







这段时间在看RBM的东西,很多材料都罗列了很多公式、理论,显得自己很牛B的样子。不过到具体实现,get hands dirty,就没有了。BS这种装B资料!张春霞《受限波尔兹曼机简介》(收录于“中国科技论文在线”)是介绍RBM不可多得的好材料,理清理论思路,容易具体实现,给出实现经验,挺好的。下面是我的阅读笔记,基本上都是摘抄论文中的内容。
0. 引言
讲了讲历史,RBM对DBN的模拟,从而带来了deep learning的革命。
1 受限波尔兹曼机RBM的基本模型
介绍0-1状态的BM和RBM,同一类单元的条件独立性,激活概率等。
2. 基于对比散度的RBM快速学习算法
RBM的任务就是对输入样本进行特征提取,提取的特征的好坏,表现在重构输入样本的时候,是否与原始样本足够相似。所以目标函数就是输入样本的似然函数。利用“同一类单元节点概率的独立性”,最终得到RBM更新公式为:
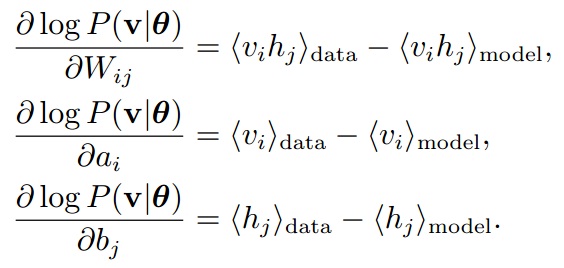
其中,<v_i, h_j>|model 的计算量是节点个数的指数级的函数,计算量太大,所以用CD-k算法。而CD-k的核心是用Gibbs采样来对<v_i, h_j>|model 进行模拟。
2.1 Gibbs采样
原理是基于Markov链的Monte Carlo(MCMC)方法。具体做法如下:

通过Gibbs采样,就<v_i, h_j>|reconstruct来代替<v_i, h_j>|model了。
2.2 CD-k算法
直接贴算法过程了,如下:

权值更新中,所需的各个变量都在Gibbs采样中计算了,直接带到算法去就行了。
在此基础上,还有很多算法改进。文中列出的有,持续对比散度(persistent contrastive divergence, PCD)算法,该算法不再使用Gibbs采样,且学习率是不断衰减的。进一步地,还有快速持续对比散度(fast persistent contrastive divergence, FPCD)算法。
3 RBM的参数设置
3.1 小批量数据及其容量
上面的CD算法是针对某一个特定的训练样本的,在实际过程中,可以采用一批训练样本,一方面加快训练速度,另一方面可以利用GPU的矩阵运算。那么批量选择多少个样本为好?文中说,如果RBM用在分类问题上,则批量样本尽量能保证每个类别的样本都有一个。
3.2 学习率
权重更新量为权重的10E-3倍左右。
3.3 权重和偏置的初始值
一般来讲,连接权重W可以初始化为正态分布N(0, 0.01)的数值。隐含单元的偏置,设置为零。显示单元的偏置,设置为log(p_i/(1-p_i)),其中p_i为第i个显示单元在训练样本中处于激活状态的比率。
3.4 动量学习率
类似BP算法中的动量设置。权重更新方向不仅仅和梯度有关系,而且和上一次更新的权重有关系。
k的值可以取0.5,到学习后期可以0.9。
3.5 权衰减
在目标函数中可以引入二项范数,作为惩罚项。
3.6 隐单元个数
文中建议估计数据的比特数,用这个数字乘以训练样本的个数,然后降低一个数量级,就是隐单元的个数。
4. RBM的评估算法
重构误差,已经足够好用了。就是重构的单元与真实的训练样本的平方差。
5. 基本RBM模型的变形算法
几个变形都比较玄,不是要用到的话,不用看。
完。















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









