







参考:http://blog.csdn.net/dongtingzhizi/article/details/15962797
http://blog.csdn.net/jackie_zhu/article/details/8895270
http://www.cnblogs.com/arachis/p/LR.html
http://www.cnblogs.com/fclbky/p/5408796.html
http://blog.csdn.net/acdreamers/article/details/44663305
http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
http://mp.weixin.qq.com/s?__biz=MzI3NzM1ODU0OA==&mid=2247484131&idx=1&sn=6f7f386e1340992dd5dee7be84391ed6&chksm=eb663058dc11b94e9e0c3c887f645d3ee5e13cb301810bbd1b6e0ceed858b1f314cd250829c1&mpshare=1&scene=1&srcid=0320FPNMvSx8LQtRinVkruJh#rd
1.引言
看了Stanford的Andrew Ng老师的机器学习公开课中关于Logistic Regression的讲解,然后又看了《机器学习实战》中的LogisticRegression部分,写下此篇学习笔记总结一下。
首先说一下我的感受,《机器学习实战》一书在介绍原理的同时将全部的算法用源代码实现,非常具有操作性,可以加深对算法的理解,但是美中不足的是在原理上介绍的比较粗略,很多细节没有具体介绍。所以,对于没有基础的朋友(包括我)某些地方可能看的一头雾水,需要查阅相关资料进行了解。所以说,该书还是比较适合有基础的朋友。
本文主要介绍以下三个方面的内容:
(1)Logistic Regression的基本原理,分布在第二章中;
(2)Logistic Regression的具体过程,包括:选取预测函数,求解Cost函数和J(θ),梯度下降法求J(θ)的最小值,以及递归下降过程的向量化(vectorization),分布在第三章中;
(3)对《机器学习实战》中给出的实现代码进行了分析,对阅读该书LogisticRegression部分遇到的疑惑进行了解释。没有基础的朋友在阅读该书的Logistic Regression部分时可能会觉得一头雾水,书中给出的代码很简单,但是怎么也跟书中介绍的理论联系不起来。也会有很多的疑问,比如:一般都是用梯度下降法求损失函数的最小值,为何这里用梯度上升法呢?书中说用梯度上升发,为何代码实现时没见到求梯度的代码呢?这些问题在第三章和第四章中都会得到解答。
文中参考或引用内容的出处列在最后的“参考文献”中。文中所阐述的内容仅仅是我个人的理解,如有错误或疏漏,欢迎大家批评指正。下面进入正题。
2. 基本原理
Logistic Regression和Linear Regression的原理是相似的,按照我自己的理解,可以简单的描述为这样的过程:
(1)找一个合适的预测函数(Andrew Ng的公开课中称为hypothesis),一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程时非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
3. 具体过程
3.1 构造预测函数
Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法,用于两分类问题(即输出只有两种)。根据第二章中的步骤,需要先找到一个预测函数(h),显然,该函数的输出必须是两个值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
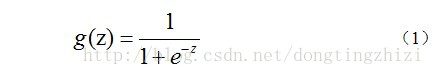
对应的函数图像是一个取值在0和1之间的S型曲线(图1)。
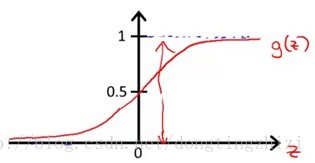
图1
接下来需要确定数据划分的边界类型,对于图2和图3中的两种数据分布,显然图2需要一个线性的边界,而图3需要一个非线性的边界。接下来我们只讨论线性边界的情况。
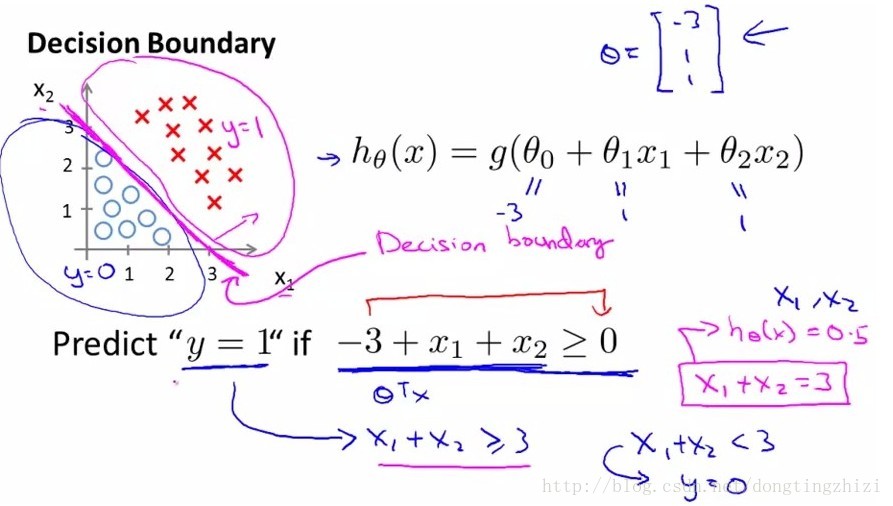
图2

图3
对于线性边界的情况,边界形式如下:
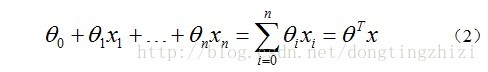
构造预测函数为:
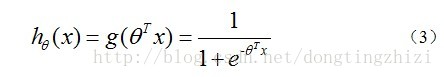
hθ(x)函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
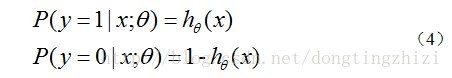
3.2 构造Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。
稍微解释下这个损失函数,或者说解释下对数似然损失函数:
当y=1时,假定这个样本为正类。如果此时hθ(x)=1,则单对这个样本而言的cost=0,表示这个样本的预测完全准确。那如果所有样本都预测准确,总的cost=0 但是如果此时预测的概率hθ(x)=0,那么cost→∞。直观解释的话,由于此时样本为一个正样本,但是预测的结果P(y=1|x;θ)=0, 也就是说预测 y=1的概率为0,那么此时就要对损失函数加一个很大的惩罚项。当y=0时,推理过程跟上述完全一致,不再累赘。
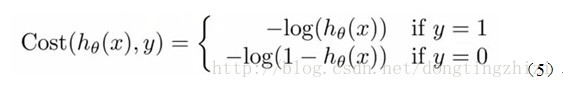
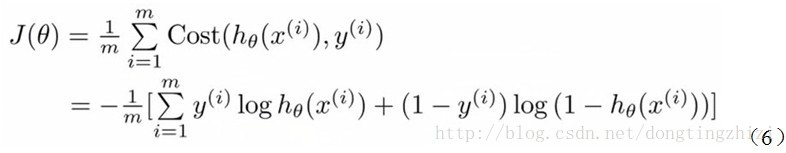
实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的。下面详细说明推导的过程。(4)式综合起来可以写成:
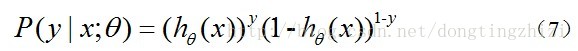
取似然函数为:
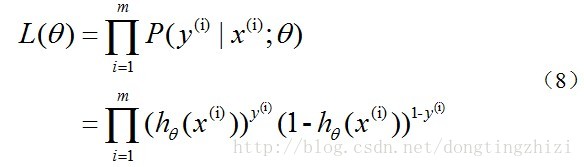
对数似然函数为:
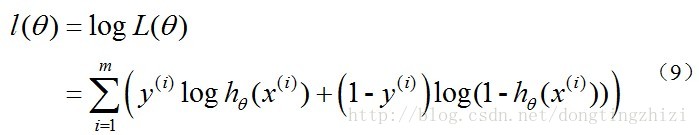
最大似然估计就是要求得使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将J(θ)取为(6)式,即:

因为乘了一个负的系数-1/m,所以J(θ)取最小值时的θ为要求的最佳参数。
3.3 梯度下降法求J(θ)的最小值
求J(θ)的最小值可以使用梯度下降法,根据梯度下降法可得θ的更新过程:
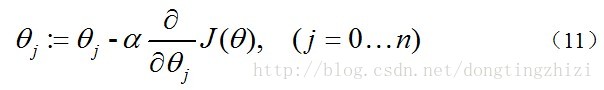
式中为α学习步长,下面来求偏导:
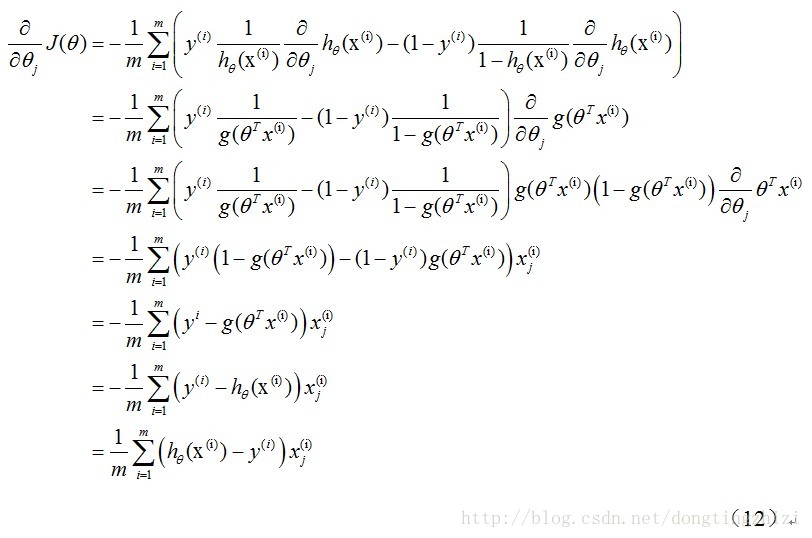
上式求解过程中用到如下的公式:
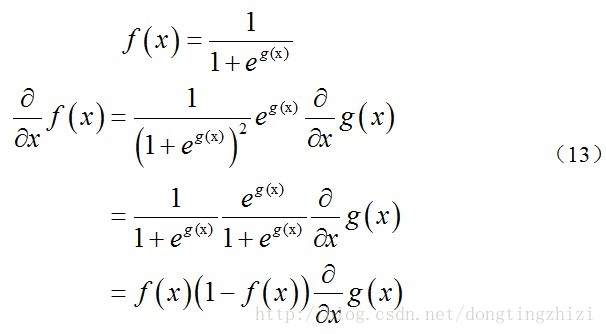
因此,(11)式的更新过程可以写成:
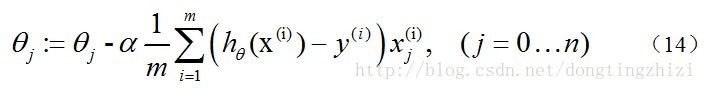
因为式中α本来为一常量,所以1/m一般将省略,所以最终的θ更新过程为:
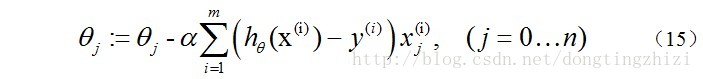
另外,补充一下,3.2节中提到求得l(θ)取最大值时的θ也是一样的,用梯度上升法求(9)式的最大值,可得:
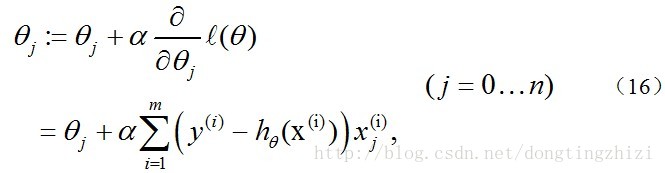
观察上式发现跟(14)是一样的,所以,采用梯度上升发和梯度下降法是完全一样的,这也是《机器学习实战》中采用梯度上升法的原因。
3.4 梯度下降过程向量化
关于θ更新过程的vectorization,Andrew Ng的课程中只是一带而过,没有具体的讲解。
《机器学习实战》连Cost函数及求梯度等都没有说明,所以更不可能说明vectorization了。但是,其中给出的实现代码确是实现了vectorization的,图4所示代码的32行中weights(也就是θ)的更新只用了一行代码,直接通过矩阵或者向量计算更新,没有用for循环,说明确实实现了vectorization,具体代码下一章分析。
文献[3]中也提到了vectorization,但是也是比较粗略,很简单的给出vectorization的结果为:
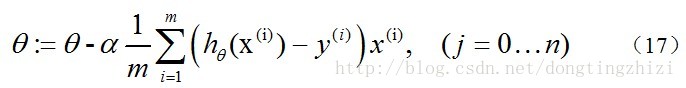
且不论该更新公式正确与否,这里的Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization,不像《机器学习实战》的代码中一条语句就可以完成θ的更新。
下面说明一下我理解《机器学习实战》中代码实现的vectorization过程。
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:
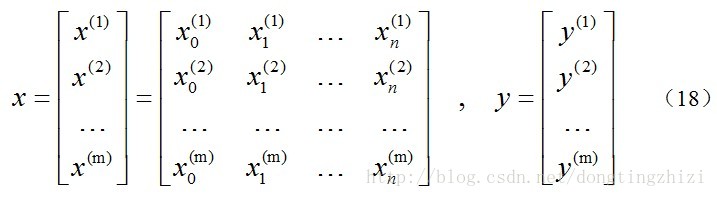
约定待求的参数θ的矩阵形式为:
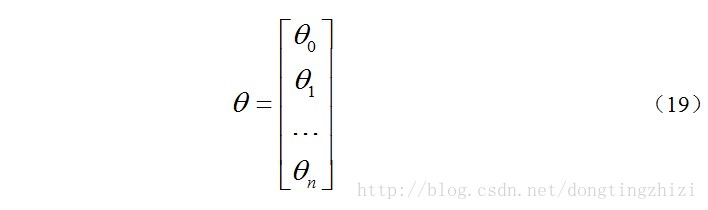
先求x.θ并记为A:

求hθ(x)-y并记为E:
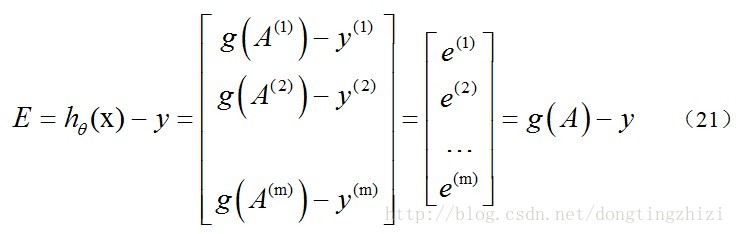
g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知hθ(x)-y可以由g(A)-y一次计算求得。
再来看一下(15)式的θ更新过程,当j=0时:
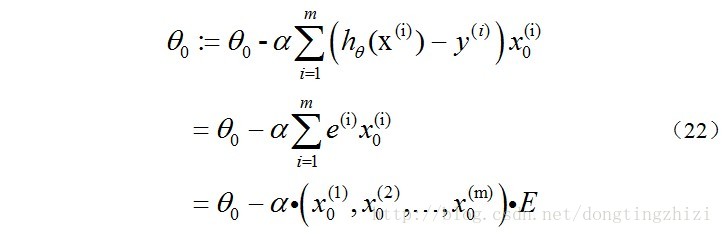
同样的可以写出θj,
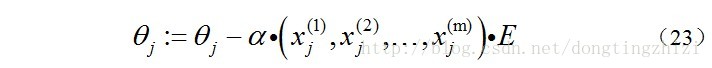
综合起来就是:
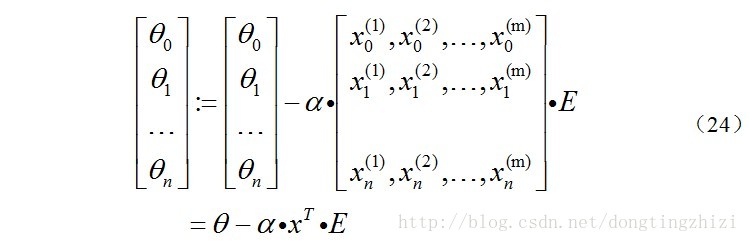
综上所述,vectorization后θ更新的步骤如下:
(1)求A=x.θ;
(2)求E=g(A)-y;
(3)求θ:=θ-α.x'.E,x'表示矩阵x的转置。
也可以综合起来写成:
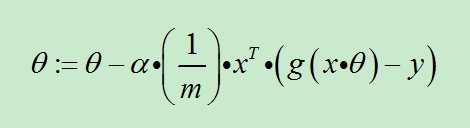
前面已经提到过:1/m是可以省略的。
4. 代码分析
图4中是《机器学习实战》中给出的部分实现代码。
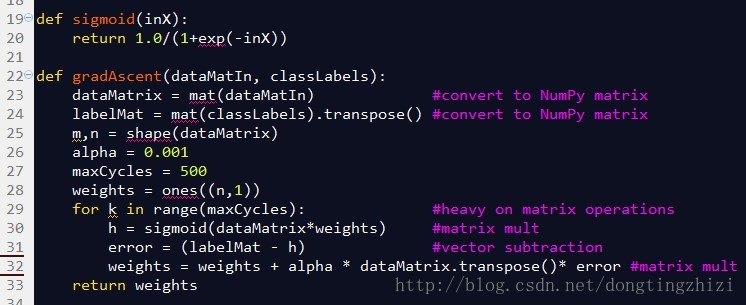
图4
sigmoid函数就是前文中的g(z)函数,参数inX可以是向量,因为程序中使用了Python的numpy。
gradAscent函数是梯度上升的实现函数,参数dataMatin和classLabels为训练数据,23和24行对训练数据做了处理,转换成numpy的矩阵类型,同时将横向量的classlabels转换成列向量labelMat,此时的dataMatrix和labelMat就是(18)式中的x和y。alpha为学习步长,maxCycles为迭代次数。weights为n维(等于x的列数)列向量,就是(19)式中的θ。
29行的for循环将更新θ的过程迭代maxCycles次,每循环一次更新一次。对比3.4节最后总结的向量化的θ更新步骤,30行相当于求了A=x.θ和g(A),31行相当于求了E=g(A)-y,32行相当于求θ:=θ-α.x'.E。所以这三行代码实际上与向量化的θ更新步骤是完全一致的。
总结一下,从上面代码分析可以看出,虽然只有十多行的代码,但是里面却隐含了太多的细节,如果没有相关基础确实是非常难以理解的。相信完整的阅读了本文,就应该没有问题了!^_^。
Logistic Regression 的损失函数(对数损失):

5.过拟合问题以及解决方法(Regularization)
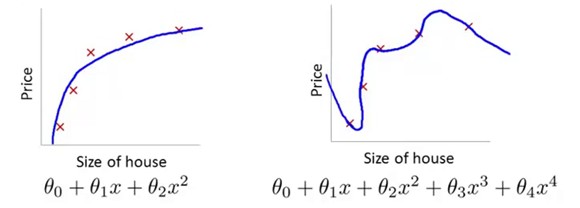
下面三个例子中,二是拟合的比较好的,一中有着较大的MSE,不是很好的模型,这种情况叫做 under fit,第三种情况虽然准确得拟合了每一个样本点,但是它的泛华能力会很差,这种情况叫做overfit。
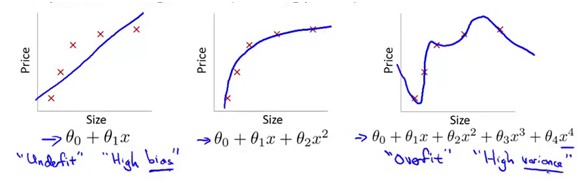
在LogisticRegression中,上面三种情况对应的就是
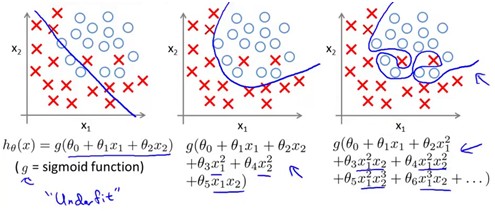
Underfit和Overfit是实践过程中需要避免的问题,那么如何避免过拟合问题呢?
第一种方法就是减少feature,上面的例子中可以减少x^2这样的多项式项。
第二种方法就是这里要介绍的Regularization,Regularization是一种可以自动减少对预测结果没有影响(或影响较小)的feature的方法。
在下面这个例子中,如果我们学习得到theta3和theta4都是0或者非常接近于0,那么x的三次方项和四次方项这两个feature可以忽略,而得到的模型就是左边这个。
方法就是在原来的J后面加上惩罚项lambda*theta^2,这个例子中
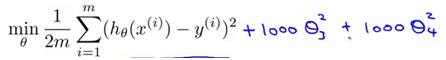
优化过程中就会使得theta3和theta4尽量小,从而加惩罚因子的这些feature对模型的影响越小。
加上lambda后面的惩罚项(regularization parameter),这样就得到了Regularization后的新的模型
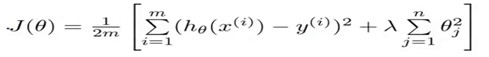
这里惩罚项式从1开始到n的,没有把0加进去,事实上,把0加进去对结果的影响非常小。
还有一个就是惩罚项系数lambda的选取问题,如果lambda选取的过大,那么最后的theta会接近于0,那么分割的曲线就会接近于直线,从而导致underfit(因为如果lambda非常非常大,要得到和前面的(h-y)相当大小的数值theta里面的所有元素就要很小),如果lambda过小,就相当于没有惩罚项,就是overfit。
求偏导后,梯度下降法中的更新式就变成了

多分类模型softmax regression











Hessian
矩阵也不可逆,是一个非凸函数,那么可以通过添加一个权重衰减项来修改代价函数,使得代价函数是凸函数,并且
得到的Hessian矩阵可逆。更多详情参考如下链接。
链接:http://deeplearning.stanford.edu/wiki/index.PHP/Softmax%E5%9B%9E%E5%BD%92
权重衰减
我们通过添加一个权重衰减项  来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }} \right] + \frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^n \theta_{ij}^2\end{align}](https://i-blog.csdnimg.cn/blog_migrate/bc700706ad83bdf7e6b610573463ffb1.png)
有了这个权重衰减项以后 ( ),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为
),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为 是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 的导数,如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} ( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) ) \right] } + \lambda \theta_j\end{align}](https://i-blog.csdnimg.cn/blog_migrate/1e2bd9b5ae929e485dc03f413d9e163f.png)
通过最小化 ,我们就能实现一个可用的 softmax 回归模型。
算法特性及优缺点
LR分类器适用数据类型:数值型和标称型数据。
可用于概率预测,也可用于分类。
其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高。
各feature之间不需要满足条件独立假设(相比NB),但各个feature的贡献是独立计算的(相比DT)。
注意事项
步长a的选择:值太小则收敛慢,值太大则不能保证迭代过程收敛(迈过了极小值)。
归一化:多维特征的训练数据进行回归采取梯度法求解时其特征值必须做scale,确保特征的取值范围在相同的尺度内计算过程才会收敛
最优化方法选择:L-BFGS,收敛速度快;(这个不太懂)
正则化:L1正则化可以选择特征,去除共线性影响;损失函数中使用了L1正则化,避免过拟合的同时输出稀疏模型;
(来自http://scikit-learn.org/stable/modules/linear_model.html#logistic-regression)
实现和具体例子
Logistic回归的主要用途:
-
寻找危险因素:寻找某一疾病的危险因素等;
-
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
- CTR预测:http://www.flickering.cn/uncategorized/2014/10/转化率预估-2逻辑回归技术/?utm_source=tuicool&utm_medium=referral
- 官网使用LR L1正则项进行特征选择的例子:https://github.com/Tongzhenguo/Python-Project/blob/master/learntoscikit/LRforFeatureSelect.py
- 一个银行风控的例子:http://www.weixinla.com/document/44745246.html
适用场合
是否支持大规模数据:支持,并且有分布式实现
特征维度:可以很高
是否有 Online 算法:有(参考自)
特征处理:支持数值型数据,类别型类型需要进行0-1编码
【参考文献】
[1]《机器学习实战》——【美】Peter Harington
[2] Stanford机器学习公开课(https://www.coursera.org/course/ml)
[3] http://blog.csdn.net/abcjennifer/article/details/7716281
[4] http://www.cnblogs.com/tornadomeet/p/3395593.html
[5] http://blog.csdn.net/moodytong/article/details/9731283
[6] http://blog.csdn.net/jackie_zhu/article/details/8895270















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









