVC(degree,c=10):#多项式svm
return Pipeline([
# 将源数据 映射到 3阶多项式
("poly_features", PolynomialFeatures(degree=degree)),
# 标准化
("scaler", StandardScaler()),
# SVC线性分类器
("svm_clf", LinearSVC(C=10, loss="hinge", random_state=42,max_iter=10000))
])
#svm高斯核
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
训练
def train(files_train,train_site):#训练
'''
files_train:训练文件名的集合
train_site :训练文件在文件夹里的位置
'''
#是否检测到人脸
train_face=[]
#人脸的特征数组
train_feature=[]
#提取训练集的特征数组
get_feature(files_train,train_face,train_feature)
#筛选掉检测不到脸的特征数组
train_x,train_y=filtrate_face(train_face,train_feature,train_site)
svc=PolynomialSVC(degree=1)
svc.fit(train_x,train_y)
return svc#返回训练好的模型
测试
def test(files_test,test_site,svc):#预测,查看结果集
'''
files_train:训练文件名的集合
train_site :训练文件在文件夹里的位置
'''
#是否检测到人脸
test_face=[]
#人脸的特征数组
test_feature=[]
#提取训练集的特征数组
get_feature(files_test,test_face,test_feature)
#筛选掉检测不到脸的特征数组
test_x,test_y=filtrate_face(test_face,test_feature,test_site)
pre_y=svc.predict(test_x)
ac_rate=0
for i in range(len(pre_y)):
if(pre_y[i]==test_y[i]):
ac_rate+=1
ac=ac_rate/len(pre_y)*100
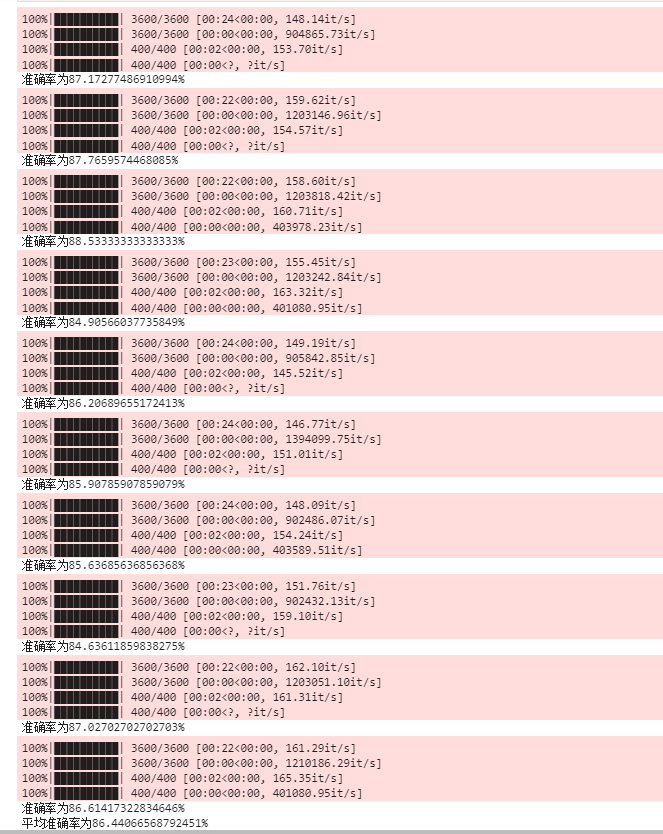
print("准确率为"+str(ac)+"%")
return ac
HOG特征提取
#设置hog的参数
winsize=(64,64)
blocksize=(32,32)
blockstride=(16,16)
cellsize=(8,8)
nbin=9
#定义hog
hog=cv2.HOGDescriptor(winsize,blocksize,blockstride,cellsize,nbin)
#获取文件夹里有哪些文件
files=os.listdir(folder_path+pic_folder)
划分训练集测试集
ac=float(0)
for j in range(10):
site=[i for i in range(4000)]
#训练所用的样本所在的位置
train_site=random.sample(site,3600)
#预测所用样本所在的位置
test_site=[]
for i in range(len(site)):
if site[i] not in train_site:
test_site.append(site[i])
files_train=[]
#训练集,占总数的十分之九
for i in range(len(train_site)):
files_train.append(files[train_site[i]])
#测试集
files_test=[]
for i in range(len(test_site)):
files_test.append(files[test_site[i]])
svc=train(files_train,train_site)
ac=ac+test(files_test,test_site,svc)
save_path='F:/picture/second/train/second'+str(j)+'(hog).pkl'
joblib.dump(svc,save_path)
ac=ac/10
print("平均准确率为"+str(ac)+"%")
检测人脸
def test1(files_test,test_site,svc):#预测,查看结果集
'''
files_train:训练文件名的集合
train_site :训练文件在文件夹里的位置
'''
#是否检测到人脸
test_face=[]
#人脸的特征数组
test_feature=[]
#提取训练集的特征数组
get_feature(files_test,test_face,test_feature)
#筛选掉检测不到脸的特征数组
test_x,test_y=filtrate_face(test_face,test_feature,test_site)
pre_y=svc.predict(test_x)
tp=0
tn=0
for i in range(len(pre_y)):
if pre_y[i]==test_y[i] and pre_y[i]==1:
tp+=1
elif pre_y[i]==test_y[i] and pre_y[i]==0:
tn+=1
f1=2*tp/(tp+len(pre_y)-tn)
print(f1)
svc7=joblib.load('../source/model/smile9(hog).pkl')
site=[i for i in range(4000)]
#训练所用的样本所在的位置
train_site=random.sample(site,3600)
#预测所用样本所在的位置
test_site=[]
for i in range(len(site)):
if site[i] not in train_site:
test_site.append(site[i])
#测试集
files_test=[]
for i in range(len(test_site)):
files_test.append(files[test_site[i]])
test1(files_test,test_site,svc7)

2.笑脸检测和结果
def smile_detector(img,svc):
cut_img=cut_face(img,detector,predictor)
a=[]
if type(cut_img)!=int:
cut_img=cv2.resize(cut_img,(64,64))
#padding:边界处理的padding
padding=(8,8)
winstride=(16,16)
hogdescrip=hog.compute(cut_img,winstride,padding).reshape((-1,))
a.append(hogdescrip)
result=svc.predict(a)
a=np.array(a)
return result[0]
else :
return 2
##图片检测
pic_path='F:/picture/-.jpg'
img=cv2.imread(pic_path)
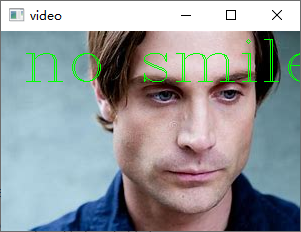
result=smile_detector(img,svc7)
if result==1:
img=cv2.putText(img,'smile',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
elif result==0:
img=cv2.putText(img,'no smile',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
else:
img=cv2.putText(img,'no face',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
cv2.imshow('video', img)
cv2.waitKey(0)

调用摄像头S保存esc退出
camera = cv2.VideoCapture(0)#打开摄像头
ok=True
flag=0
# 打开摄像头 参数为输入流,可以为摄像头或视频文件
while ok:
ok,img = camera.read()
# 转换成灰度图像
result=smile_detector(img,svc7)
if result==1:
img=cv2.putText(img,'smile',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
elif result==0:
img=cv2.putText(img,'no smile',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
else:
img=cv2.putText(img,'no face',(21,50),cv2.FONT_HERSHEY_COMPLEX,2.0,(0,255,0),1)
cv2.imshow('video', img)
k = cv2.waitKey(1)
if k == X: # press 'ESC' to quit
break
elif k==115:
pic_save_path='F:/picture/second/result/'+str(flag)+'.jpg'
flag+=1
cv2.imwrite(pic_save_path,img)
camera.release()
cv2.destroyAllWindows()















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









