







 本文介绍了OneVsRestClassifier(OvR)的概念,它是通过为每个类别创建一个分类器来处理多类分类问题。文章通过实例展示了如何使用sklearn库的OvR与SVM结合进行数据建模,并通过ROC曲线评估分类性能。代码示例中,首先加载鸢尾花数据集,然后进行数据预处理,接着训练和测试模型,并绘制了不同类别的ROC曲线,以展示模型的识别能力。
本文介绍了OneVsRestClassifier(OvR)的概念,它是通过为每个类别创建一个分类器来处理多类分类问题。文章通过实例展示了如何使用sklearn库的OvR与SVM结合进行数据建模,并通过ROC曲线评估分类性能。代码示例中,首先加载鸢尾花数据集,然后进行数据预处理,接着训练和测试模型,并绘制了不同类别的ROC曲线,以展示模型的识别能力。
1、什么是OneVsRestClassifier
OvR为每一个类别配备一个分类器,是目前最常用的一种多类分类策略
c l a s s s k l e a r n . m u l t i c l a s s . O n e V s R e s t C l a s s i f i e r ( e s t i m a t o r , ∗ , n _ j o b s = N o n e ) class sklearn.multiclass.OneVsRestClassifier(estimator, *, n\_jobs=None) classsklearn.multiclass.OneVsRestClassifier(estimator,∗,n_jobs=None)
estimator:要使用的分类模型
n_jobs:与K折交叉验证相同,n_jobs等于-1时,使用所有处理器工作
2、为什么要使用OneVsRestClassfier
使用OvR可以更好的获取每一个类别的相关信息,比如在建模时遇到需要分品牌,分类别对产品进行处理预测,OvR就是可以是一个思路。
具体sklearn的中文文档给出了如下的介绍:

3、OvR实现
import numpy as np
from sklearn import svm,datasets
from sklearn.metrics import roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
import matplotlib.pyplot as plt
#加载鸢尾数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
#将数据二进制化处理,此处和onehotencoder大概一致
y = label_binarize(y,classes=[0,1,2])
n_classes = y.shape[1]
#加入噪点
n_sample,n_featrues = X.shape
X = np.c_[X,np.random.RandomState(0).randn(n_sample,80*n_featrues)]
#分割数据
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=.5,random_state=0)
#设置分类器,这里实用的是SVC支持向量机
clf =SVC(C=0.2,gamma=0.2,kernel='linear', probability=True, random_state=0)
classifier = OneVsRestClassifier(clf,n_jobs=-1)
classifier.fit(X_train, y_train)
#计算分数,roc_curve要用到
y_score = classifier.decision_function(X_test)
fpr = dict()
tpr = dict()
roc_auc = dict()
#计算aoc值
for i in range(n_classes):
fpr[i],tpr[i],_=roc_curve(y_test[:,i],y_score[:,i])
roc_auc[i] = auc(fpr[i],tpr[i])
#画图
plt.figure()
lw = 2
color = ['r', 'g', 'b']
for i in range(3):
plt.plot(fpr[i], tpr[i], color=color[i],lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[i])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
4、附件
三个类别的roc曲线
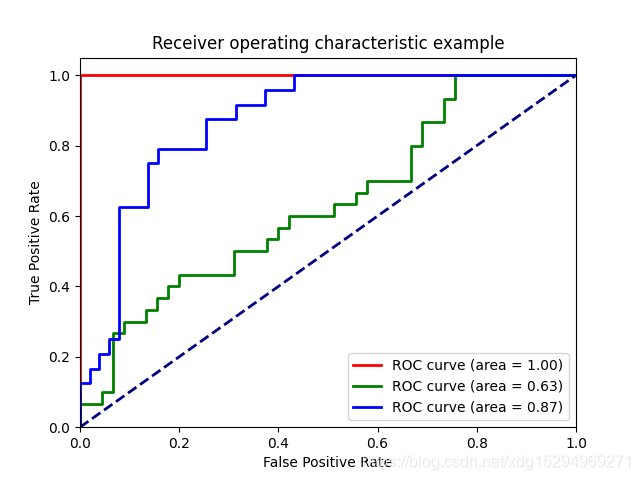
5 、参考文献
https://scikit-learn.org.cn/view/679.html
https://www.cnblogs.com/yanshw/p/12691329.html


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











