







Faster R-CNN 简单梳理
作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/53073388
声明:版权所有,转载请联系作者并注明出处
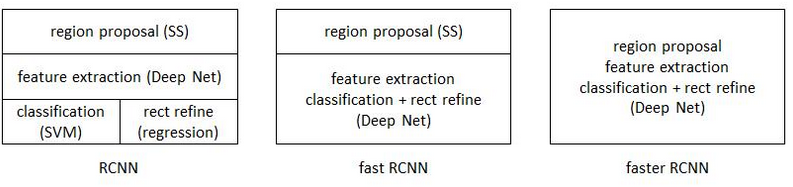
从R-CNN到Fast R-CNN,再到Faster R-CNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)被统一到一个深度网络框架之内。所有计算没有重复,全部都在GPU中完成,大大提高了运行速度。
三个框架的示意图如下:
1 亮点
Faster R-CNN可以看做“区域生成网络+Fast R-CNN“的系统,其中区域生成网络代替了Fast RCNN中的Selective Search方法。
Faster R-CNN解决了三个问题:
- 如何设计区域生成网络
- 如何训练区域生成网络
- 如何让区域生成网络和Fast R-CNN网络共享特征提取网络
2 区域生成网络(RPN)
先使用VGG等现有模型提取特征,然后使用一个小的网络在卷积最后得到的这个特征图上进行滑动扫描,这个滑动的网络每次与特征图上n*n 的窗口全连接,然后映射到一个低维向量,最后将这个低维向量送入到两个全连接层,对特征图上所有可能的候选框进行分类和回归。
特征提取
原始特征提取包含若干层Conv+ReLu,直接套用ImageNet上常见的分类模型即可(Faster R-CNN试验了两种网络:5层的ZF,16层的VGG-16)。
然后“额外”添加一个conv+relu层,输出256维的特征。
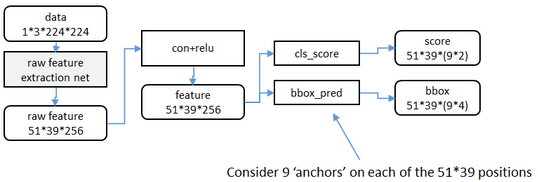
anchor生成
为方便举例,由VGG等现有模型提取的特征图,在这里我们将其看做尺度为51*39的256通道的图像,然后在这个特征图上进行滑窗操作。
在特征图上进行的滑窗操作,相当于映射回原图后,Sliding Window中心对应的原图上的中心,在不同尺寸和比例的anchor区域中进行特征提取(这个对应关系是在实现代码里事先确定好的);同时值得一提的是,作者实验指出,映射回原图的anchor比Sliding Window相应的感受野大一点也是可以的,因为有可能像人一样有预测边缘的能力。(感受野计算,见这里)
另一方面,Sliding Window的尺寸为3*3的滑窗操作可以看做3*3的卷积核与特征图进行卷积操作(也就是那“额外”的conv+relu层),那么这个3*3的区域卷积后可以获得一个256维的特征向量。
这个256维的向量提取的特征就对应着一个Sliding Window中心映射回原图后,9个anchor所在的区域。
当然我们知道,Sliding Window在不断滑动,所以还有很多这样的256维向量。
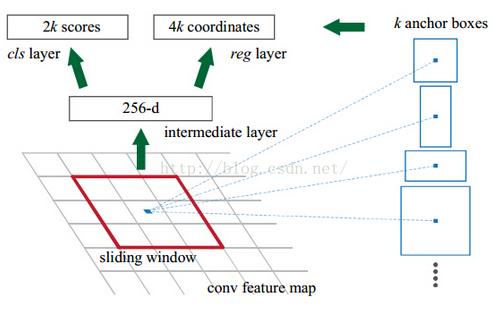
论文中,3*3滑窗中心点位置,对应预测输入图像3种尺度{ 1282,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2812
2812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









