
















3.5 The Vertex Shader(顶点着色器)
顶点着色器是图3.2中展示的功能性管线中的第一个阶段。由于这是第一个直接在编程者控制下的阶段,故而需要注意在这个阶段前发生了一些数据操作。在被DirectX称为是输入装配器(input assembler)中,一些数据流可以被编织在一起来构成顶点和图元的集合而发往管线。例如,一个物体对象可以用位置的数组和颜色的数组来表示。输入装配器可通过顶点的位置和颜色创建这个物体的三角形(或者线/点)。第二个物体可以使用同样的位置数组(以及不同的模型转换矩阵)和一个不同颜色数组来作为其表示。16.4.5小节会具体详细讨论数据表示相关的内容。在输入装配器中也有支持来执行实例化(instancing)。这允许物体被多次绘制(在每个实例中都有一些变化的数据),当然这些都在一次绘制调用(draw call)中。实例化的使用可以参考18.4.2小节。
一个三角形网格可以用用一组顶点来表示,每个顶点关系到模型表面上的一个特定的位置。除了位置信息外,每个顶点还包含一些可选的属性信息,例如颜色或者纹理坐标。表面法线也被定义在网格顶点上,这看起来是一个奇怪的做法。数学上,每个三角形都有一个明确定义的法线,看起来好像是直接将三角形法线用于着色是更加有意义的。然而,当渲染的时候,三角形网格经常被用作表示底层的曲面。顶点法线被用来表示表面的朝向,而不是去表示三角形网格本身。16.3.4小节将会探讨计算顶点法线的方法。图3.7展示了两种三角形网格表示曲面的侧视图,一个平滑而另一个有尖锐的折角。

图 3.7 三角形网格(黑色,且带有法线)的侧视图,表示曲面(红色)。左侧应用平滑顶点法线来表示一个平滑表面。右侧在中间的顶点处进行了复制并且赋予了两个法线,表示一个折角
顶点着色器是处理三角形网格的第一步。顶点着色器获取不到用来描述形成了哪些三角形的数据。就如它的名字那样,它专门处理传入的顶点。顶点着色器提供了一种方法来修改、创造或者忽略与每个三角形顶点相关的值,如它的颜色、法线、纹理坐标和位置。一般来说,顶点着色器程序会将顶点从模型空间转换到齐次裁剪空间(4.7小节)。至少,一个顶点着色器必须输出这个位置信息。
顶点着色器和我们之前描述的统一着色器几乎是一样的。每个传入的顶点被顶带你着色器程序处理,然后输出一串在三角形上或线上插值得到的值。顶点着色器无法创建或者是销毁顶点,并且由一个顶点产生的结果不能传入另一个顶点。由于每个顶点都是单独被处理的,GPU上的任意数量的着色器处理器可以并行应用到顶点的传入流。
输入组装通常被介绍为在顶点着色器执行前的一个过程。这是一个体现实际模型与逻辑模型不尽相同的例子。实际上,为创建顶点而进行的数据的获取可能发生在顶点着色器,驱动器会预先用一些合适的指令去处理每个着色器,而这些指令程序员是看不到的。
后面的章节会解释几种顶点着色器效果,例如服务于关节动画的顶点混合,轮廓渲染。顶带着色器的其他使用包括:
- 物体生成,通过创建一个一次性网格并且利用顶点着色器将它变形。
- 利用蒙皮和变形技术(skinning and morphing technology)制作角色身体和脸部动画。
- 程序化变形,例如旗子、衣服或者水的移动。
- 粒子创建,通过发送退化的网格到后面的管线并根据需要赋予他们一个区域。
- 镜头扭曲、热雾、水波纹、页面卷曲以及一些其他效果,通过使用整个帧缓冲作为一张纹理应用到经过程序变形的屏幕对齐网格上。
- 应用地面高度区域,通过使用顶点纹理获取。
图3.8中展示了一些使用顶点着色器做出的变形。

图 3.8 左边是一个普通的茶壶(teapot)。顶点着色器执行的一个简单的拉伸操作产生了中间的图像。右边,一个噪声函数创造了一个扭曲模型的区域。(图像由FX Composer 2制作,由NVIDIA公司提供)
顶点着色器的输出可以以多个不同的方式使用。通常的路径是到每个实例的将要被生成和光栅化的图元,如三角形,以及独立的被生成的将要发送到像素着色器程序以便继续处理的像素图元。在一些GPU上,数据也可以被发送到曲面细分阶段或者几何阶段或者存储在内存中。这些可选的阶段会在下面的章节中进行讨论。
3.6 The Tessellation Stage(曲面细分阶段)
曲面细分阶段允许我们渲染曲面。GPU的任务是去获取每个表面的描述,把他们转换为有代表性三角形组。这个阶段是一个可选的GPU功能,它最早是在DirectX 11中可用的。它也受到OpenGL 4.0和OpenGL ES 3.2的支持。
使用曲面细分还是有一些优势的。对曲面进行描述往往比提供对应的三角形要更加复杂。除了节省内存,这个功能可以保证CPU到GPU之间的传输不会出现瓶颈,尤其是对那些形状每帧都在发生改变的动画角色或是物体。
表面可以被高效得渲染,通过选取一个合适的给定视野生成的三角形的数量。可能用很多三角形来表现细节看起来很棒。这个控制多层次细节(level of detail,LOD)的能力也可以应用到控制其性能上,例如,在相对没那么强大的GPU上使用一个低质量的网格来保证帧率。通常用平面表现的模型可以转换为更细的三角形网格,然后根据需要进行卷曲,或者他们可以被进一步细分去减少执行昂贵的着色计算的频率。
曲面细分阶段总是包含三个元素。使用DirectX的术语的话,他们分别可以表述为壳着色器(hull shader),曲面细分器(tessellator),和域着色器(domain shader)。在OpenGL里hull shader就是细分控制着色器(tessellation control shader)而域着色器就是细分评估着色器(tessellation evaluation shader),更加详尽的表述,但是也很冗长。固定功能的曲面细分器在OpenGL里被称为是图元生成器,字如其面,它这样起名字非常形象。
如何去指定和细分曲线和表面将会在17章中进行讨论。这里我们给出一个简短的每个细分阶段目的的介绍。首先,hull shader的输入是一类特殊的补缀(patch)图元。这包含了多个控制点来定义细分表面,贝泽尔曲面补缀(Béwier patch),或是其他曲元素的类型。hull shader有两个功能。首先,它告诉细分器应该生成多少三角形,以及是什么样的配置。然后,它在每个控制点上进行处理。另外,可选地,hull shader可以修改输入的补缀描述,根据意愿增加或者移动控制点。hull shader输出它的一些列的控制点,以及细分的控制数据,到域着色器,参照图3.9。

图 3.9 曲面细分阶段。hull shader获取由控制点定义的补缀。它发送曲面细分因子(tessellation factors,TFs)和类型到固定功能细分器
细分器在管线中是固定功能阶段,仅仅在曲面细分着色器中使用。它的任务是为域着色器提供一些新的顶点来进行处理。hull shader负责发送预期的细分表面类型相关的细分器信息:三角形(triangle),四边形(quadrilateral)或等值线(isoline)。等值线是一组线带,偶尔会用到头发渲染中。另外一个被hull shader发送的重要的值是细分因子(tessellation factors,在OpenGL中是tessellation levels)。这其中又有两类:内边和外边(inner and outer edge)。两个内因子决定在三角形和四边形内部发生多少的细分。外因子决定每个外边被细分为多少个(17.6小节)。图3.10展示了增加细分因子的例子。通过允许使用单独的控件,无论内部如何细分,我们都可以使相邻曲面的边缘在细分中匹配。匹配边缘可以避免在patch相遇之处出现裂缝或其他着色瑕疵。为顶点分配了重心坐标(第22.8节),这些值指定所需表面上每个点的相对位置。

图 3.9 改变细分因子的效果。尤他壶(Utah teapot)是由32个patch构成的。内部和外部细分因子,从左到右依次是1,2,4,8。(图片由Rideout和Gelder的演示项目中生成的)
hull shader总是输出一个patch,一组控制点的位置。但是,它可以通过向细分器发送0或更低(或非数字,NaN)的外部细分级别来作为信号,表示将要丢弃patch。否则,细分器会生成一个网格并将其发送到域着色器。hull shader输出的曲面的控制点被域着色器的每个调用用来去计算每个顶点的输出值。域着色器有一个数据流模板(类似于顶点着色器中的),其中每个细分器的输入顶点会被处理并且生成一个对应的输出顶点。构成的三角形会传入到后面的管线中。
虽然此系统听起来很复杂,但为提高效率而采用了这种结构,每个着色器都可以相对来说变得简单。传递到hull shader中的patch通常很少或根本不做修改。这个着色器可能也使用了patch的预估距离或者屏幕大小来快速计算细分因子,如对地形的渲染。或者,hull shader可以简单地为应用程序计算和提供的所有patch传递一组固定的值。细分器执行一个涉及到的但固定功能的过程,以生成顶点,为其指定位置并指定它们形成的三角形或直线。这个数据放大的步骤是在着色器外执行,以提升计算效率。域着色器获取为每个点生成的重心坐标,并在patch的估值方程中使用这些数据来生成位置、法线、纹理坐标以及其他的期望的顶点信息。图3.11展示了一个示例。
图 3.11 左边是一个大概6000个三角形的底层网格。右边,每个三角形被细分并且使用PN三角形细分(PN triangle subdivision)进行替换。(图片由NVIDIA SDK 11的样本提供,由NVIDIA公司贡献,模型来自由4A Game制作的Metro 2033)
3.7 The Geometry Shader(几何着色器)
几何着色器可以实现图元之间的转换,而这是曲面细分阶段无法做到的。例如,三角形网格可以被转换为线框视图,通过为每个三角形创建线边。或者,可以将这些线替换为面向观察者的四边形,从而使线框渲染的边缘更粗。在2006末,随着DirectX 10的发布,几何着色器也被添加到硬件加速的图形管线。它的位置位于曲面细分着色器的后面,并且它的使用不是必须的。虽然在Shader Model 4.0中它还是的必需部分,但是在较早的着色器模型中其实并未使用它。OpenGL 3.2和OpenGL ES 3.2也同样支持这个类型的着色器。
几何着色器的输入是单个物体及其相关联的顶点。物体通常包含带状三角形、线段、或者仅仅一个点。可以定义扩展的图元并且将其在几何着色器进行处理。特别是,可以传入三角形外部的三个附加顶点,并且可以使用折线上的两个相邻顶点。参考图3.12。在DirectX 11和Shader Model 5中,你可以传入精心制作的patch,最多包含32个控制点。这意味着,曲面细分阶段在patch的生成方面更加高效。
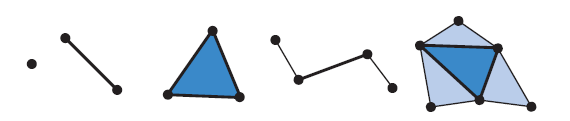
图 3.12 几何着色器程序的输入是一些单独的类型:点、线段、三角形。最右边的两个图元包括与直线和三角形对象相邻的顶点。更精细的patch类型也是可能的。
几何着色器处理了这个图元,并且输出0个或者多个顶点,他们可以被作为点、折线或三角形带而处理。请注意,几何着色器根本无法生成任何输出。在这种方式下,通过编辑顶点,增加新的图元,以及移除其中一些,网格可以被有选择地修改。
几何着色器被设计用来修改输入数据或者是创建有限数量的复制。例如,一种用法就是生成6个变换的数据的拷贝来渲染一个立方体映射的六个表面。参考10.5.3小节。也可以用于有效得创建级联阴影贴图以生成高质量阴影。其他的利用了几何着色器的算法包含创建从点数据创建变量控制的粒子,沿着轮廓拉伸飞边(fin)以进行毛发渲染,寻找物体边界以进行阴影算法。参考图3.13中的更多的相关例子。这些应用将在本书后面进行讨论。

图 3.13 几何着色器(GS)的一些应用。左侧,使用GS在运行时进行metaball等面的曲面细分。中间,使用GS完成线段的细分并将其输出,而GS生成billboard以显示雷电。右边,通过使用顶点和几何着色器的输出来进行布料的模拟。
DirectX 11为几何着色器增加了应用实例化的能力,这使得几何着色器可以在任何给定的图元上运行一定的次数。在OpenGL 4.0中这是通过调用计数指定的。几何着色器也可以输出四个流(stream)。可以在渲染管线上发送一个流来进一步处理。所有的这些流可以选择发送到流输出(stream output)渲染目标。
几何着色器需要保证图元的输出结果的顺序和他们的输入顺序是一致的。这会影响性能,因为如果多个着色器核心并行运行,结果必须被保存和排序。此因素以及一些其他因素不利于在单个调用中用于复制或创建大量几何图形的几何图形着色器。
发出绘制调用后,管道中只有三个位置可以在GPU上创建工作:光栅化,曲面细分,还有几何着色器。其中,在考虑需要的资源和内存时,几何着色器的行为是最不可预测的,因为它是完全可编程的。实际上,几何着色器通常使用得并不多,因为它不能与GPU的能力很好的匹配。在一些移动设备它是在软件中实现的,因此在此处并不鼓励它的使用。
3.7.1 Stream Output (流输出)
GPU管线的标准使用方法是通过顶点着色器发送数据,然后将输出的三角形光栅化并在像素着色器中对他们进行处理。曾经的情况是:数据经过整条管线,并且中间的结果并不能被访问到。流输出(stream output)的想法是在Shader Model 4.0中被引入的。在顶点着色器处理了顶点之后(并且,可选地,曲面细分和几何着色器),在被发送到光栅化阶段之前,这些顶点可以输出到一个流(stream)中,例如,有序数组。事实上,光栅化可以被完全关掉,从而管线被用作是一个非图像的流处理器。在这种方式下,被处理过的数据可以沿着管线发送回去,从而迭代处理。这种类型的操作对于模拟流动的水或者其他的粒子效果是非常有效的,13.8小节会进一步讨论。它也可以用来去为模型构建皮肤,当然这些顶点数据在之后任然是可供重用的(4.4小节)。
流输出返回的数据是浮点类型的数,所以它的内存消耗是不容忽视的。流输出是作用到图元上的,而不是直接到顶点上。如果网格发送到管线,每个三角形生成它自己独有的一组三个输出顶点。在初始网格的任何的顶点共享都会丢失掉。因为这个原因,一个更加普遍的用法是去仅仅在管线上发送顶点作为点集图元。在OpenGL里,流输出阶段被称为变换反馈(transform feedback),因为它的主要使用就是去变换顶点并将他们返回到更深一步的处理。要保障图元发送到流输出目标的顺序和他们的输入顺序是一致的,这意味着顶点的顺序也会保持。
3.8 The Pixel Shader(像素着色器)
在顶点、曲面细分、几何着色器执行完他们各自的操作之后,图元被裁剪和配置以便进行光栅化,这些在前面的章节都进行了一定的解释。在管线的处理步骤之中,这一段是相对来说固定的,也就是不可变成但是一定程度上可以进行配置。每个三角形都会被遍历,来决定它覆盖到具体哪些像素。光栅化器(rasterizer)可能也会去计算三角形在每个像素单元占据的区域大小(5.4.2小节)。三角形上的这一小块儿部分或者全部与像素重叠的部分就称为片元(fragment)。
三角形顶点上的值(包括在z-buffer中使用的z-value),为每一个像素在三角形表面上进行插值。这些值进入了像素着色器(pixel shader),这也是对片元进行处理的位置。在OpenGL中,像素着色器也被称为片元着色器(fragment shader),这也许是一个更加合适的名字。为了保持一致性,我们将会在整部书中使用“像素着色器”一词。流送到管线的点和线的图元也会为覆盖的像素创建片元。
在三角形上进行的插值计算的类型是由像素着色器程序进行指定的。通常,我们使用透视矫正插值法(perspective-correct interpolation),从而使像素表面位置之间的在世界空间内的距离随着对象后退距离的增加而增加。例如去渲染向地平线延申的铁路轨道。铁轨越远,轨道就会越紧密,因为接近地平线的像素的行进距离都越长。也有一些其他的插值算法,例如屏幕空间的插值,这里就不会去考虑透视投影。DirectX 11提供了一些选项,以进一步控制进行插值的时间和位置。
在编程方面,顶点着色器程序的输出,通过在三角形(或线)上进行插值,高效得转换成像素着色器程序得输入。随着GPU的发展,其他的输入也已公开。例如,在Shader Model 3.0及以上的版本中,片元的屏幕位置对于像素着色器也是可用的。此外,三角形的哪一侧可见是也是输入的标志。此信息对于在一个pass中在每个三角形的正面和背面渲染不同的材质非常重要。
有了输入,通常像素着色器可以计算和输出一个片元的颜色。它也可以去产生一个不透明度值(opacity value)并且可选择得调整它的z-depth。在混合阶段,这些值会被用来去修改像素内存储的信息。光栅化阶段生成的深度值也可以在像素着色器内进行修改。模板缓冲(stencil buffer)值通常是不可修改的,通常会直接传递到合并阶段。DirectX 11.3允许了着色器去修改这个值。在SM 4.0中,雾计算和alpha测试这些操作已经从合并操作移到像素着色器计算中去了。
像素着色器还拥有一项独特的能力——舍弃输入的片元,例如不去生成任何的输出。图3.14中展示了一个片元是如何舍弃掉的例子。裁剪平面的功能曾经是固定功能管线中一个可配置的元素,后面已经由顶点着色器执行了。有了片元丢弃功能之后,该功能便可以在像素着色器中以任何所需的方式实现,例如确定剪切量应进行“与”运算还是“或”运算。

图 3.14 用户定义的裁剪平面。在左边,一个单独的水平裁剪平面对物体进行了切割。在中间,三个平面对嵌套球体进行了裁剪。右侧,球体位于全部三个裁剪平面之外的表面受到了裁剪。(图片来自three.js的例子webgl_clipping和webgl_clipping_intersection)
一开始,像素着色器只能输出到合并阶段,以便最终显示出来。像素着色器可以执行的命令的数量随之时间的推移已经有了极大的增长。这个增长带来了一项新的概念的出现——多渲染目标(multiple render targets, MTR)。每个片元上都可以生成多组值并可以将他们保存到不同的缓冲区(他们被称为是渲染目标,render target)中,而不是直接将像素着色器的结果输出到颜色和深度缓冲中(z-buffer)。渲染目标们在x和y的尺寸上通常是一致的;一些API可以允许不同的尺寸出现,但是渲染的区域大小即是这些里面最小的那个。一些体系结构要求渲染目标必须具有相同的位深(bit depth),甚至可能需要具有相同的数据格式。渲染目标的可用数目是4或者是8,依据GPU不同而不同。
即时有着这些限制,MRT功能是一个更高效地执行渲染算法的强大助力。一个渲染pass可以在一个目标中生成彩色图像,在另一个目标中生成对象标识符,在第三个目标中生成世界空间距离。这项能力催生了另一个渲染管线类型——延迟渲染(deferred shading),其中的可见性处理和着色是在不同的pass中实现的。第一个pass在每个像素中存储关于物体位置和材料的数据。后面的pass可以高效得应用光照和一些其他的效果。这类渲染方法会在20.1小节中详细描述。
像素着色器的局限性在于,它通常只能在传递给渲染目标的片元位置上将数据写入渲染目标,而不能从相邻像素读取当前结果。这意味着,当像素着色器程序执行时,它不可以将它的输出直接发送给相邻像素,也不可以访问其他像素的最近的变动。即是,它只计算影响它当前像素的结果。然而,这个限制并没有看起来的那么严重。一次pass的输出图像可以让像素着色器在随后的一次访问中访问其任何数据。邻近像素可以使用图像处理技术进行处理,参见12.1小节中的描述。
像素着色器无法知晓或者影响邻近像素的结果,当然规则之外也有一些例外。其一就是像素着色器可以在计算梯度或导数信息时立即访问相邻片段的信息(尽管是间接的)。像素着色器被提供了沿x和y屏幕轴每个像素的任何插值变化的量。这个值在多种计算和纹理定位上都是有用的。这些梯度对于一些操作尤其重要,例如纹理过滤(6.2.2小节),其中我们想要知道多少图像覆盖一个像素。所有的现代GPU都是通过将片元处理成2x2的组(称为quad)来实现这个功能的。当像素着色器要求一个梯度值,就会返回一个邻近片元的差异。参考图3.15。一个统一的核心拥有访问邻近数据的能力——保存在同一warp上的不同线程中——因此可以像素着色器中用到的梯度。这种实现的一个结果是,无法在受动态流控制影响的着色器的某些部分(即,“ if”语句或具有可变迭代次数的循环)中访问渐变信息。所有同一个组内的片元必须使用相同的命令组进行处理,从而所有的四个像素结果对于计算梯度都是有意义的。这是个基本的限制,它甚至存在于离线渲染系统中。
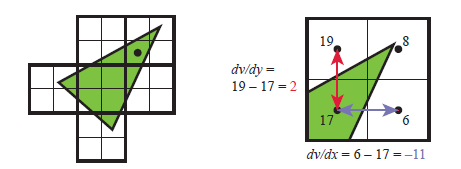
图 3.15 左侧,一个三角形被光栅化到四边形中,即2x2像素组中。在右侧图片中,像素的梯度计算被用一个点来标识。四个四边形的v值显示在了四边形的四个像素位置。请注意,三角形没有覆盖到其中的三个像素,但是它们仍会由GPU进行处理,以便可以找到梯度值。通过使用左下角像素的旁边的两个四边形,可以分别计算的得到x和y屏幕方向的梯度。
DirectX 11介绍了一个缓冲的类型,它允许写入任何位置的访问,即无序访问视图(unordered access view,UAV)。在DirectX 11Z中对UAV的访问扩展到了所有的着色器,原本上是只供像素着色器和计算着色器去访问的。OpenGL 4.3将这个称为是着色器存储缓冲对象(shader storage buffer object,SSBO)。两个名称都是从各自的角度对其所作的描述。像素着色器是并行以任意顺序运行的,而这个存储缓冲在他们之间共享。
通常会需要使用一些机制来避免数据竞争的情况(也就是数据危害),这种情况下两个着色器程序去争着影响同一个值,可能会导致一个随机的结果。例如,如果像素着色器的两个指令试图去在同一时间添加到相同的取回值(retrieved value),那么就会发生错误。两者都会取到相同的原始值,两者都会去在本地进行修改,但是之后无论是哪一条指令最后写入了结果,它都会擦除掉另一条指令写入的数据——只有一个命令会生效。GPU通过着色器可以访问的专用原子单元(atomic unit)来避免这个问题。然而原子意味着一些着色器可能需要停顿去等待对内存位置的访问,因为这段内存正在被其他的着色器读/修改/写入。
尽管原子可以避免数字危害,许多算法还是要求一个特殊的执行顺序。例如,你可能想要绘制一个较远的透明蓝色三角形,然后用另一个红色透明三角形覆盖它,即在蓝色之上混合红色。每个像素之上可能有着两次的着色器调用,每个三角形一次,以如下的方式进行:红色三角形的着色器在蓝色的开始之前完成其操作。在标准管线中,片元的结果在被处理之前,会在合并阶段进行排序。光栅化顺序视图(rasterizer order view,ROV)由DirectX引入,以保证执行的顺序。他们和UAV是类似的;着色器对他们的读和写的方式都是相同的。关键的不同就是ROV保证了数据被以一个正确的顺序访问。这一特性极大提升了这些着色器可以访问的缓冲的可用性。例如,ROV允许像素着色器去写入它自己的混合的方法,因为它可以直接访问和写入到ROV的任何位置,并且因此并不需要混合阶段了。代价就是,如果检测到一个无序访问,像素着色器调用可能会停顿,直到之前绘制的三角形被处理。
3.9 The Merging Stage(合并阶段)
正如在2.5.2小节中讨论的一样,混合阶段就是独立片元(由像素着色器生成的)的深度和颜色和帧缓冲中的信息进行结合使用的阶段。DirectX将这个阶段称为输出混合器(output merger);OpenGL称它为逐采样的操作(per-sample operation)。在最经典的管线图中(包含我们自己的),这个阶段就是模板缓冲(stencil-buffer)和深度缓冲(z-buffer)操作的阶段。如果片元是可见的,另外一个会发生在这个阶段的就是颜色混合。对于不透明的表面,不涉及真正的混合,因为片段的颜色会简单地替换之前存储的颜色。实际片元和存储颜色的混合通常是用于透明度和组合操作(5.5小节)。
试想,由光栅化生成的片元经历了像素着色器,然后当应用了深度缓冲(z-buffer)时被先前渲染的片段所隐藏。所有的在像素着色器中的处理在接下来节没有必要了。为了避免这个浪费,许多的GPU在像素着色器执行前要做一些混合测试。片元的z-depth(以及其他正在使用的东西,比如模板缓冲或剪切)被用来测试可见性。片元如果隐藏则进行裁剪。这个功能叫做提前z测试(early-z)。像素着色器有能力去改变片元的z-depth或者完全忽略片元。如果有任何一种类型的操作存在于像素着色器程序中,early-z那么通常就不能使用并被关闭,这样通常会使管线变得没有那么高效。DirectX 11和OpenGL 4.2允许像素着色器强行开启early-z测试,尽管还有着一些限制。23.7小节中有着更多的early-z和其他z-buffer优化相关的信息。有效使用early-z会对性能有着极大的提升,这会在18.4.5小节中详细讨论。
合并阶段负责固定功能阶段(例如三角形配置)和完全可编程着色阶段之间的空白部分。尽管它不是可编程的,它的操作依然使可以高度配置的。特别地,颜色混合可以通过设置以执行大量不同的操作。最常见的是涉及到颜色、透明度的乘法、加法以及减法之间的结合使用,但是其他的操作也是可以的,例如取最大值和最小值,以及位逻辑运算。DirectX 10添加了混合来自像素着色器两个颜色和帧缓冲中的颜色的能力。这个能力称为双色源混合(dual source-color blending)并且不可以被用在多渲染目标的关联中。MRT是可以支持混合的,并且DirectX 10.1引入了在每个单独缓冲中执行不同混合操作的能力。
正如前面一个小节结尾提到的,DirectX 11.3通过ROV提供了使混合操作可被编程的方法,尽管是以性能为代价的。ROV和合并阶段两者保证了绘制顺序,即输出不变性(output invariance)。不论像素着色器结果的生成顺序是怎么样的,API的要求即是结果要排好序,以他们输入的顺序发送到合并阶段,一个物体接一个物体,一个三角形接一个三角形。
3.10 The Compute Shader (计算着色器)
GPU不仅仅可以用来实现传统图形管线。也有一些非图形的应用领域,如计算股票期权的估计价值并训练用于深度学习的神经网络。用这种方式利用硬件被称为GPU计算(GPU computing)。这种情形下,使用像CUBA和OpenGL这样的平台来控制GPU就是将他们作为大型并行处理器,而不去且没有必要访问图形专用的功能。这些框架经常使用C或者C++和他们的扩展,以及转为GPU定制的库。
计算着色器(compute shader)是由DirectX 11引入,其就是一种GPU计算的形式,在图形管线中这个着色器的位置并不是固定于某一个位置。它基本上是绑在渲染过程上,由图形API进行调用。它可以和顶点着色器、像素着色器以及其他的着色器一起使用。它依靠于管线中使用的同一个统一着色器处理器池。它和其他的着色器是一样的,其中它有一些输入数据组并且可以访问用于输入输出的缓冲区(例如纹理)。warp和线程在计算着色器中更加可见。例如,每次调用获取一个它可以访问的线程索引。还有一个线程组的概念,在DirectX 11中它包含了1到1024个线程。这些线程组由x、y、z三个坐标轴来指定,最大程度上简单化他们在着色器代码中的使用。每个线程组中拥有一小点可以在线程间共享的内存。在DirectX 11中,这个数目是32kB。计算着色器由线程组执行,从而保证所有组内的线程都同时运行。
计算着色器的一个重要的优势是他们可以访问GPU生成的数据。将数据从GPU发回到CPU会产生一个延迟,因此如过处理过程和结果可以保留在GPU上那么将可以提升性能。后处理(渲染图像可以以某种方式在这个阶段进行修改),即是计算着色器的一种普遍的应用。共享的内存意味着从图像像素采样的中间结果可以与邻近线程进行共享。例如,使用计算着色器去决定一个图像的照度(luminance)的分布或者平均值,可以比在像素着色器上执行这个操作快2倍之多。
计算着色器在粒子系统、网格处理(例如面动画、裁剪、图像滤波、提升深度细节、阴影、深度场)以及其他任何一组GPU处理器可以承担的任务上都具有很大用处。Wihilidal讨论了计算着色器是怎样比曲面细分的hull着色器更加高效的。图3.16中展示了其他的一些应用。

图 3.16 计算着色器示例。左侧,应用计算着色器去模拟被风影响的头发,其中头发自身是由曲面细分阶段进行渲染的。中间,计算着色器执行了一个快速的模糊操作(译者注:滤波)。右侧,模拟海浪。(图像来自于NVIDIA SDK 11的示例,由NVIDIA公司提供)
到这里就结束了我们对于GPU上实现的渲染管线的回顾。有许许多多的GPU功能的使用和组合的方式,从而实现多种多样的渲染相关的处理。这本书的中心课题就是相关的利用这些特性和能力的理论和算法。我们接下来会关注变换和着色(transform and shading)
Further Reading and Resources(进一步的学习阅读资源)
Giesen的图形管线塔讨论了GPU的许多层面,解释了其中的元素为什么会那样去工作。Fatahalian和Bryant的一系列详细课程讨论了GPU的并行特性。虽然集中于使用CUBA的GPU计算,Kirk和Hwa的书的介绍部分还是讨论了GPU的演变和设计哲学。
去学习正式的着色器编程需要花费一定的时间和精力。像OpenGL Superbible和OpenGL Programming Guide这样的书籍包含了关于着色器编程的相关材料。更老一点的像OpenGL Shading Language这样的书并没有覆盖到最近一点的着色器姐u但,例如几何和曲面细分着色器,但是特别集中于着色器相关的算法。参照本书官网——realtimerendering.com,可以获取最近的和推荐的书籍去进行阅读学习。















 3894
3894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











