










一、什么是决策树?
决策树(Decision Tree)是一种非常经典的分类器,设计出来就是用来做分类的,就算之后被开发成也可以用来做回归,但是其实也是将数值区间看成一个类别来做。
因其扩展通过节点的类别情况,每个类别会导致一个结果,将这个过程用图示的方式表示,很像一棵树,所以称为决策树。
二、如何构建决策树?
决策树是一种监督学习算法,每个样本都有多个属性和一个类别,根据样本进行学习,通过样本的属性能够最后得到样本的类别,然后可以对只给出属性的数据进行类别的预测。
从根节点开始,每次扩展节点都根据该节点的类别情况来扩展。每个节点可能的类别情况有1个、2个或者多个。
- 如果节点的类别只有1个,则该节点为纯节点,即该节点下的所有样本都是同一个类别,该类节点不需要再进行扩展。
- 如果节点的类别有2个,则根据这两个类别可以生长出2个分支,若整棵决策树的每个非叶子节点都是2个分支,这样的树中最典型的被称为CART(Classification And Regression Tree),即分类与回归树。
- 如果节点的类别有多个,则可以生长出多个分支,这样的树中典型的有ID3、C4.5和C5.0等,可以发现,多个分支也可以用2个分支的方式去进行处理,所以C4.5等可以转化为CART。
三、举例
我自己乱写了个数据集来模拟决策树的创建过程。
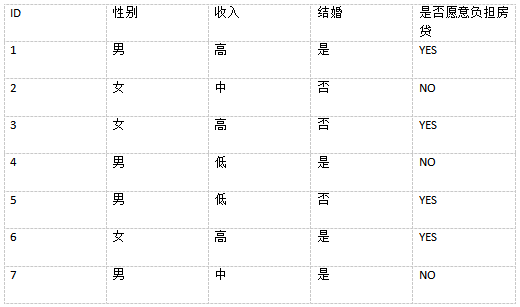
决策树的构建需要一组特征以及一个目标类别,上表中的特征为(性别,收入,结婚),目标类别为(是否意愿负担房贷)。
对上表数据集采用最经典的决策树来做的话,其构建过程如下图
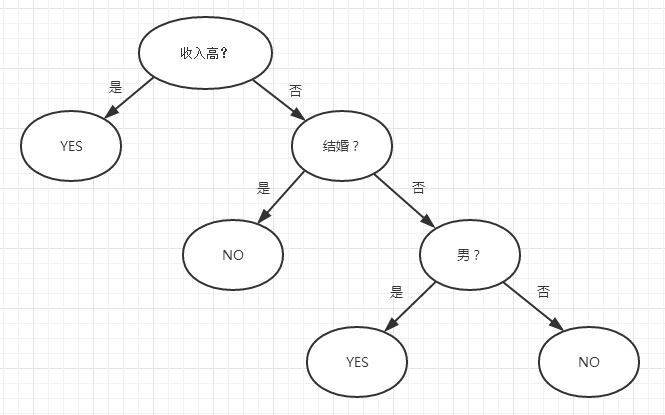
可见经过3次决策,就完全将7个样本很好的适配进该决策树中,每个叶子节点都是纯节点。
四、思考
经过上述的简单的一个决策树过程,可以看出决策树可以很好的决策一些分类问题,但是也有一些问题可以进行思考。
(一)如何做数值型的回归决策?
决策树被设计出来就是用与做分类的,那连续的数值型数据显然要做分类需要进行处理。ID3这种决策树就不能用于做数值型的回归,它专注于做分类决策。而C4.5和CART均可以做数值型的回归。具体可以参考后篇。
(二)如何优化决策树,让决策树变得小但是适用?即如何进行剪枝?
剪枝分为前剪枝和后剪枝。前剪枝强调剪枝在决策树的创建过程中进行剪枝,后剪枝在决策树完全生成之后再根据情况进行剪枝,后剪枝比较常用,具体方法可以参考后篇。
(三)如何防止过度拟合,防止决策树只在训练样本上精度高,而测试样本上精度低?
过度拟合是决策树中需要解决的最大的问题,一旦过度拟合,那其实这棵决策树就没有什么用处。过度拟合可以通过限制决策树的最大层数和限制规则的数量来处理,比如上图,我限制最大层数为2,则到结婚那一步就不再进行生长,显然这样可以很好的防止过度拟合,但是显然牺牲了一些预测的精度。而防止过度拟合就是要在精度和过度拟合之间找到一个平衡。
(四)什么时候停止决策树生长?
最明显的,当某个节点的纯度达到最高时,自然决策树就停止生长了。但是就带来了过度拟合的问题。解决的办法可以在节点的纯度上设置一个阈值,达到一定阈值就停止生长,那么该节点中占比最大的那个类别就被当作是该节点的类别。















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









