







导读
2023年以ChatGPT为代表的大语言模型横空出世,它的出现标志着自然语言处理领域取得了重大突破。它在文本生成、对话系统和语言理解等方面展现出了强大的能力,为人工智能技术的发展开辟了新的可能性。同时,人工智能技术正在进入各种应用领域,在智慧城市、智能制造、智慧医疗、智慧农业等领域发挥着重要作用。
柴火创客2024年将依托母公司Seeed矽递科技在人工智能领域的创新硬件,与全球创客爱好者共建“模型仓”,通过“SenseCraft AI”平台可以让使用者快速部署应用体验人工智能技术!
本期介绍:模型案例:| 手势动作识别模型训练与应用!
GroundingDINO
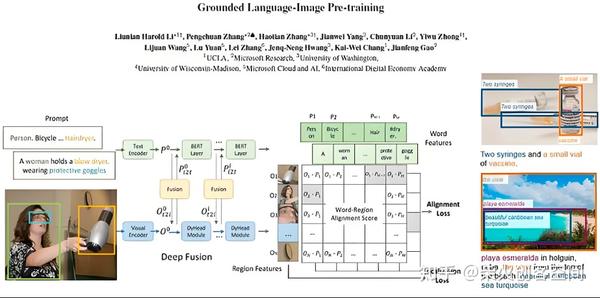
基于DINO的开放式检测器Grounding DINO不仅实现了最先进的物体检测性能,还通过Grounding预训练实现了多级文本信息的集成。与 GLIP 或接地语言图像预训练相比,GroundingDINO 具有多项优势。首先,其基于Transformer的架构,类似于语言模型,便于处理图像和语言数据。
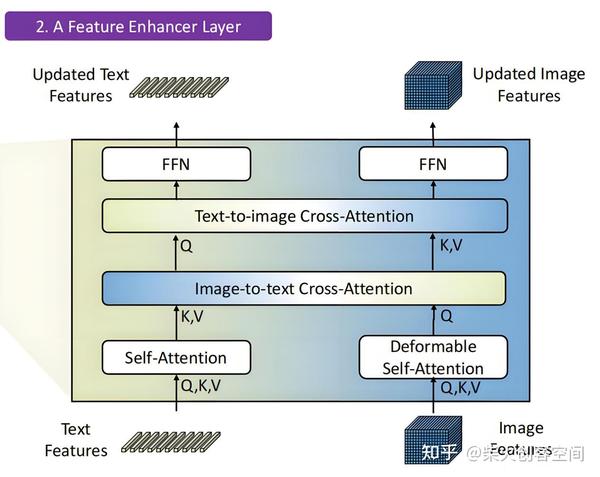
该方法融合了文本和图像两个模态的数据,实现了开放集目标检测,即给定一个文本提示,自动框出目标所在,该目标可以是训练集中没有的类别。该方法主要通过特征增强模块、语言指导查询选择模块、跨模态解码模块实现上述功能。
GroundingDINO架构
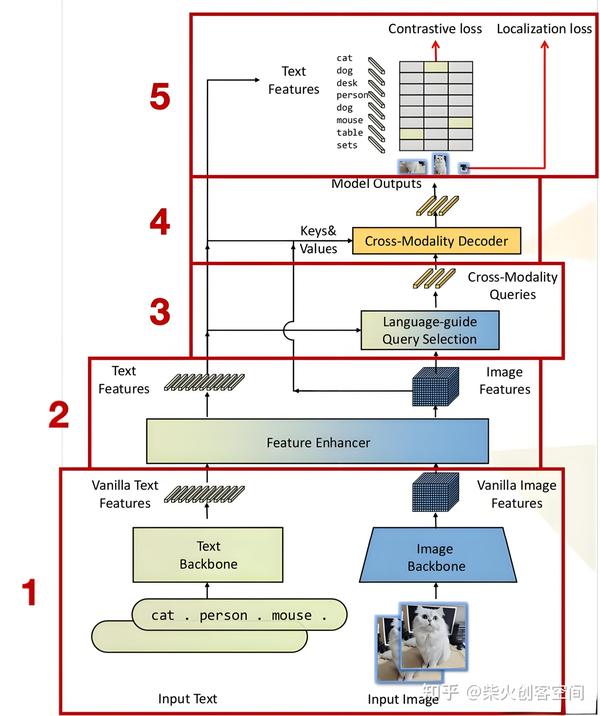
如上图所示,该方法从下到上主要包括五大模块:特征提取模块(Backbone)、特征增强模块(Feature Enhancer)、语言指导查询选择模块(Language-guide Query Selection)、跨模态解码模块(Cross-Modality Decoder)、损失计算模块(Loss)。
该框架支持多种功能,包括推理、对象检测数据训练、基于接地的数据训练等。它采用了PyTorch作为主要开发库,并优化了训练策略以加快模型收敛速度。Grounding DINO的灵活性体现在其对混合数据集的支持上,可以同时处理OD(对象检测)和VG(视觉基因组)数据,使得模型能够在更广泛的上下文中学习和泛化。
应用场景

Grounding DINO可应用于多种场景中,例如智能监控、自动驾驶、无人机导航以及图像搜索等领域。尤其是在多模式识别和理解方面,它的表现尤为出色。结合BERT等语言模型,Grounding DINO能根据文本提示精确定位图片中的目标对象,极大地提升了场景理解和语义解析的能力。
Grounding DINO特点
适应性强:不仅能在官方提供的预训练模型下运行,还能通过微调以适应特定数据集。
高度可配置:提供了详细的配置文件,允许用户自定义训练参数,如backbone架构、批量大小、学习率等。
训练加速策略:针对大型数据集设计,采用torch.distributed.launch进行分布式训练,支持多机协同工作,大幅缩短训练时间。
广泛的数据兼容性:支持OD和VG两种不同类型的标注数据,极大扩展了模型的应用范围。
手势动作识别模型训练与应用

在模型案例推文中,介绍过通过摄像头进行视觉识别和通过麦克风进行声音识别,今天介绍第三种识别形式:利用多轴加速度传感器进行动作识别。
我们尝试利用手机自带的三轴加速度传感器来采集三种动作手势,包括左右晃动、上下晃动和静止不动
动作训练与应用
Edge Impulse 是一个专注于边缘计算和物联网 (IoT) 的机器学习平台。它允许开发者和企业创建、训练和部署机器学习模型,以便在边缘设备上运行。
易于使用:提供图形用户界面,让非数据科学家也能轻松使用。
快速原型:支持快速构建和测试机器学习模型,缩短开发周期。
多种数据输入:支持从多种传感器和数据源收集数据,如音频、图像和加速度计等。
模型优化:能够对模型进行优化,以适应边缘设备的限制,例如减少内存和计算需求。
支持多种平台:可以将模型部署到不同的硬件平台,包括微控制器和更复杂的嵌入式系统。
采集三种手势动作数据
- 进入Edge Impulse官网,注册并登录账号后点击右上角【Create new project】按钮,创建一个项目,如下图所示。
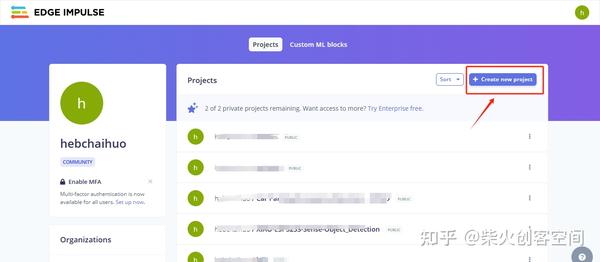
2、在文本框中输入项目名称(备注:请输入英文名称),单击右下角的【Create new project】按钮,这样就创建了一个新项目,如下图所示。
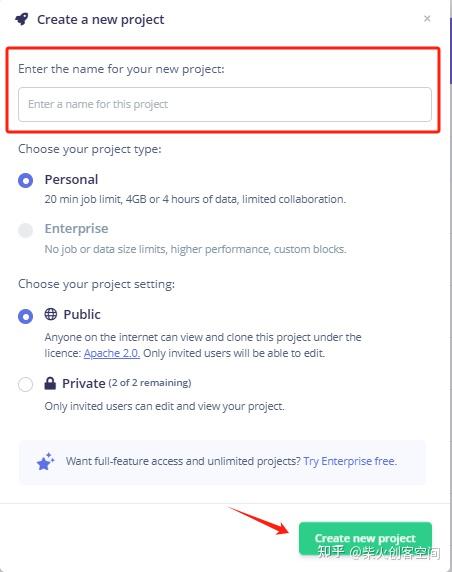
3、进入项目后单击左侧的【Data acquisition】按钮,进入数据采集页面,如下图所示。
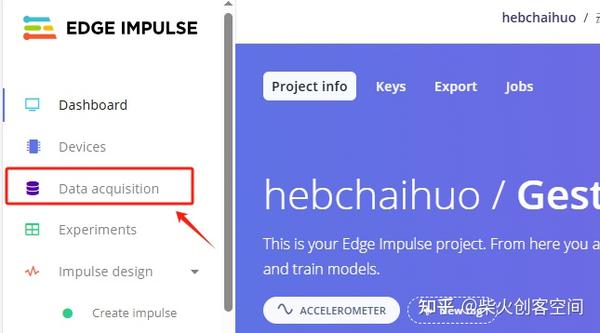
- 进入数据采集页面后,在右侧的“Collect data”中点击“Connect a device”链接,如下图所示。
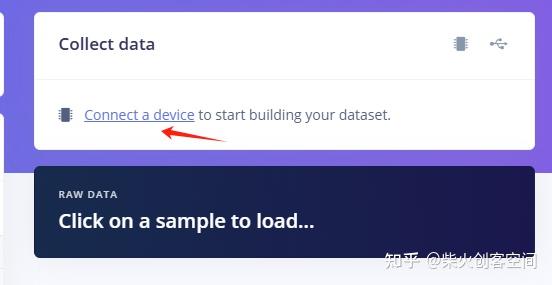
5、弹出Collect new data窗口,用手机浏览器扫描下左侧的二维码,如下图所示。
https://smartphone.edgeimpulse.com/index.html?apiKey=ei_8e4a7b875e6eaad4d307f437646c572b51e85cbcb92dc241c7ec37e6f6030dcd (二维码自动识别)
6、在手机浏览器上会显示连接界面,这里列出了手机可采集数据的方式包括摄像头、麦克风和三轴加速度传感器,这里单击【Collecting motion】按钮,,如下图所示。
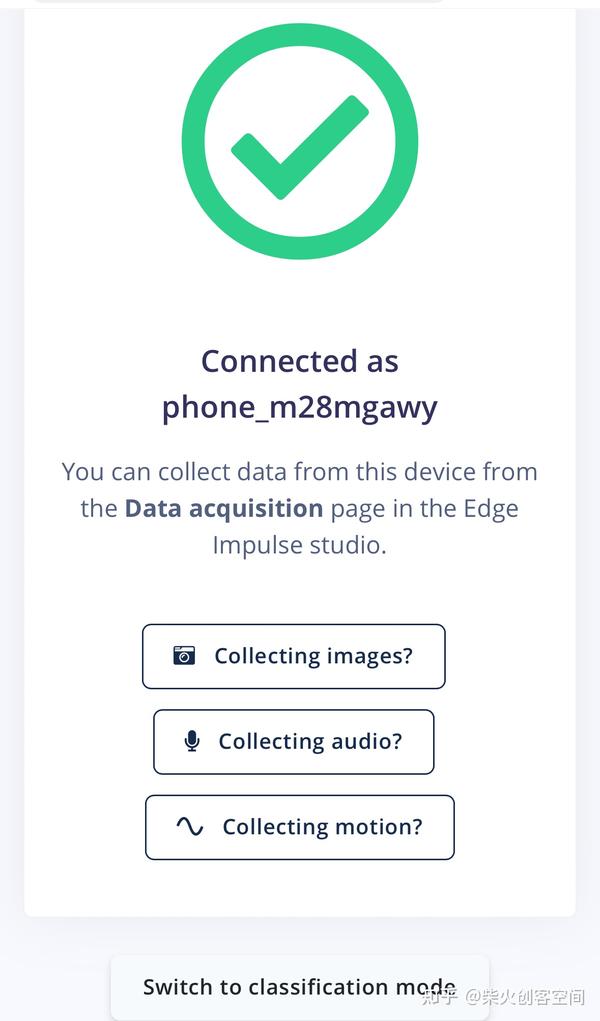
7、进入提示页面,单击【Give access to the accelerometer】按钮,打开手机上的三轴加速度传感器,如下图所示。还会弹出一个询问是否允许界面,单击【允许】按钮。
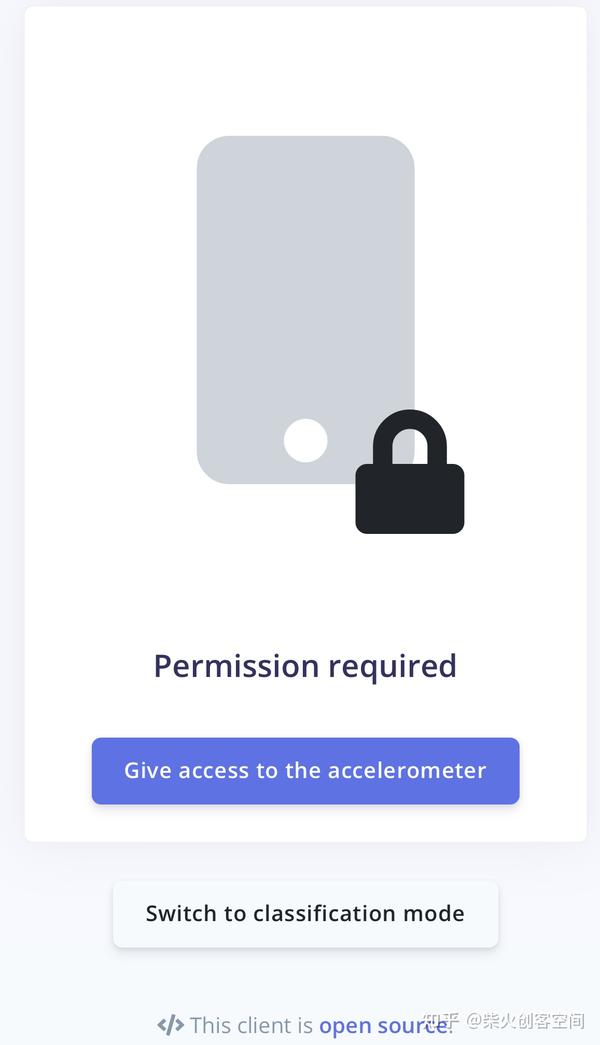
8、这样就进入三轴加速度传感器采集页面,单击“Label”会弹出设置类别窗口,这里会采集三个类别包括左右晃动(about)、上下晃动(up_anddown)和静止不动(static);比如采集静止不动,在单击“Label”选项输入“static”,单击【Start recording】按钮如下图所示。
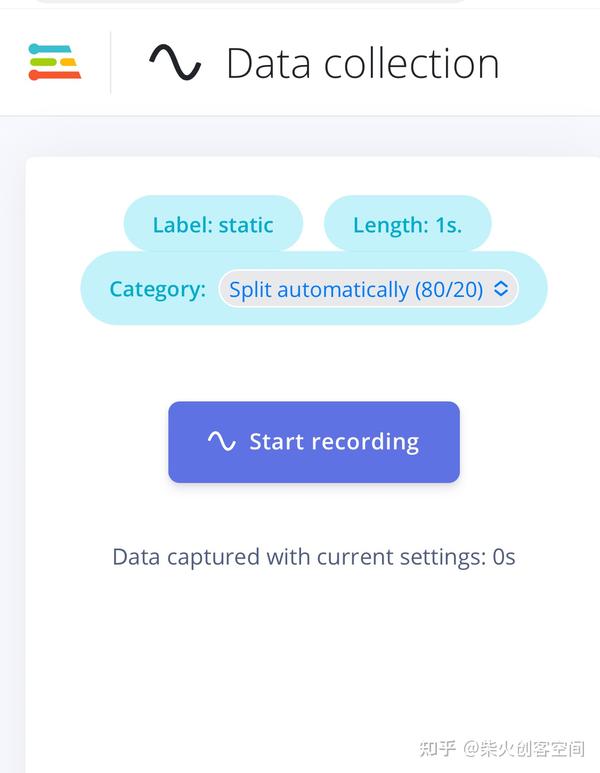
- 单击【Start recording】按钮后,手里拿着手机静止不动,等待1秒钟后就会将三轴加速传感器的x、y、z的三轴数据上传到Edge Impulse平台上,如下图所示。
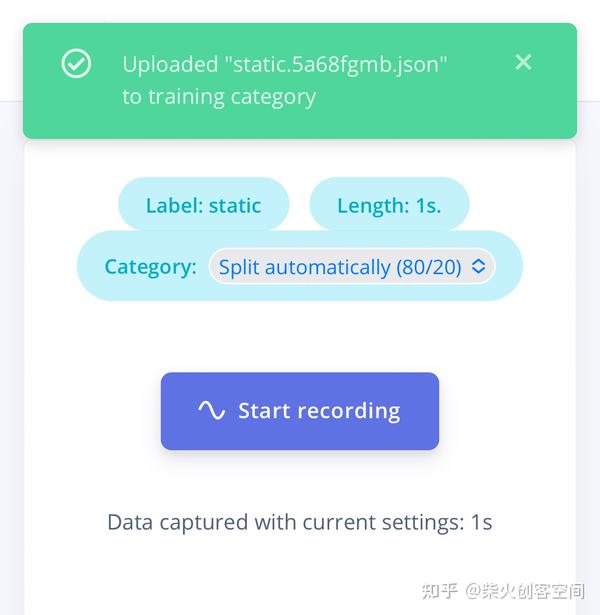
9、手机上采集的三轴加速度传感器数据会上传到Edge Impulse的项目页面中,在“Dataset”列表中会列出采集数据文件,右侧会显示出此文件的x、y、z三轴折线图表,如下图所示。安装这种方法先参加20到30条静止不动(static)的数据。
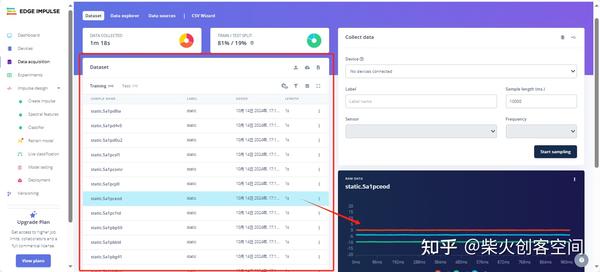
10、接着采集拿着手机上下晃动(up_anddown)动作状态30条左右,如下图所示。
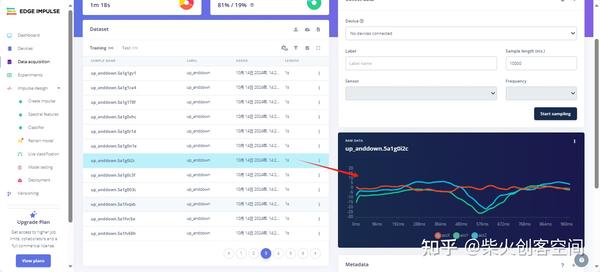
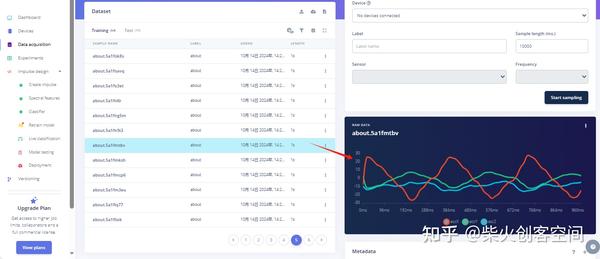
- 最后采集左右晃动(about)动作状态30条左右,如下图所示。
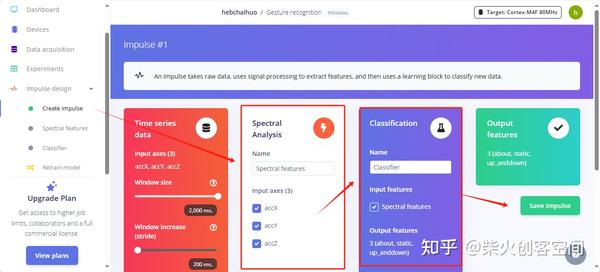
12、采集三个手势动作数据后,在左侧【MImpulse design】中单击【Create impulse】选项,添加“处理块”和“学习块”,添加标星号的推荐内容即可,最后单击【Save lmpulse】保持设置,如下图所示。
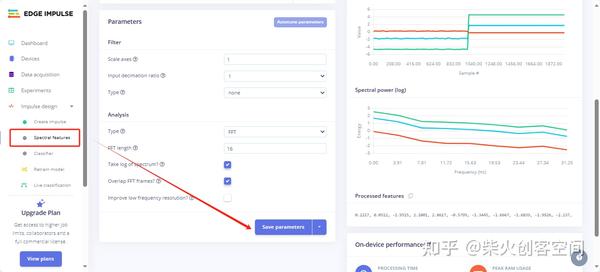
13、接着单击左侧的【Spectral features】选项,进入光盘分析页面后单击【Save parameters】按钮保存参数特征,如下图所示。
14、然后单击【Generate features】生成特征要素,经过一段时间会生成特征图,如下图所示。

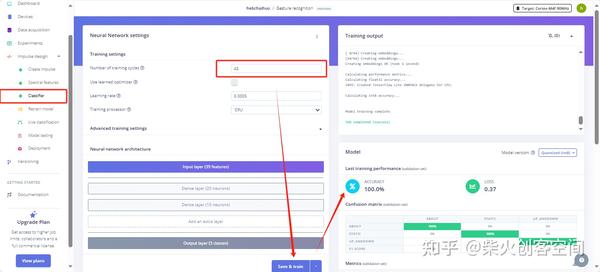
15、单击左侧的【Classifier】选项进入训练模型页面,设置训练周期数为“45”,然后单击【Save & train】按钮,开始进行模型训练经过一段时间后在页面的右侧会显示出模型的准确率和损失率等指标,如下图所示。
16、单击左侧的【Deployment】模型部署选项,进入模型部署页面,在选择框中选择“Arduino library”选项;在“MODEL OPTIMIZATIONS”模型优化选项中选择“TensorFlow Lite”,使用默认的“INT8”模式,最后单击底部的【Build】按钮,如下图所示。
https://smartphone.edgeimpulse.com/classifier.html?apiKey=ei_8e4a7b875e6eaad4d307f437646c572b51e85cbcb92dc241c7ec37e6f6030dcd&impulseId=1 (二维码自动识别)
- 在右侧的“Build output”选项中可以看到生成相应格式模型的过程和进度,完成模型后会弹出一个窗口提示如何添加Arduino模型库文件和预览案例文件,如下图所示。

- 同时会弹出提示Arduino模型库文件下载提示窗口,将其下载到特定文件夹中即可,如下图所示。
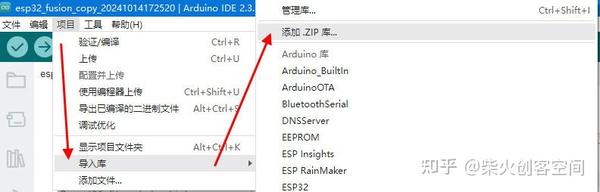
- 这样手势动作识别模型就训练完成并生成了支持Arduino的库文件,打开Arduino IDE软件选择【工具】-【导入库】-【添加zip库】添加此手势动作识别模型库文件,如下图所示。
- 导入模型库文件后会生成一个后缀为inferencing名字的库文件,在单击【文件】-【示例】-【后缀是inferencing名字的库文件】-【esp32】-【esp32_fusion】,打开此案例程序,如下图所示。

21、esp32_fusion案例程序是以基于 LIS3DHTR 芯片的三轴加速度传感器为例的,到这里需要先连接好相应的硬件,这里使用了一个XIAO ESP32 S3(Sense)开发板、一个XIAO扩展板和一个Grove - 3-Axis Digital Accelerometer (LIS3DHTR)三轴加速度传感器连接到一起。
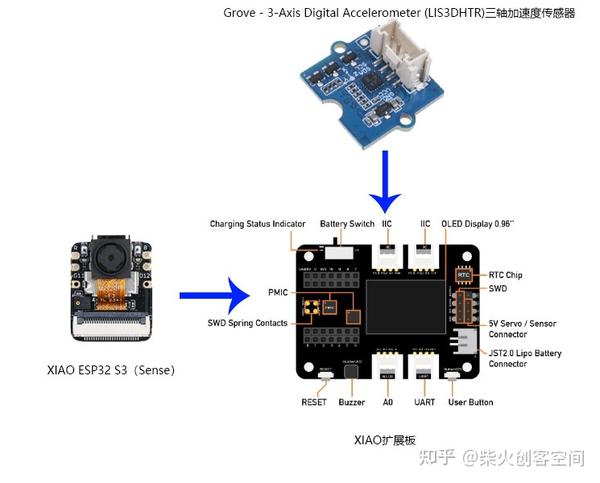
22、esp32_fusion案例程序如果无法启动或初始化Grove - 3-Axis Digital Accelerometer (LIS3DHTR)三轴加速度传感器,就需要修改下相应的代码,可以使用这个修改过的案例程序试试。
具体程序代码请在网盘中下载查看
https://share.weiyun.com/QHhHzmbz
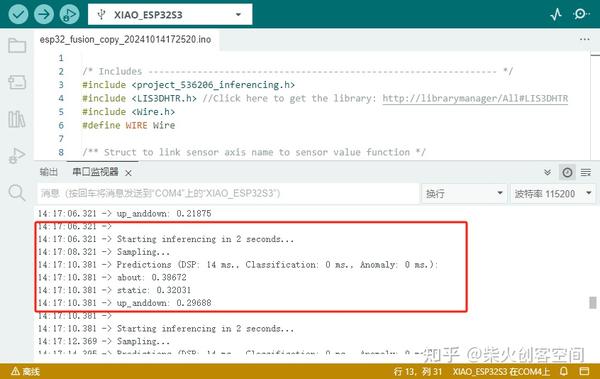
23、将相关硬件连接好并用数据线将XIAO ESP32 S3(Sense)开发板与电脑的USB接口连接后,开始上传此程序(备注:如果上传失败在工具菜单中,请打开PSRAM功能),上传成功后打开串口监视器可以看到三轴加速度初始化成功,并输出三个类别名称和置信率等信息,如下图所示。
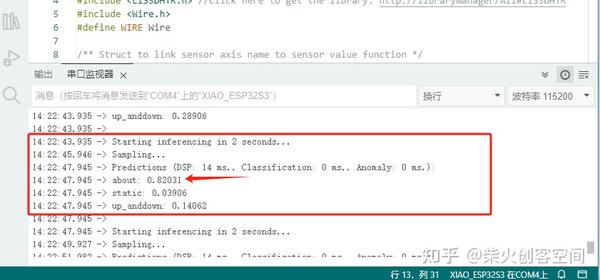
24、手里拿手机并左右或上下摇晃,通过串口可以观察到about或up_anddown这两个类别后面的值会改变,这个值就是预测结果的置信率,比如0.8就代表80%的预测结果是这个类别。
模型推理演示,请看如下视频。
手势动作识别功能演示
XIAO ESP32S3 Sense 套装介绍

XIAO ESP32S3(Sense)
强大的 MCU 板:集成ESP32S3 32 位双核 Xtensa 处理器芯片,运行频率高达 240 MHz,安装多个开发端口,支持 Arduino/MicroPython
高级功能:可拆卸OV2640相机传感器,分辨率为1600*1200,兼容OV5640相机传感器,集成附加数字麦克风
超强内存,带来更多可能性:提供 8MB PSRAM 和 8MB 闪存,支持 SD 卡插槽,用于外部 32GB FAT 内存
出色的射频性能:支持2.4GHz Wi-Fi和BLE双无线通信,连接U.FL天线时支持100m+远程通信
拇指大小的紧凑型设计:21 x 17.5mm,采用XIAO的经典外形,适用于可穿戴设备等空间有限的项目
来自 SenseCraft Al 的用于无代码部署的预训练 Al 模型。
写在最后
SenseCraft-AI平台的模型仓数量还很少,但是好消息是它支持自定义模型上传并输出推理结果,平台会逐渐增加模型仓的数量,敬请关注!

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









