







 本文探讨了联邦学习在数据安全和隐私保护方面的挑战,包括数据投毒、模型投毒、后门攻击等攻击手段。同时,介绍了相关解决方案,如数据清理、异常性探测、知识蒸馏等防御策略,并讨论了多方安全计算和差分隐私在保护用户隐私中的应用。文章指出,理解和适应特定场景的隐私保护需求,以及行为研究制定相应的隐私保护机制是未来的研究方向。
本文探讨了联邦学习在数据安全和隐私保护方面的挑战,包括数据投毒、模型投毒、后门攻击等攻击手段。同时,介绍了相关解决方案,如数据清理、异常性探测、知识蒸馏等防御策略,并讨论了多方安全计算和差分隐私在保护用户隐私中的应用。文章指出,理解和适应特定场景的隐私保护需求,以及行为研究制定相应的隐私保护机制是未来的研究方向。
©作者 | Doreen
01 联邦学习的背景知识
近年来,随着大量数据、更强的算力以及深度学习模型的出现,机器学习在各领域的应用中取得了较大的成功。
然而在实际操作中,为了使机器学习有更好的效果,人们不得不将大量原始数据送入模型中训练,这使得一些敏感数据被恶意的攻击者窃取。
因此,研究人员开始琢磨如何在保护数据安全和隐私的前提下提高机器学习的准确率。经过多年的探索,[1]提出了一个基于机器学习框架的联邦学习模型。
联邦学习模型的实现主要分为以下三个步骤:
1、模型选择:中央服务器先预训练一个模型,然后将整个模型(包括其初始参数)分享给所有的用户终端;
2、本地训练模型:用户接收到分发的模型后用各自的数据训练该模型,同时更新参数,然后将训练好的模型重新发送给中央服务器;
3、整合模型:中央服务器接收到各个用户的模型后将其整合成一个全局模型,然后再分享给各个用户终端。
通过以上三步不断迭代直至模型收敛为止。流程图如图1所示。
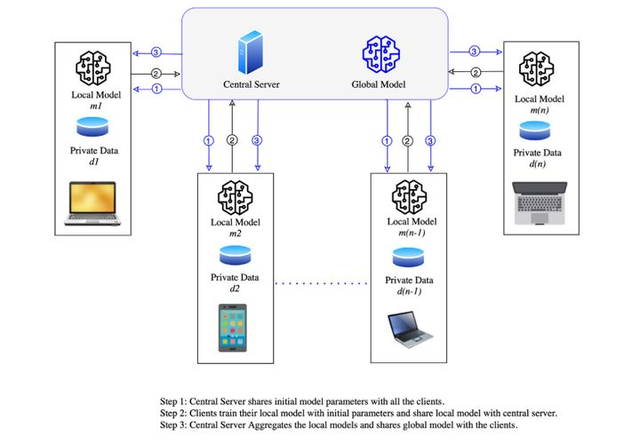
图1 联邦学习流程图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
目前,联邦学习根据不同标准可以分为不同类别。按照网络拓扑结构,联邦学习可分为中心化和完全去中心化联邦学习。前者依赖一个中心服务器去分享、整合训练模型。
与传统的中心服务器不同,联邦学习的中心服务器通过实时或非实时的用户更新模型来整合全局模型,在此过程中不涉及到数据的传输。
完全去中心化联邦学习(网络拓扑图如图2所示)没有中心服务器和全局模型的概念,采用了端对端共享信息来更新用户模型。
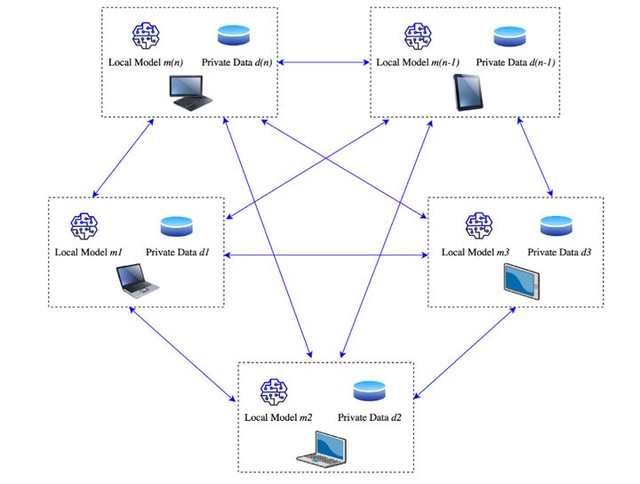
图2 完全去中心化联邦学习的网络拓扑图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
按照数据分区来划分,联邦学习分为横向联邦学习、纵向联邦学习和联邦迁移学习。
其中,横向联邦学习(如图3所示)适用于同一领域的不同用户数据有着较多的相似特征。最经典的案例是谷歌的Gboard,当用户在手机键盘上输出一个词,利用横向联邦学习模型可以预测出用户想要输出的下一个词。
纵向联邦学习(如图4所示)适用于不同领域的用户拥有共同数据(数据特征不一致)的情况。最典型的案例是银行通过纵向联邦学习模型从不同用户的信用卡网购信息中学习到用户的购物喜好,并根据该信息为用户提供相关的刷卡折扣优惠同时优化自身的联邦学习模型。
联邦迁移学习(如图5所示)是指利用一个在相似数据集上训练好的模型作为初始模型去解决另一个完全不同的问题,其应用场景与纵向联邦学习的应用类似。在该模型中,全局模型在云服务器上运行,用户可以下载该模型并根据自己的需求更新模型,从而使得模型更加个性化。

图3 横向联邦学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)

图4 纵向联邦学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
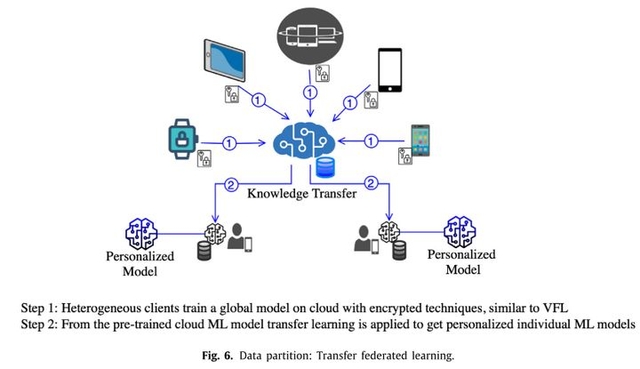
图5 联邦迁移学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
鉴于联邦学习模型在传递信息的过程中始终将原始数据保留在用户终端,其在数据安全和隐私保护方面有着较大的优势。
凭借该优势,联邦学习已经广泛应用于各个领域。在医疗领域,各个医疗机构都存储了大量的患者信息,这为实现精准医疗奠定了基础。
然而在实际应用过程中,为了提高机器学习模型的泛化能力,常常需要将不同机构的数据混在一起送入模型中训练,因此一些敏感信息很容易遭到泄露进而给患者带来一定的安全风险。
针对这个问题,联邦学习可以令中央服务器整合各个机构训练后的模型来生成一个全局模型分享给用户,不仅提升了模型的泛化能力,而且有效地保护了敏感信息。
除此之外,联邦学习在自动驾驶、恶意软件分类、入侵检测等方面也有着广泛应用。
02 联邦学习在数据安全和隐私保护方面国内外的研究进展
众所周知,系统中的漏洞使得一些恶意攻击者通过使用特定的技术就能轻松获取未授权的高级权限。一旦拥有了该权限,攻击者不仅可以窃取各种敏感数据,而且能够任意更改系统的配置来达到自己的目的。
因此,找到漏洞源头是维持系统安全稳定运行的前提条件。联邦学习作为一个分布式机器学习模型,可以部署到各种各样的终端上,其存在着一些与分布式系统类似的安全漏洞。
通过分析联邦学习模型的运行流程,可以将漏洞的来源确定为以下五个方面[1]:
①通信协议:联邦学习是一个反复迭代的模型,在学习过程中会随机选取一些客户端信息进行交互。由于存在多次的信息传递,不安全的通信信道成为漏洞的一个源头;
②用户数据操控:在一个大型的联邦学习环境中,众多终端都拥有一些敏感数据和模型参数,一旦被攻击者利用,攻击者可以凭借终端信息推测出全局模型并根据自己的目的任意更改模型,从而对模型输出结果的准确率造成一定的影响;
③受到安全威胁的中央服务器:中央服务器负责整合用户端上传的更新模型,并将原全局模型进一步更新后下发给各用户终端。若中央服务器遭到攻击者的破坏,全局模型的输出结果将会受到影响&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











