









欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、机器学习技术感兴趣的同学加入。
今天具体介绍一个Google DeepMind在15年提出的Spatial Transformer Networks,相当于在传统的一层Convolution中间,装了一个“插件”,可以使得传统的卷积带有了[裁剪]、[平移]、[缩放]、[旋转]等特性;理论上,作者希望可以减少CNN的训练数据量,以及减少做data argument,让CNN自己学会数据的形状变换。这篇论文我相信会启发很多新的改进,也就是对卷积结构作出更多变化,还是比较有创意的。
背景知识:仿射变换、双线性插值
在理解STN之前,先简单了解一下基本的仿射变换、双线性插值;其中,双线性插值请跳转至我刚刚写的一篇更详细的介绍“三十分钟理解:线性插值,双线性插值Bilinear Interpolation算法”。这里只放一个示意图[1]:

而仿射变换,这里只介绍论文中出现的最经典的2D affine transformation,实现[裁剪]、[平移]、[缩放]、[旋转],只需要一个[2,3]的变换矩阵:
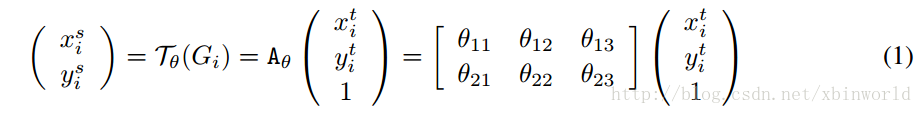
对于平移操作,仿射矩阵为:
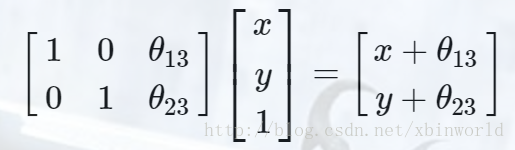
对于缩放操作,仿射矩阵为:
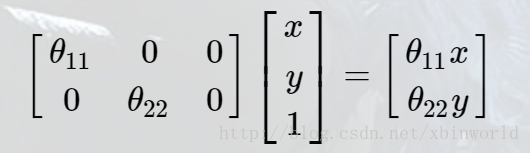
对于旋转操作,设绕原点顺时针旋转αα度,坐标仿射矩阵为:
(这里有个trick,由于图像的坐标不是中心坐标系,所以只要做下Normalization,把坐标调整到[-1,1])[1]
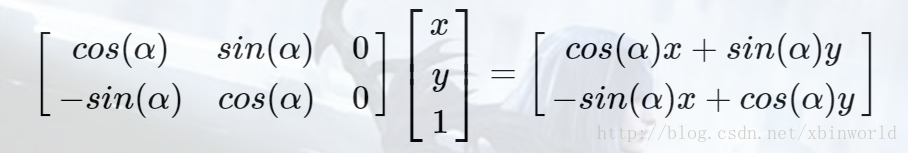
至于裁剪(Crop)操作,作者在论文中提到:
determinant of the left 2×2 sub-matrix has magnitude less than unity
其实作用就是让变换后的坐标范围变小了,这样就相当于从原图中裁剪出来一块;
Spatial Transformer Networks
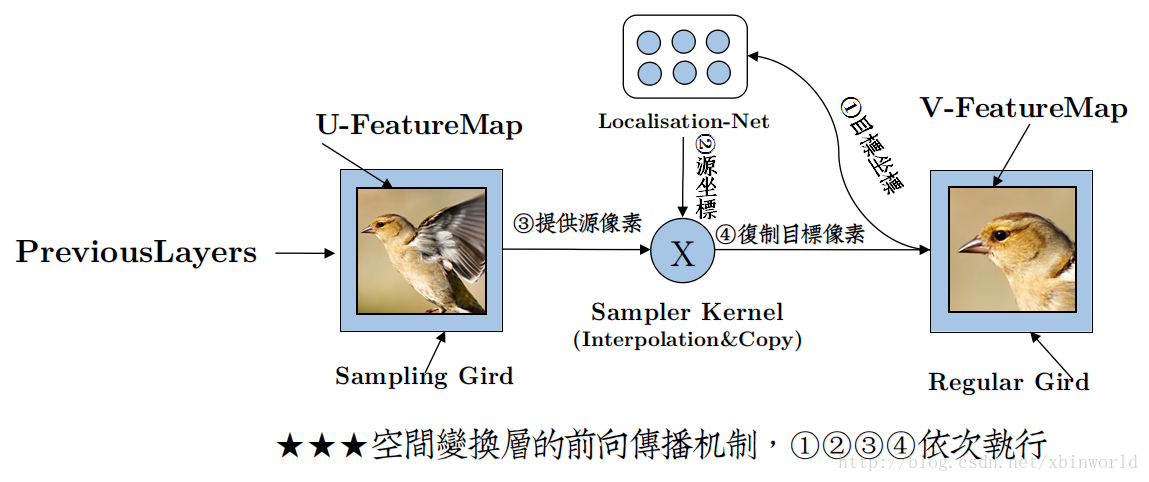
OK,开始讲正题。论文中作者讲的比较简略,所以初看有点费劲,而且我看了网上很多资料,很对博主自己也没有理解清楚。最主要的结构图,还是这张:
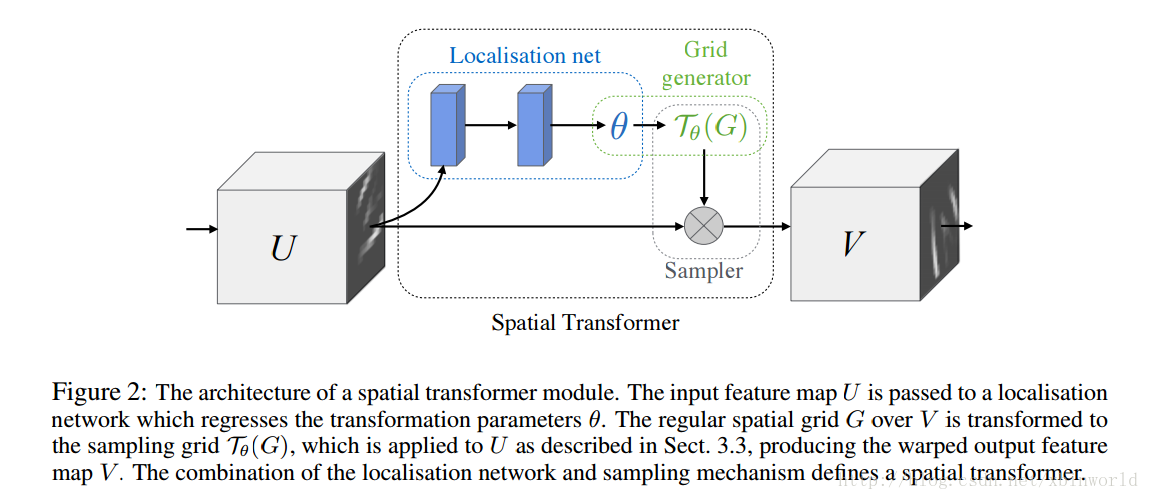
图1 STN架构
按照作者的说法,STN可以被安装在任意CNN的任意一层中——这里有些同学有误解,以为上图中U到V是原来的卷积,并且在卷积的路径上加了一个分支,其实并不是,而是将原来的一层结果U,变换到了V,中间并没有卷积的操作。看下图右边,通过U到V的变换,相当于又生成了一个新数据,而这个数据变换不是定死的而是学习来的,即然是学习来的,那它就有让loss变小的作用,也就是说,通过对输入数据进行简单的空间变换,使得特征变得更容易分类(往loss更小的方向变化)。另外一方面,有了STN,网络就可以动态地做到旋转不变性,平移不变性等原本认为是Pooling层做的事情,同时可以选择图像中最终要的区域(有利于分类)并把它变换到一个最理想的姿态(比如把字放正)。
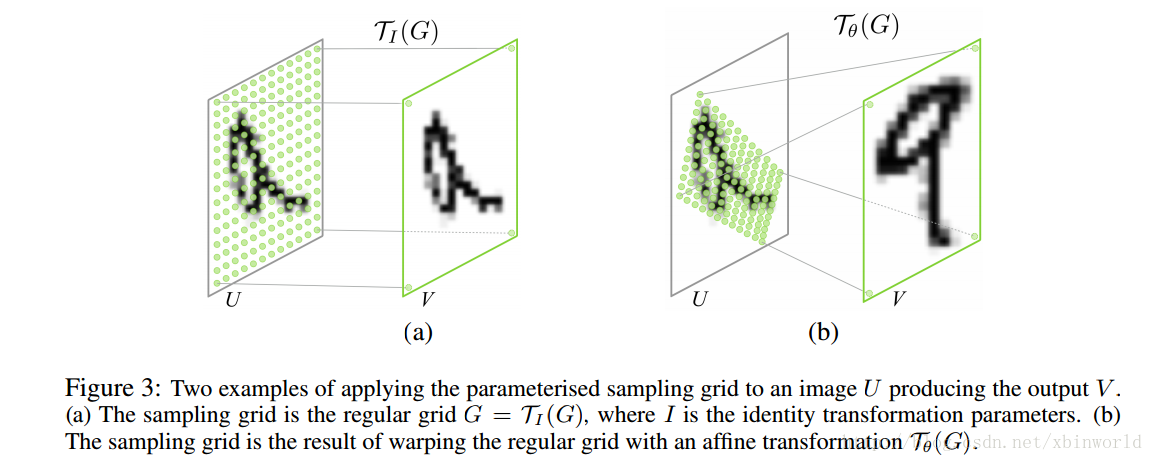
再回到前面图1 STN架构中,分为三个部分:
- Localisation net
- Grid generator
- Sampler
Localisation net
把feature map U作为输入,过连续若干层计算(如卷积、FC等),回归出参数
θ
,在我们的例子中就是一个[2,3]大小的6维仿射变换参数,用于下一步计算;
Grid generator
名字叫grid生成器,啥意思?理解了这个名字就理解了这一步做啥了——在source图中找到用于做插值(双线性插值)的grid。这也是很多人理解错的地方。仔细看下前面公式1:
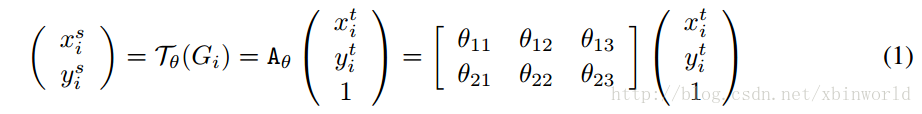
s表示source(U中的坐标),t表示target(V中的坐标)。是不是很奇怪?因为前向计算中,是已知U的,而这个公式怎么是把V做变换呢?——其实这里的意思是,通过仿射变换,找到目标V中的坐标点变换回source U中的坐标在哪里,而V这时候还没有产生,需要通过下一层采样器sampler来产生。
Sampler
作者也叫这一步Differentiable Image Sampling,是希望通过写成一种形式上可微的图像采样方法,目的是为了让整个网络保持可以端到端反向传播BP训练,用一种比较简洁的形式表示双线性插值的公式:
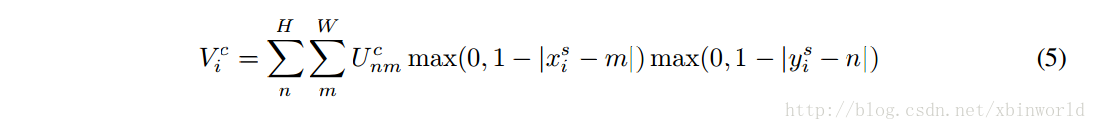
和最前面双线性插值的示意图含义是一样的,只是因为在图像中,相邻两个点的坐标差是1,就没有分母部分了。而循环中大部分都没用的,只取相邻的四个点作为一个grid。
所以上面 2. Grid generator和 3. Sampler是配合的,先通过V中坐标
(xtarget,ytarget)
以此找到它在U中的坐标,然后再通过双线性插值采样出真实的像素值,放到
(xtarget,ytarget)
。到这里一层STN就结束了。最后再借用一张[1]作者的示意图作为总结,还是比较清楚的(当然,[1]中作者写的有些理解我看下来也有不准确的,里面的评论区也有讨论,读者自己鉴别一下)。
OK,本文就讲到这里,基本上前向过程都提到了,论文中还有关于求导(因为Sampler不连续,只能求Sub-Gradient)和训练loss的一些内容,推荐读者再结合论文看一下,这里不写了。另外,希望写博客的同学自己能够多理解清楚一点再写,不要随便糊弄一下~~~
欢迎转载,注明出处即可。预告一下,下一篇讲一下最新MSRA的deformable convolutional network,和STN有很多相似的idea,也比较有意思。
参考资料
[1] http://www.cnblogs.com/neopenx/p/4851806.html
[2] http://blog.csdn.net/shaoxiaohu1/article/details/51809605
[3] Spatial Transformer Networks, DeepMind,2015


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









