







联邦学习定义
联邦学习是一种隐私保护,安全加密技术的分布式机器学习框架。目的在于分散的各参与方在满足不向其他参与方披露隐私数据的情况下,协作进行机器模型学习的训练。
安全问题和解答
1. 联邦学习系统的脆弱性的根本原因是什么?
通信:联邦学习需要多轮通信,不安全的通信信道会是一个安全隐患。
客户端数据操作:参与联邦学习的客户端很多,他们可以利用模型参数和训练数据实施攻击。
被损害的中央服务器:由于中央服务器负责聚合,分发数据,因此中央服务器可能会被攻击者所利用。
聚合算法的不足:聚合算法需要能够识别出一些异常的数据并抛弃那些可疑的数据。
联邦学习环境的实施:参与联邦学习实现的开发者们可能难以分辨哪些是隐私数据,哪些不是。
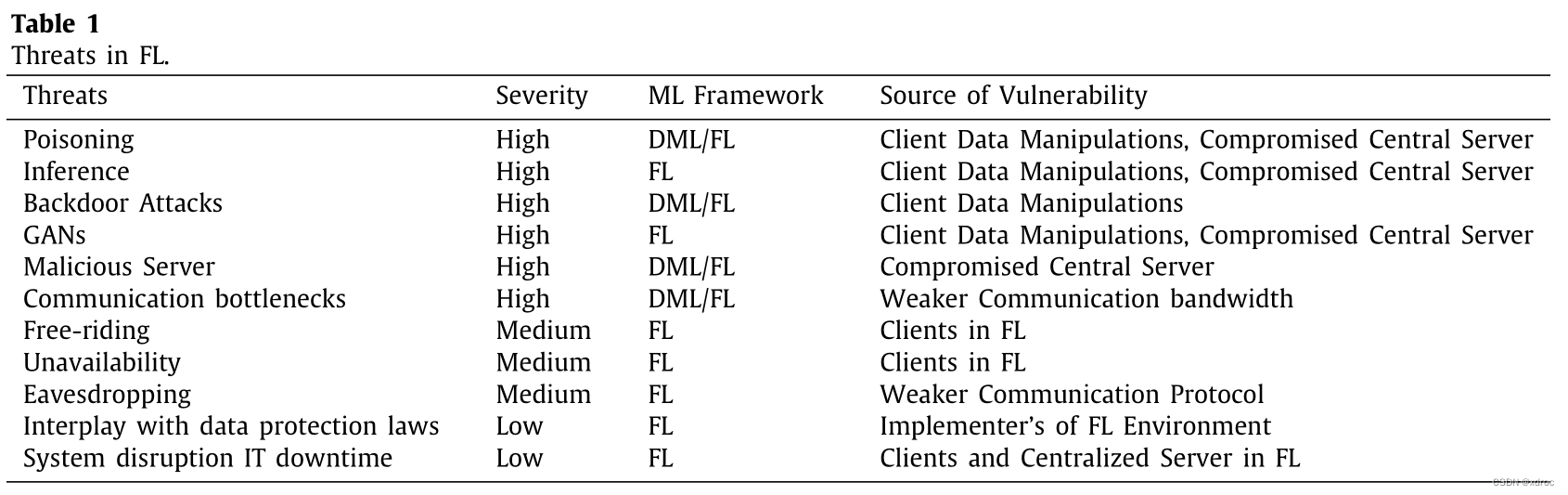
2. 在联邦学习领域中的安全威胁有什么?
投毒攻击(Poisoning)
推理攻击(Inference)
后门攻击(Backdoor attacks)
基于生成对抗网络的攻击(GANs)
系统停机(System disruption IT downtime):停机时间可能是一种精心策划的攻击,目的是从FL环境中窃取信息
恶意的服务器(Malicious server)
通信瓶颈(Communication bottlenecks)
搭便车攻击(Free-riding attacks):简单来说就是有些客户端想要做伸手党
不可用性(Unavailability):客户端在训练过程中可能会掉线
窃听(Eavesdropping):攻击者可能会从不可靠的信道中窃取到数据
违反数据保护法(Interplay with data protection laws)
3. 与分布式机器学习相比,联邦学习有哪些特有的安全威胁?
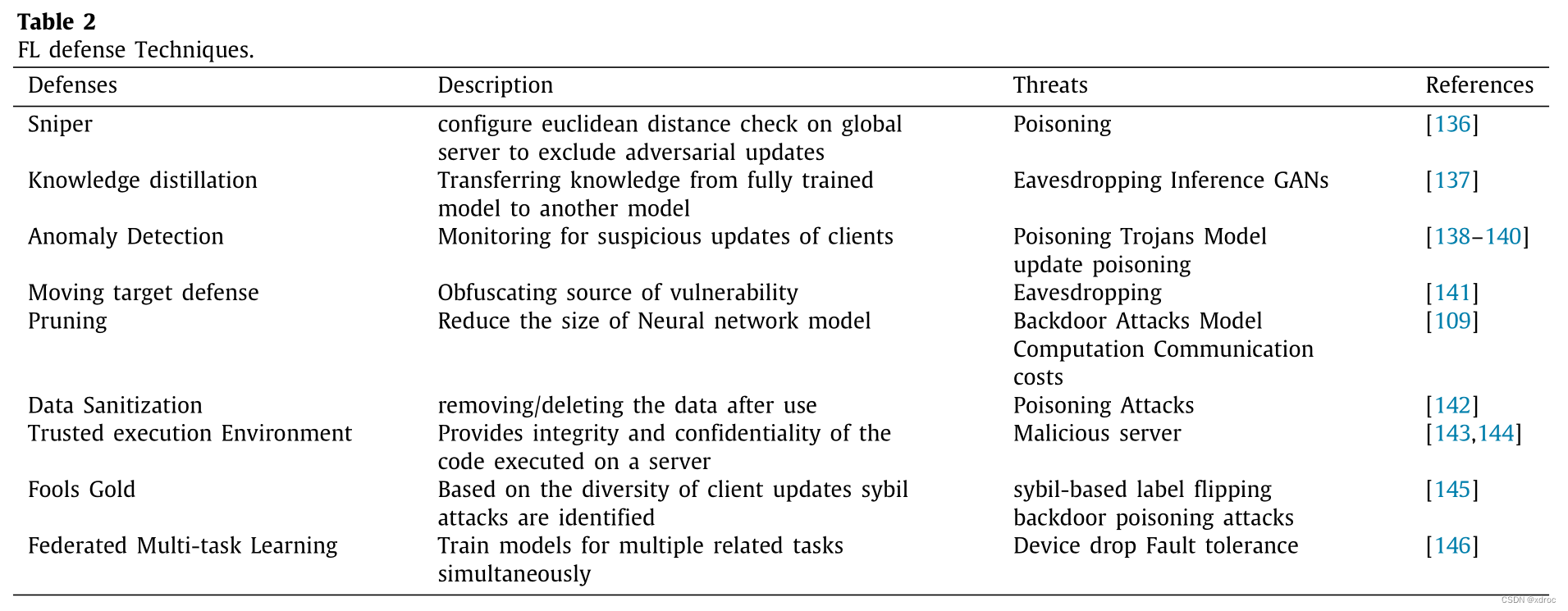
4. FL安全漏洞的防御技术有哪些?
作者将防御方法分为两大类:主动防御(Proactive defense)和反应性防御(reactive defense)。主动防御是是猜测会面临到哪些威胁并布置好高效的防御技术的方法,而反应性防御是在发现攻击时进行的操作。 另外作者还提到了将联邦学习与区块链结合的想法,利用区块链来记录联邦学习全局模型的参数。 下表是作者提出的具体的一些防御方法:
隐私问题和解答
1. 联邦学习中有哪些隐私威胁/攻击?
成员推断攻击(Membership inference attacks):推理攻击是一种推断训练数据细节的方法,这种攻击通过检查训练数据集上是否存在特定的数据来获取信息。
无意的数据泄露与通过推理重构(Unintentional data leakage & reconstruction through inference)*:数据泄露的危害以及恶意的客户端通过全局模型来重构其他客户端的训练数据。
基于生成对抗模型的推断攻击(GANs-based inference attacks)
2. 隐私威胁防御技术?
安全多方计算(Secure Multi-party Computation):多方联合计算一个函数,且各方都不泄露各自的数据。
差分隐私(Differential Privacy):具体方法是对样本进行添加噪音,并尽量使总体样本的统计性质(均值,方差等)保持不变。
混合(Hybrid):多技术结合。
验证网络(VerifyNet):验证服务器端是否是可靠的。
对抗训练(Adversarial training):从训练阶段开始就尝试攻击的所有排列,使FL全局模型对已知的对抗性攻击具有鲁棒性。

3. 与分布式机器学习相比,联邦学习有哪些特有的隐私威胁?
在服务器带有参数的分布式机器学习中,发起推理攻击从其他客户端窃取信息是最不可取的方法,因为数据很容易在参数服务器上或通过客户端更新获得。然而,对于分布式机器学习应用,其中训练良好的ML模型被外包为付费服务,存在基于推理的攻击的可能性。
基于GAN的推理攻击在FL环境中是可行的,但对于分布式机器学习不太合适。分布式机器学习为攻击者提供了空间来发起更简单和直接的攻击。GAN是复杂的,需要更多的计算资源,这使得它在分布式机器学习中不是首选的攻击方法。
4. 保护隐私的代价是什么?
在安全多方计算中基于密码学的方法中,要求每个客户端对所有上传的参数进行加密,因此,每个客户端都需要花费额外的计算资源来执行加密。另外,差分隐私可能还会降低ML模型的准确性。
未来方向
零日攻击及其支持技术(Zero-day adversarial attacks and their supporting techniques):该病毒会在攻击计算机前先破坏杀毒软件。
可信的可追溯性(Trusted traceability):如果一个全局ML模型中的预测值发生了变化,我们将需要跟踪能力,以确定是哪个客户端聚合值导致了该变化。
API定义明确的流程(Well-defined process with APIs)
隐私保护和成本之间的权衡(Optimize trade-off between privacy protection enhancement and cost)
在实践中构建联邦学习隐私保护增强框架(Build FL privacy protection enhanced frameworks in practice)
联邦学习中客户端的选择和训练计划(Client selection and training plan in FL Training)
对不同机器学习算法的优化方法(Optimization techniques for different ML algorithms)
模型训练方法及训练参数的选择(Vision on training strategies and parameters)
易于迁移和生产(Ease in migrating and productionising)
原文链接:https://blog.csdn.net/qq_41691212/article/details/121445156















 2011
2011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









