







应用编程概念
首先要先对应用编程的概念进行学习。
系统调用
系统调用(system call)其实是Linux内核提供给应用层的应用编程接口(API),是Linux应用层进入内核的入口。通过系统调用可完成如打开磁盘文件、读写文件、控制外设等。
裸机编程、Linux驱动编程、Linux应用编程:
- 裸机:没有操作系统环境
- Linux驱动:基于内核驱动框架开发,调用Linux内核的接口完成设备驱动注册,负责底层硬件操作的逻辑
- Linux应用:在应用程序中调用系统调用API完成功能和逻辑,应用程序运行于操作系统之上
应用程序与驱动程序是分隔、分离的,它们单独编译,它们并不是整合在一起的,应用程序运行在操作系统之上,有操作系统支持,应用程序处于用户态,而驱动程序处于内核态,与纯粹的裸机程序存在着质的区别。
库函数
库函数也就是C语言库函数,C语言库是应用层使用的一套函数库,在Linux下,通常以动态(.so)库文件的形式提供,存放在根文件系统/lib目录下,C语言库函数构建于系统调用之上,也就是说库函数其实是由系统调用封装而来的,当然也有些库函数时不调用系统调用的。
Linux系统内核提供了一系列的系统调用供应用层使用,直接使用系统调用就可以了,但是有些系统调用使用起来并不是很方便,于是就出现了C语言库,这些C语言库函数的设计是为了提供比底层系统调用更为方便、更为好用、且更具有可移植性的调用接口。
两者的区别:
- 库函数是属于应用层,而系统调用是内核提供给应用层的编程接口,属于系统内核的一部分;
- 库函数运行在用户空间,调用系统调用会由用户空间(用户态)陷入到内核空间(内核态);
- 库函数通常是有缓存的,而系统调用是无缓存的,所以在性能、效率上,库函数通常要优于系统调用;
- 可移植性:库函数相比于系统调用具有更好的可移植性。
应用编程简单点来说就是:开发Linux应用程序,通过调用内核提供的系统调用或使用C库函数来开发具有相应功能的应用程序。
标准C库
C语言库是以动态库文件的形式提供的,通常存放在/lib目录,它的命名方式通常是libc.so.6,不过这个是一个软链接文件,它会链接到真正的库文件。当然也有可能是在/lib/x86_64-linux-gnu目录,找到libc.so.6之后可以输入以下命令:
| ./libc.so.6 |
输入后可以看到glibc的版本号。
main函数
int argc形参表示传入参数的个数,包括应用程序自身路径和程序名,而char** argv[]就是与argc对应的形参名字。
开发环境
我就直接用的vscode,这里教程是还教了eclipse安装,不过都是编译器也无所谓,有一个就可以了。
文件I/O基础
本章介绍Linux应用编程中最基础的知识,即文件I/O(Input、Outout),文件I/O指的是对文件的输入/输出操作。
本章将介绍Linux系统下文件描述符的概念,随后会逐一讲解构成通用I/O模型的系统调用,譬如打开文件、关闭文件、从文件中读取数据和向文件中写入数据以及这些系统调用涉及的参数等内容。
文件描述符
例如调用open函数,如果打开成功就会返回一个非负整数,就是文件描述符(file descriptor),对于Linux内核而言,所有打开的文件都会通过文件描述符进行索引。
一个进程可以打开多个文件,但是在Linux系统中,一个进程可以打开的文件数是有限制的。可以通过如下命令查询进程可打开最大文件数:
| ulimit -n |
最大默认值为1024,文件描述符是从0开始分配的,不会重复;文件关闭后该文件描述符就会被释放。一般自行打开程序,文件描述符会从3开始(系统标准输入是0,标准输出是1,标准错误是2都被占用了)。
open打开文件
函数原型如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
在Linux下,可通过man命令查看某个Linux系统调用的帮助信息,例如查看open命令:
| man 2 open #查看 open 函数的帮助信息 |
查到的部分结果如下:
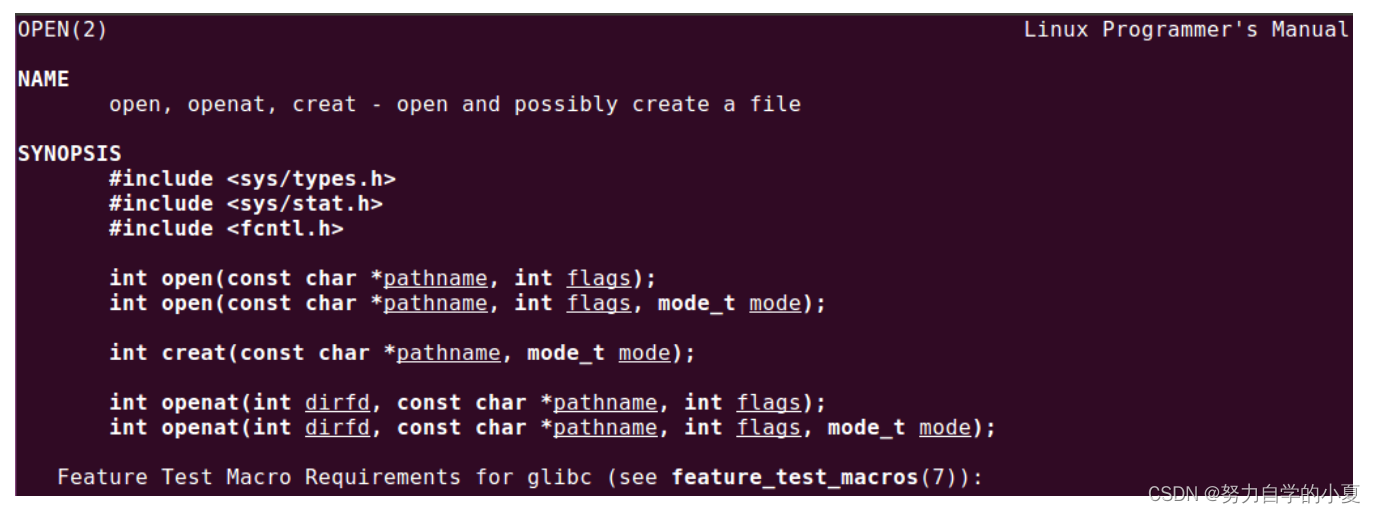
函数参数和返回值的概括,具体还需要去翻教程:
- pathname:标识需要打开或创建的文件。
- flags:包括文件访问模式标志以及其他文件相关标志。可以通过位或运算(|)将多个标志组合。
- mode:指定新建文件的访问权限,只有flags包含O_CREAT或O_TMPFILE标志时才有效。可以直接用Linux定义好的宏并用位或运算(|)组合。
- 返回值:成功将返回文件描述符,是个非负整数;失败返回-1。
write写文件
函数原型:
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
函数参数和返回值:
- fd:文件描述符。
- buf:指定写入数据对应的缓冲区。
- count:写入字节数。
- 返回值:成功将返回写入字节数(如果返回值小于count,可能是磁盘空间已满);错误返回-1。
read读文件
函数原型:
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
函数参数和返回值含义如下:
- fd:文件描述符。
- buf:指定用于存储读取数据的缓冲区。
- count:指定需要读取的字节数。
- 返回值:成功将返回读取到的字节数,会随着位置偏移量改变。
close关闭文件
函数原型:
#include <unistd.h>
int close(int fd);
函数参数和返回值含义如下:
- fd:文件描述符。
- 返回值:如果成功返回0,如果失败则返回-1。
lseek
对于每个打开的文件,系统都会记录它的读写位置偏移量,也把这个读写位置偏移量称为读写偏移量,记录了文件当前的读写位置,当调用read()或write()函数对文件进行读写操作时,就会从当前读写位置偏移量开始进行数据读写。
函数原型:
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
函数参数和返回值含义如下:
- fd:文件描述符。
- offset:偏移量,以字节为单位。
- whence:用于定义参数offset偏移量对应的参考值,是一个宏定义。
- 返回值:成功将返回从文件头部开始算起的位置偏移量(字节为单位),也就是当前的读写位置;发生错误将返回-1。
深入探究文件I/O
Linux系统文件管理
静态文件与inode
文件存放在磁盘文件系统中,并且以一种固定的形式进行存放,称为静态文件。文件储存在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector),每个扇区储存512字节(相当于 0.5KB),操作系统读取硬盘的时候,不会一个个扇区地读取,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block。
磁盘在进行分区、格式化的时候会将其分为两个区域,一个是数据区,用于存储文件中的数据;另一个是inode区,用于存放inode table(inode 表),inode table中存放的是一个一个的inode(inode节点),其实质上是一个结构体,这个结构体中有很多的元素,不同的元素记录了文件的不同信息,如下图所示:
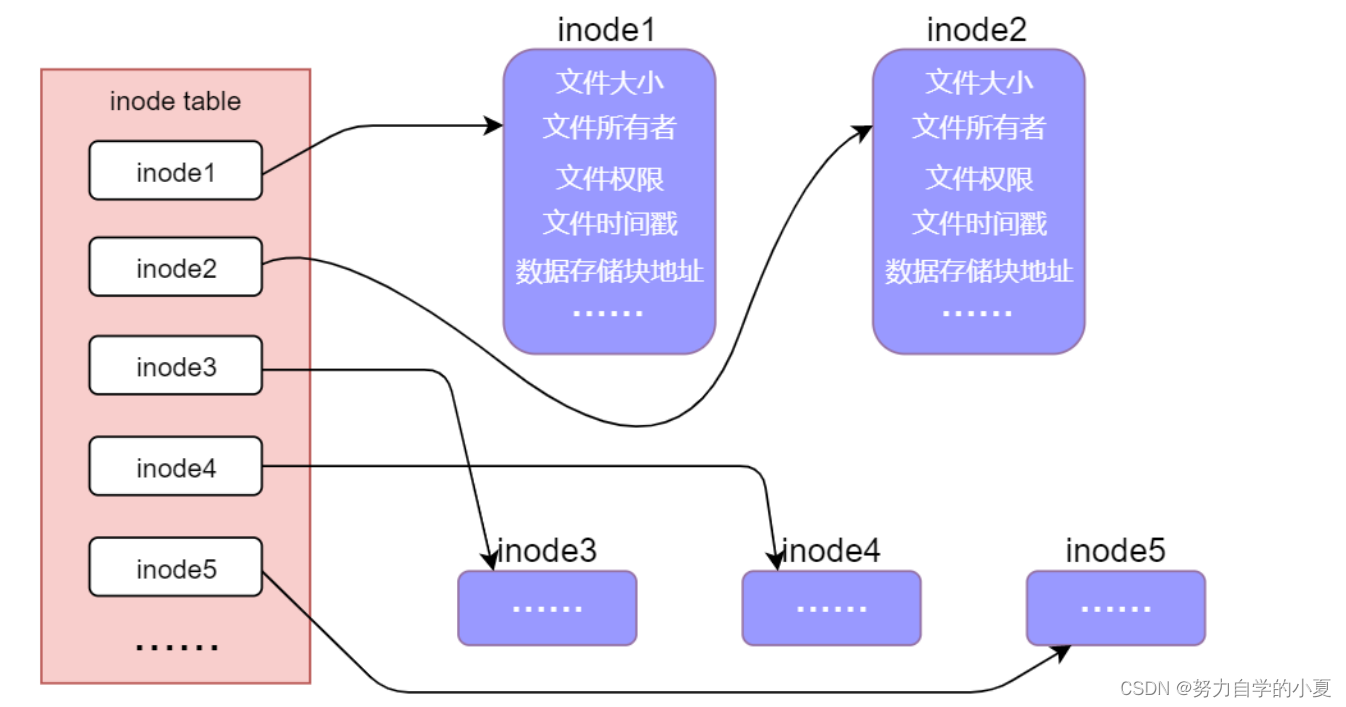
inode table表本身也需要占用磁盘的存储空间,每一个文件都有唯一的一个inode,每个inode都有一个与之相对应的数字编号,在Linux系统中可通过如下命令查看文件inode编号:
| ls -il |
当然也可以用“stat”命令查看。
打开文件系统分为三个过程:
- 系统找到这个文件名所对应的inode编号;
- 通过inode编号从inode table中找到对应的inode结构体;
- 根据inode结构体中记录的信息,确定文件数据所在的block,并读出数据。
文件打开时状态
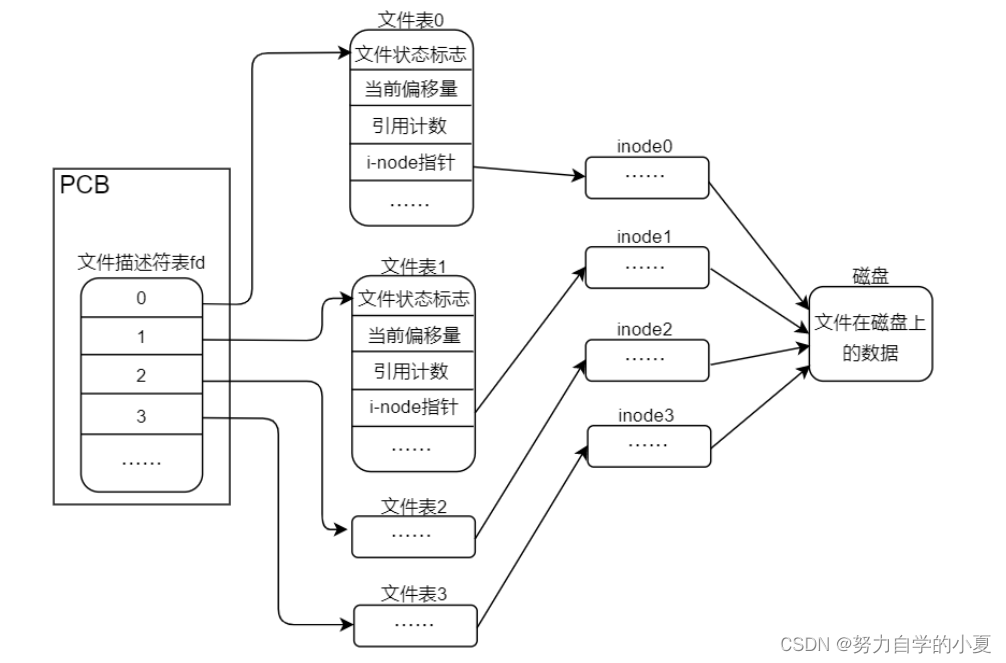
调用open打开文件后,内核会申请一段内存,将静态文件的数据内容读到内存中,之后的读写都是操作这个内存中的动态文件。
当然此时,数据就不同步了,内核会在之后将内存的动态文件更新到磁盘设备中。(块设备需要一个block来读,操作不灵活)
在Linux系统中,内核会为每个进程设置一个专门的数据结构用于管理该进程,把这个称为进程控制块(Process control block,缩写PCB)。PCB结构体有一个指针指向文件描述符表,其每个元素索引到对应文件表(也是数据结构题记录文件相关信息,包括i-node指针,指向inode),每个文件描述符都有对应的文件表:
返回错误处理与errno
Linux系统下,当函数执行发生错误的时候,操作系统会将这个错误所对应的编号赋值给errno变量,每一个进程都维护自己的errno变量,它是程序中的全局变量,该变量用于存储就近发生的函数执行错误编号,也就意味着下一次的错误码会覆盖上一次的错误码。其本质是int类型变量,可通过“man”命令查询该函数是否有errno设置。在程序中包含<errno.h>头文件即可使用。
strerror函数
该函数可以将对应的errno转换成适合查看的字符串信息,原型如下:
#include <string.h>
char *strerror(int errnum);
函数参数和返回值如下:
- errnum:错误编号errno。
- 返回值:对应错误编号的字符串描述信息。
使用的时候可以直接把strerror(errno)给printf出来就可以了。
perror函数
可以使用perror函数来查看错误信息,一般用的最多的还是这个函数,调用此函数不需要传入errno,函数内部会自己去获取errno变量的值,且调用此函数会直接将错误提示字符串打印出来,还可以加入自己的打印信息,原型如下:
#include <stdio.h>
void perror(const char *s);
函数参数和返回值含义如下:
- s:在错误提示字符串信息之前,可加入自己的打印信息,也可不加,不加则传入空字符串即可。
- 返回值:void无返回值。
exit、_exit、_Exit
在Linux系统下,进程退出可以分为正常退出和异常退出,正常退出除了return,还可以使用exit()、_exit()和_Exit()。
_exit()和_Exit()函数
调用_exit()函数会清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将控制权交给操作系统,函数原型如下:
#include <unistd.h>
void _exit(int status);
调用函数需要传入status状态标志,0表示正常结束、若为其它值则表示程序执行过程中检测到有错误发生。
_Exit()函数原型如下所示:
#include <stdlib.h>
void _Exit(int status)
两者是等价的,同时要注意这两个函数都是系统调用。
exit()函数
exit()是一个标准C库函数,而_exit()和_Exit()是系统调用。执行exit()会执行一些清理工作,最后调用_exit()函数。exit()函数原型如下:
#include <stdlib.h>
void exit(int status);
使用方法是一样的。
空洞文件
偏移文件头部来写入数据,但是文件本身在偏移位置没有数据,从而造成空洞。文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它分配对应的空间,但是空洞文件形成时,逻辑上该文件的大小是包含了空洞部分的大小的,这点需要注意。
可以用于多线程共同操作文件,加快速度。
如果查看空洞文件,ls命令查看到包含空洞不分大小和真实数据大小之和;du命令就只查到文件实际占用存储块大小。
O_APPEND和O_TRUNC标志
O_TRUNC标志
如果使用了这个标志,调用open函数打开文件的时候会将文件原本的内容全部丢弃,文件大小变为0。
O_APPEND标志
如果open函数有O_APPEND标志,调用open函数打开文件,当每次使用write()函数对文件进行写操作时,都会自动把文件当前位置偏移量移动到文件末尾,从文件末尾开始写入数据。
需要注意,O_APPEND不影响读位置偏移量,且lseek无法改变写位置偏移量。
多次打开同一文件
一个进程内多次open打开同一个文件,那么会得到多个不同的文件描述符fd,同理在关闭文件的时候也需要调用close依次关闭各个文件描述符。
一个进程内多次open打开同一个文件,在内存中并不会存在多份动态文件。
一个进程内多次open打开同一个文件,不同文件描述符所对应的读写位置偏移量是相互独立的。
多次打开同一文件进行读操作与O_APPEND标志
一个进程中两次调用open函数打开同一个文件,分别得到两个文件描述符fd1和fd2,使用这两个文件描述符对文件进行写入操作,这两个偏移量是相互独立的,也就是会分别写。
如果需要连着写,就可以借助O_APPEND标志,只要open的时候加上就可以了。
复制文件描述符
在Linux系统中,open返回得到的文件描述符fd可以进行复制,复制成功之后可以得到一个新的文件描述符,使用新的文件描述符和旧的文件描述符都可以对文件进行IO操作,两者权限相同,均指向同一个文件表。可以用dup或dup2这两个系统调用进行复制。
dup函数
函数原型如下:
#include <unistd.h>
int dup(int oldfd);
函数参数和返回值含义如下:
- oldfd:需要被复制的文件描述符。
- 返回值:成功时将返回一个新的文件描述符,由操作系统分配,分配置原则遵循文件描述符分配原则;如果复制失败将返回-1,并且会设置errno值。
复制完后调用write就是接着写,从fd1结束的地方开始写fd2,fd2结束的地方开始写fd1。
dup2函数
dup2系统调用可以手动指定文件描述符,而
不需要遵循文件描述符分配原则,原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);
函数参数和返回值含义如下:
- oldfd:需要被复制的文件描述符。
- newfd:指定一个文件描述符(需要指定一个当前进程没有使用到的文件描述符)。
- 返回值:成功时将返回一个新的文件描述符,也就是手动指定的文件描述符newfd;如果复制失败将返回-1,并且会设置errno值。
文件共享
所谓文件共享指的是同一个文件(譬如磁盘上的同一个文件,对应同一个inode)被多个独立的读写体同时进行IO操作。
文件共享的意义有很多,多用于多进程或多线程编程环境中,可以通过文件共享的方式来实现多个线程同时操作同一个大文件,以减少文件读写时间、提升效率。核心是:如何制造出多个不同的文件描述符来指向同一个文件。
可以采用的方法有:
- 同一个进程中多次调用open函数打开同一个文件。
- 不同进程中分别使用open函数打开同一个文件。
- 同一个进程中通过dup(dup2)函数对文件描述符进行复制。
原子操作与竞争冒险
Linux是一个多任务、多进程操作系统,系统中往往运行着多个不同的进程、任务,多个不同的进程就有可能对同一个文件进行IO操作,此时该文件便是它们的共享资源,它们共同操作着同一份文件。
竞争冒险
驱动的时候学过,这里就能说明,竞争冒险存在于内核驱动层和应用层中。主要就是如果同时对同一文件操作,可能某任务操作到一半被另一任务执行,进而导致错误。
原子操作
对于文件读写问题,就是要将lseek移动偏移量和write写数据合成一个原子操作,多步一起,不能只执行一步。
之前的方法其实就是使用了O_APPEND标志来完成的原子操作。
pread()和pwrite()都是系统调用,与read()、write()函数的作用一样,用于读取和写入数据。区别在于,pread()和pwrite()可用于实现原子操作,调用pread函数或pwrite函数可传入一个位置偏移量offset参数,用于指定文件当前读或写的位置偏移量,所以调用pread相当于调用lseek后再调用read;同理,调用pwrite相当于调用lseek后再调用write。两个函数原型如下:
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
函数参数和返回值含义如下:
- fd、buf、count参数:与read或write函数意义相同。
- offset:表示当前需要进行读或写的位置偏移量。
- 返回值:返回值与read、write函数返回值意义一样。
但是pread和pwrite不会更新文件表中的当前位置偏移量。
如果多个进程都在open中有O_EXCL标志,那么此时文件不存在就会创建,变成一个原子操作,是的判断文件存在和创建编程一个整体不会分离。
fcntl和ioctl
fcntl函数
fcntl()函数可以对一个已经打开的文件描述符执行一系列控制操作,类似一个多功能文件描述符管理工具箱,原型如下:
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ )
函数参数和返回值如下:
- fd:文件描述符。
- cmd:操作命令。此参数表示将要对fd进行什么操作。cmd可以通过man手册来查看。
- …::fcntl 函数是一个可变参函数,第三个参数需要根据不同的cmd来传入对应的实参,配合cmd来使用。
- 返回值:执行失败情况下,返回-1,并且会设置errno;执行成功的情况下,其返回值与 cmd(操作命令)有关。
复制文件可以用F_DUPFD;获取/设置文件状态标志可以用F_GETFL/F_SETFL。
ioctl函数
ioctl()可以认为是一个文件IO操作的杂物箱,可以处理的事情非常杂、不统一,一般用于操作特殊文件或硬件外设。原型如下:
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
函数参数和返回值含义如下:
- fd:文件描述符。
- request:此参数与具体要操作的对象有关,没有统一值,表示向文件描述符请求相应的操作。
- …:此函数是一个可变参函数,第三个参数需要根据request参数来决定,配合request来使用。
- 返回值:成功返回0,失败返回-1。
截断文件
使用系统调用truncate()或ftruncate()可将普通文件截断为指定字节长度,其函数原型如下所示:
#include <unistd.h>
#include <sys/types.h>
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length);
这两个函数的区别在于:ftruncate()使用文件描述符fd来指定目标文件,而truncate()则直接使用文件路径path来指定目标文件,其功能一样。这里如果文件大小比length小,就会扩展,对扩展部分读取九四空字节"\0"。
使用ftruncate()函数进行文件截断操作之前,必须调用open()函数打开该文件得到文件描述符,并且必须要具有可写权限,也就是调用open()打开文件时需要指定O_WRONLY或O_RDWR。
调用这两个函数并不会导致文件读写位置偏移量发生改变;调用成功返回0,失败将回-1,并设置errno以指示错误原因。
标准I/O库
标准I/O虽然是对文件I/O进行了封装,但事实上并不仅仅只是如此,标准I/O会处理很多细节,譬如分配stdio缓冲区、以优化的块长度执行I/O等,这些处理使用户不必担心如何选择使用正确的块长度。
标准I/O库简介
标准I/O库是标准C库中用于文件I/O操作相关的一系列库函数的集合,通常标准I/O库函数相关的函数定义都在头文件<stdio.h>中。标准 I/O 库函数是构建于文件I/O(open()、read()、write()、lseek()、close()等)这些系统调用之上的。
标准I/O库可移植性好,实际就是调用文件I/O,有stdio缓冲区所以性能、效率更优。
FILE指针
对于标准I/O库函数来说,它们的操作是围绕FILE指针进行的,当使用标准I/O库函数打开或创建一个文件时,会返回一个指向 FILE 类型对象的指针(FILE *),使用该FILE指针与被打开或创建的文件相关联,然后该FILE指针就用于后续的标准I/O操作,类似文件描述符。FILE指针是一个结构体数据类型,包含了标准I/O库函数管理文件所需要的所有信息。
标准输入、标准输出和标准错误
标准输入设备指的就是计算机系统的标准的输入设备,通常指的是计算机所连接的键盘;而标准输出设备指的是计算机系统中用于输出标准信息的设备,通常指的是计算机所连接的显示器;标准错误设备则指的是计算机系统中用于显示错误信息的设备,通常也指的是显示器设备。
每个进程启动之后都会默认打开标准输入、标准输出以及标准错误,得到三个文件描述符,即 0、1、2,其中0代表标准输入、1代表标准输出、2代表标准错误;在应用编程中可以使用宏STDIN_FILENO、STDOUT_FILENO和STDERR_FILENO分别代表0、1、2,这些宏定义在unistd.h头文件中;而对于标准I/O,定义在stdio.h头文件中。
打开文件fopen()
在标准I/O 中,我们将使用库函数
fopen()打开或创建文件,fopen()函数原型如下所示:
#include <stdio.h>
FILE *fopen(const char *path, const char *mode);
函数参数和返回值含义如下:
- path:参数path指向文件路径,可以是绝对路径、也可以是相对路径。
- mode:参数mode指定了对该文件的读写权限,是一个字符串。
- 返回值:调用成功返回一个指向FILE类型对象的指针(FILE *),该指针与打开或创建的文件相关联,后续的标准I/O操作将围绕FILE指针进行。如果失败则返回NULL,并设置errno以指示错误原因。
读写文件
当使用fopen()库函数打开文件之后,可以使用fread()和fwrite()库函数对文件进行读、写操
作了,函数原型如下所示:
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
fread()参数和返回值含义如下:
- ptr:fread()将读取到的数据存放在参数ptr指向的缓冲区中;
- size:fread()从文件读取nmemb个数据项,每一个数据项的大小为size个字节,所以总共读取的数据大小为nmemb * size个字节。
- nmemb:指定了读取数据项的个数。
- stream:FILE 指针。
- 返回值:调用成功时返回读取到的数据项的数目(数据项数目并不等于实际读取的字节数,除非参数size等于1);如果发生错误或到达文件末尾,则fread()返回的值将小于参数nmemb,fread()不能区分文件结尾和错误,可以使用ferror()或feof()函数来判断。
fwrite()函数参数和返回值含义如下:
- ptr:将参数ptr指向的缓冲区中的数据写入到文件中。
- size:参数size指定了每个数据项的字节大小,与fread()函数的size参数意义相同。
- nmemb:指定了写入的数据项个数。
- stream:FILE指针。
- 返回值:调用成功时返回写入的数据项的数目(数据项数目并不等于实际写入的字节数,除非参数size等于1);如果发生错误,则fwrite()返回的值将小于参数nmemb(或者等于0)。
调用库函数fread()、fwrite()读写文件时,文件的读写位置偏移量会自动递增!
fseek定位
fseek()作用类似系统调用lseek(),用于设置文件读写位置偏移量,原型如下:
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
函数参数和返回值含义如下:
- stream:FILE指针。
- offset:与lseek()函数的offset参数意义相同。
- whence:与lseek()函数的whence参数意义相同。
- 返回值:成功返回0;发生错误将返回-1,并且会设置errno以指示错误原因。
文件开头处SEEK_SET;文件末尾SEEK_END。
ftell()函数可用于获取文件当前读写位置偏移量,原型如下:
#include <stdio.h>
long ftell(FILE *stream);
参数stream指向对应的文件,函数调用成功将返回当前读写位置偏移量;调用失败将返回-1,并会设置errno以指示错误原因。
检查或复位状态
调用fread()读取数据时,如果返回值小于参数nmemb所指定的值,表示发生了错误或者已经到了文件末尾,但fread()无法判断是哪一种,此时可通过判断错误标志或EOF标志来判断。
feof()函数
库函数feof()用于测试参数stream所指文件的end-of-file标志,如果end-of-file标志被设置了,则调用feof()函数将返回一个非零值,如果end-of-file标志没有被设置,则返回0。原型如下:
#include <stdio.h>
int feof(FILE *stream);
当文件的读写位置移动到了文件末尾时,end-of-file标志将会被设置。
ferror()函数
库函数ferror()用于测试参数stream所指文件的错误标志,如果错误标志被设置了,则调用ferror()函数将返回一个非零值,如果错误标志没有被设置,则返回0。原型如下:
#include <stdio.h>
int ferror(FILE *stream);
当对文件的I/O操作发生错误时,错误标志将会被设置。
clearerr()函数
库函数clearerr()用于清除end-of-file标志和错误标志。此函数无返回值且调用总会成功。原型如下:
#include <stdio.h>
void clearerr(FILE *stream);
格式化I/O
库函数printf()函数可将格式化数据写入到标准输出,所以通常称为格式化输出。除了printf()之外,格式化输出还包括:fprintf()、dprintf()、sprintf()、snprintf()这4个库函数。
格式化输出
C库函数提供了5个格式化输出函数,包括:printf()、fprintf()、dprintf()、sprintf()、snprintf(),其函数定义如下所示:
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int dprintf(int fd, const char *format, ...);
int sprintf(char *buf, const char *format, ...);
int snprintf(char *buf, size_t size, const char *format, ...);
这5个函数都是可变参函数,它们都有一个共同的参数 format,这是一个字符串,称为格式控制字符串,用于指定后续的参数如何进行格式转换,所以才把这些函数称为格式化输出。
printf()函数用于将格式化数据写入到标准输出;dprintf()和fprintf()函数用于将格式化数据写入到指定的文件中,两者不同之处在于,fprintf()使用FILE指针指定对应的文件、而dprintf()则使用文件描述符fd指定对应的文件;sprintf()、snprintf()函数可将格式化的数据存储在用户指定的缓冲区buf中。
printf很常用,不多说;dprintf和fprintf一个是FILE指针,一个是fd字符描述符,其他没什么区别;sprintf常用于转换格式,将例如整型转为字符串存入buf,末尾还会自动加上字符串终止字符’\0’;snprintf是为了解决sprintf缓冲溢出的问题,可用size指定buf大小,超出部分直接丢弃。
格式控制字符串format
格式控制字符串由两部分组成:普通字符(非%字符)和转换说明。转换说明都是以%开头,格式如下:
%[flags][width][.precision][length]type
- flags:标志,可包含0个或多个标志;
- width:输出最小宽度,表示转换后输出字符串的最小宽度;
- precision:精度,前面有一个点号" . ";
- length:长度修饰符;
- type:转换类型,指定待转换数据的类型。
这里type是必须的,一般也就是type制定一下数据类型。还会用precision,例如用%.3f来保留3位小数。
格式化输入
C库函数提供了3个格式化输入函数,包括:scanf()、fscanf()、sscanf(),其函数定义如下所示:
#include <stdio.h>
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);
int sscanf(const char *str, const char *format, ...);
这3个格式化输入函数也是可变参函数,它们都有一个共同的参数format,同样也称为格式控制字符串,用于指定输入数据如何进行格式转换,与格式化输出函数中的 format 参数格式相似,但也有所不同。
scanf()函数可将用户输入(标准输入)的数据进行格式化转换;fscanf()函数从FILE指针指定文件中读取数据,并将数据进行格式化转换;sscanf()函数从参数str所指向的字符串中读取数据,并将数据进行格式化转换。
scanf需要有输入地址(指针),指针指向对应缓冲区来存储格式化转换后数据;fscanf则需要在scanf基础上加上FILE指针;sscanf则是需要字符串str指向字符缓冲区。
格式控制字符串format
与格式化输出函数中的format参数格式、写法上比较相似,但也有一些区别。format字符串包含一个或多个转换说明,每一个转换说明都是以百分号"%“或者”%n$"开头(n 是一个十进制数字)。百分号开头一般格式如下:
%[*][width][length]type
%[m][width][length]type
%后面可选择性添加星号*或字母m,如果添加了星号*,格式化输入函数会按照转换说明的指示读取输入,但是丢弃输入,意味着不需要对转换后的结果进行存储,所以也就不需要提供相应的指针参数。
如果添加了m,它只能与%s、%c 以及%[一起使用,调用者无需分配相应的缓冲区来保存格式转换后的数据,原因在于添加了m,这些格式化输入函数内部会自动分配足够大小的缓冲区,并将缓冲区的地址值通过与该格式转换相对应的指针参数返回出来,该指针参数应该是指向char *变量的指针。随后,当不再需要此缓冲区时,调用者应调用free()函数来释放此缓冲区。
- width:最大字符宽度;
- length:长度修饰符,与格式化输出函数的format参数中的length字段意义相同。
- type:指定输入数据的类型。
例如输入字符串,就可以用%ms。
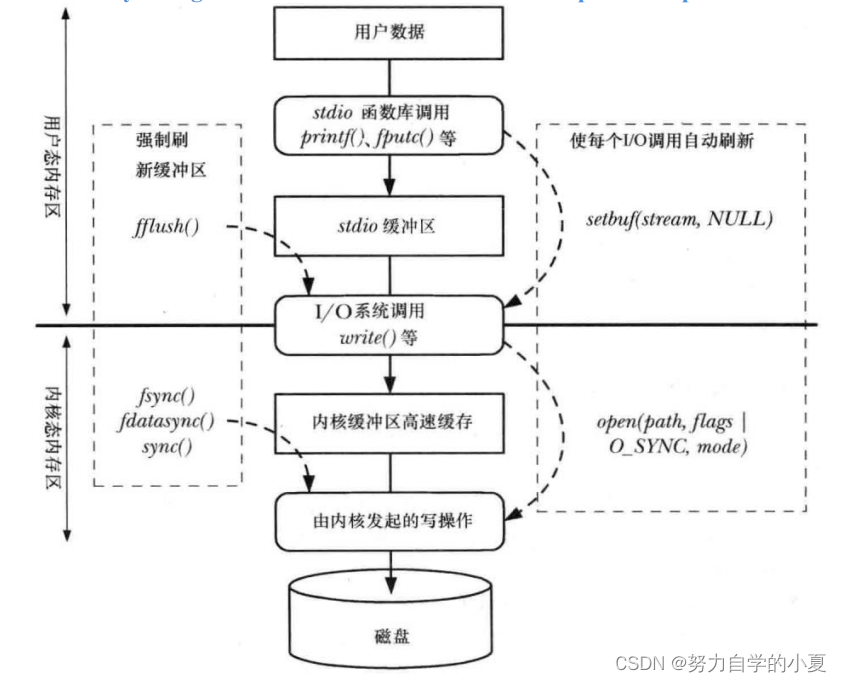
I/O缓冲
文件I/O的内核缓冲
read()和write()系统调用在进行文件读写操作的时候并不会直接访问磁盘设备,而是仅仅在用户空间缓冲区和内核缓冲区(kernel buffer cache)之间复制数据。
把这个内核缓冲区就称为文件I/O的内核缓冲。这样的设计,目的是为了提高文件 I/O 的速度和效率,使得系统调用read()、write()的操作更为快速,不需要等待磁盘操作)将数据写入到磁盘或从磁盘读取出数据),磁盘操作通常是比较缓慢的。同时这一设计也更为高效,减少了内核操作磁盘的次数。
刷新文件I/O的内核缓冲区
强制将文件I/O内核缓冲区中缓存的数据写入(刷新)到磁盘设备中。
Linux中提供了一些系统调用可用于控制文件I/O内核缓冲,包括系统调用sync()、syncfs()、fsync()以及fdatasync()。
fsync()函数
系统调用fsync()将参数fd所指文件的内容数据和元数据写入磁盘,只有在对磁盘设备的写入操作完成之后,fsync()函数才会返回,元数据并不是文件内容本身的数据,而是一些用于记录文件属性相关的数据信息,譬如文件大小、时间戳、权限等等信息,这里统称为文件的元数据,这些信息也是存储在磁盘设备中的。其函数原型如下所示:
#include <unistd.h>
int fsync(int fd);
参数fd表示文件描述符,函数调用成功将返回0,失败返回-1并设置errno以指示错误原因。
fdatasync()函数
系统调用fdatasync()与fsync()类似,不同之处在于fdatasync()仅将参数fd所指文件的内容数据写入磁盘,并不包括文件的元数据;同样,只有在对磁盘设备的写入操作完成之后fdatasync()函数才会返回,其函数原型如下所示:
#include <unistd.h>
int fdatasync(int fd);
sync()函数
系统调用sync()会将所有文件I/O内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中,该函数没有参数、也无返回值,意味着它不是对某一个指定的文件进行数据更新,而是刷新所有文件I/O内核缓冲区。其函数原型如下所示:
#include <unistd.h>
void sync(void);
在Linux实现中,调用sync()函数仅在所有数据已经写入到磁盘设备之后才会返回。
控制文件I/O内核缓冲标志
O_DSYNC标志
在调用open()函数时,指定O_DSYNC标志,其效果类似于在每个write()调用之后调用fdatasync()函数进行数据同步。
O_SYNC标志
在调用open()函数时,指定O_SYNC标志,使得每个write()调用都会自动将文件内容数据和元数据刷新到磁盘设备中,其效果类似于在每个write()调用之后调用fsync()函数进行数据同步。
大多数都不会用,因为频繁调用会对性能影响很大!
直接I/O:绕过内核缓冲
Linux允许应用程序在执行文件I/O操作时绕过内核缓冲区,从用户空间直接将数据传递到文件或磁盘设备,把这种操作也称为直接I/O(direct I/O)或裸 I/O(raw I/O)。
直接I/O会大大降低性能,一般只有在特定场合,如磁盘速率测试、数据库系统等中才有使用。
直接I/O对齐限制
- 应用程序中用于存放数据的缓冲区,其内存起始地址必须以块大小的整数倍进行对齐;
- 写文件时,文件的位置偏移量必须是块大小的整数倍;
- 写入到文件的数据大小必须是块大小的整数倍。
确定块的大小可以用如下命令:
| tune2fs -l /dev/sda1 | grep "Block size" |
-l就是需要查看的分区,可以用“df -h”在Ubuntu下查看根文件系统挂载分区。
使用直接I/O,需要使用O_DIRECT标志,此标志的使用需要在开头加上_GNU_SOURCE的宏定义。
stdio缓冲
虽然标准I/O是在文件I/O基础上进行封装而实现,但在效率、性能上标准I/O要优于文件I/O,其原因在于标准I/O 实现维护了自己的缓冲区,把这个缓冲区称为stdio缓冲区。标准I/O函数会将用户写入或读取文件的数据缓存在stdio缓冲区,然后再一次性将stdio缓冲区中缓存的数据通过调用系统调用I/O(文件 I/O)写入到文件I/O内核缓冲区或者拷贝到应用程序的buf中。
setvbuf()函数
调用setvbuf()库函数可以对文件的stdio缓冲区进行设置,譬如缓冲区的缓冲模式、缓冲区的大小、起始地址等。其函数原型如下所示:
#include <stdio.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
函数参数和返回值含义如下:
- stream:FILE指针,用于指定对应的文件,每一个文件都可以设置它对应的stdio缓冲区。
- buf:如果参数buf不为NULL,那么buf指向size大小的内存区域将作为该文件的stdio缓冲区。如果buf等于NULL,那么stdio库会自动分配一块空间作为该文件的stdio缓冲区(除非参数mode配置为非缓冲模式)。
- mode:参数mode用于指定缓冲区的缓冲类型。
- size:指定缓冲区大小。
- 返回值:成功返回0,失败将返回一个非0值,并且会设置errno来指示错误原因。
setbuf()函数
setbuf()函数构建于setvbuf()之上,执行类似的任务,其函数原型如下所示:
#include <stdio.h>
void setbuf(FILE *stream, char *buf);
要么将buf设置为NULL以表示无缓冲,要么指向由调用者分配的BUFSIZ个字节大小的缓冲区(定义在<stdio.h>中,一般为8192)。
setbuffer()函数
setbuffer()函数类似于setbuf(),但允许调用者指定buf缓冲区的大小,其函数原型如下所示:
#include <stdio.h>
void setbuffer(FILE *stream, char *buf, size_t size);
刷新stdio缓冲区
在任何时候都可以使用库函数fflush()来强制刷新stdio缓冲区,原型如下:
#include <stdio.h>
int fflush(FILE *stream);
参数stream指定需要进行强制刷新的文件,如果该参数设置为NULL,则表示刷新所有的stdio缓冲区。函数调用成功返回0,否则将返回-1,并设置errno以指示错误原因。
当然,除了fflush()强制刷新,程序在关闭文件、程序退出时都会刷新stdio缓冲区。
I/O缓冲小节
文件描述符与FILE指针互转
可以借助于库函数fdopen()、fileno()来完成互转。库函数fileno()可以将标准I/O中使用的FILE指针转换为文件I/O中所使用的文件描述符,而fdopen()则进行着相反的操作,其函数原型如下所示:
#include <stdio.h>
int fileno(FILE *stream);
FILE *fdopen(int fd, const char *mode);
当混合使用文件I/O和标准I/O时,需要特别注意缓冲的问题,文件I/O会直接将数据写入到内核缓冲区进行高速缓存,而标准I/O则会将数据写入到stdio缓冲区,之后再调用write()将stdio缓冲区中的数据写入到内核缓冲区。
文件属性与目录
从系统调用stat开始,可利用其返回一个包含多种文件属性(包括文件时间戳、文件所有权以及文件权限等)的结构体来学习stat结构中的每一个成员以了解文件的所有属性,然后将学习用以改变文件属性的各种系统调用;除此之外,还会学习Linux系统中的符号链接以及目录相关的操作。
Linux系统中文件类型
Linux系统并不会通过后缀来识别文件,但是文件后缀也要规范、需要根据文件本身的功能属性来添加。一共有7种文件类型。
普通文件
普通文件(regular file)在Linux系统下是最常见的,譬如文本文件、二进制文件还有自己写的代码文件;普通文件中的数据存在系统磁盘中,可以访问文件中的内容,文件中的内容以字节为单位进行存储于访问。可分为两大类:文本文件和二进制文件:
- 文本文件:文件中的内容是由文本构成的,所谓文本指的是ASCII码字符。文件中的内容其本质上都是数字,而文本文件中的数字应该被理解为这个数字所对应的ASCII字符码;譬如常见的.c、.h、.sh、.txt等这些都是文本文件,文本文件的好处就是方便人阅读、浏览以及编写。
- 二进制文件:二进制文件中存储的本质上也是数字,只不过对于二进制文件来说,这些数字并不是文本字符编码,而是真正的数字。譬如Linux系统下的可执行文件、C代码编译之后得到的.o 文件、.bin文件等都是二进制文件。
可以通过stat命令或者ls命令来查看文件类型。
目录文件
目录(directory)就是文件夹,文件夹在Linux系统中也是一种文件,是一种特殊文件。
字符设备文件和块设备文件
Linux系统中,可将硬件设备分为字符设备和块设备,所以就有了字符设备文件和块设备文件两种文件类型。但是设备文件并不对应磁盘上的一个文件,也就是说设备文件并不存在于磁盘中,而是由文件系统虚拟出来的,一般是由内存来维护,当系统关机时,设备文件都会消失。字符设备文件一般在/dev/目录下。
符号链接文件
符号链接文件(link)类似于Windows系统中的快捷方式文件,是一种特殊文件,它的内容指向的是另一个文件路径。
管道文件
管道文件(pipe)主要用于进程间通信。
套接字文件
套接字文件(socket)也是一种进程间通信的方式,与管道文件不同的是,它们可以在不同主机上的进程间通信,实际上就是网络通信。
stat函数
Linux下可以使用stat命令查看文件的属性,是系统调用,原型如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *pathname, struct stat *buf);
函数参数及返回值含义如下:
- pathname:用于指定一个需要查看属性的文件路径。
- buf:struct stat类型指针,用于指向一个struct stat结构体变量。调用stat函数的时候需要传入一个struct stat变量的指针,获取到的文件属性信息就记录在struct stat结构体中。
- 返回值:成功返回0;失败返回-1,并设置error。
具体的stat结构体,st_mode变量,timespec结构体可以具体看教程,这里记笔记没什么意义。
判断文件类型,可以通过st.st_mode&S_IFMT然后与文件类型的宏定义比对得到;也可以直接用封装好的宏,例如S_ISREG(st.st_mode)判断。
判断文件权限,可以用st.st_mode直接与权限宏定义&操作,返回的true就是有权限。
localtime_r就可以查看访问的时间,传入对应的st的成员变量的tv_sec,读到自定义的tm结构体中然后strftime转成字符串printf出来查看就可以了。
fstat和lstat函数
还可以使用fstat和lstat两个系统调用来获
取文件属性信息。
fstat函数
fstat与stat区别在于,stat是从文件名出发得到文件属性信息,不需要先打开文件;而fstat 函数则是从文件描述符出发得到文件属性信息,所以使用fstat函数之前需要先打开文件得到文件描述符。如果文件已经打开了就可以用fstat,原型如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int fstat(int fd, struct stat *buf);
第一个参数fd表示文件描述符,第二个参数以及返回值与stat一样。
lstat函数
lstat与stat、fstat的区别在于,对于符号链接文件,stat、fstat查阅的是符号链接文件所指向的文件对应的文件属性信息,而lstat查阅的是符号链接文件本身的属性信息。原型如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int lstat(const char *pathname, struct stat *buf);
文件属组
Linux是一个多用户操作系统,系统中一般存在着好几个不同的用户,而Linux系统中的每一个文件都有一个与之相关联的用户和用户组,通过这个信息可以判断文件的所有者和所属组。在Linux中,系统并不是通过用户名或用户组名来识别不同的用户和用户组,而是通过ID。系统通过用户ID(UID)或组ID(GID)就可以识别出不同的用户和用户组。
**可以使用ls或者stat命令来查看文件所有者和所属组。**文件的用户ID和组ID分别由struct stat结构体中的st_uid和st_gid所指定。
对于进程而言,有5个相关ID:
- 实际用户ID和实际组ID标识我们究竟是谁,也就是执行该进程的用户是谁、以及该用户对应的所属组;实际用户ID和实际组ID确定了进程所属的用户和组。
- 进程的有效用户ID、有效组ID以及附属组ID用于文件访问权限检查。
有效用户ID和有效组ID
只有进程有此概念。有效用户ID和有效组ID是站在操作系统的角度,用于给操作系统判断当前执行该进程的用户在当前环境下对某个文件是否拥有相应的权限。大多数情况下,其与实际ID是一致的。
chown函数
chown是一个系统调用,该系统调用可用于改变文件的所有者(用户 ID)和所属组(组 ID)。原型如下:
#include <unistd.h>
int chown(const char *pathname, uid_t owner, gid_t group);
函数参数和返回值如下所示:
- pathname:用于指定一个需要修改所有者和所属组的文件路径。
- owner:将文件的所有者修改为该参数指定的用户(以用户 ID 的形式描述);
- group:将文件的所属组修改为该参数指定的用户组(以用户组 ID 的形式描述);
- 返回值:成功返回0;失败将返回-1,并且会设置errno。
这里要注意,只有超级用户进程能更改文件的用户ID。对于Linux系统内,就sudo一下就可以了。
在Linux系统下,可以使用getuid和getgid两个系统调用分别用于获取当前进程的用户ID和用户组ID,这里说的进程的用户ID和用户组ID指的就是进程的实际用户ID和实际组ID,这两个系统调用函数原型如下所示:
#include <unistd.h>
#include <sys/types.h>
uid_t getuid(void);
gid_t getgid(void);
fchown和lchown函数
这两个也都是系统调用,与chown相同。就与fstat、lstat与stat的关系一样,这里就不赘述。
文件访问权限
struct stat结构体中的st_mode字段记录了文件的访问权限位。所有文件都有访问权限。
普通权限与特殊权限
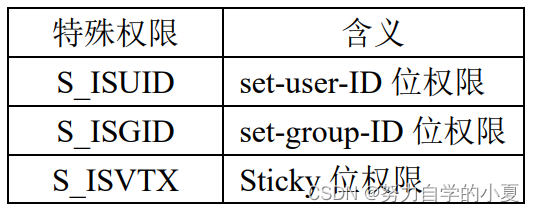
文件的权限可以分为两个大类,分别是普通权限和特殊权限(也可称为附加权限)。普通权限包括对文件的读、写以及执行,而特殊权限则包括一些对文件的附加权限,譬如Set-User-ID、Set-Group-ID以及Sticky。
普通权限,包含3类,文件所有者、同组、其他用户的读、写、执行权限。可通过"ls -l"命令查看。权限对应的就是"rwx"。
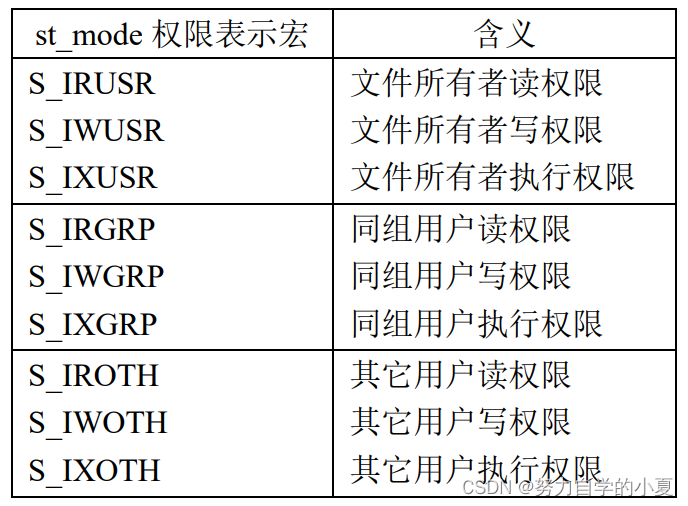
权限的判断,要先看进程的用户ID,如果一样就直接是文件所有者;不一样就看用户组ID,一样就是同组的;如果还不一样那就是其他用户。如果有效用户ID是0,那就直接拥有最高权限(root用户)。
特殊权限在st_mode中,是除了9个普通权限之外的3个特殊权限。这里的作用就是,如果设置了,那么就会按着设置的那个位的权限来操作文件。
目录权限
目录权限与普通文件的权限含义不同:
- 目录的读权限:可列出(譬如:通过ls命令)目录之下的内容(即目录下有哪些文件)。
- 目录的写权限:可以在目录下创建文件、删除文件。
- 目录的执行权限:可访问目录下的文件,譬如对目录下的文件进行读、写、执行等操作。
检查文件权限access
文件的权限检查不单单只讨论文件本身的权限,还需要涉及到文件所在目录的权限,只有同时都满足了,才能通过操作系统的权限检查,进而才可以对文件进行相关操作。可通过access系统调用检查,原型如下:
#include <unistd.h>
int access(const char *pathname, int mode);
函数参数和返回值含义如下:
- pathname:需要进行权限检查的文件路径。
- mode:该参数可以取以下值:
- F_OK:检查文件是否存在
- R_OK:检查是否拥有读权限
- W_OK:检查是否拥有写权限
- X_OK:检查是否拥有执行权限
- 返回值:检查项通过则返回0,表示拥有相应的权限并且文件存在;否则返回-1,如果多个检查项组合在一起,只要其中任何一项不通过都会返回-1。
修改文件权限chmod
在Linux系统下,可以使用chmod命令修改文件权限,该命令内部实现方法其实是调用了chmod函数,chmod函数是一个系统调用,原型如下:
#include <sys/stat.h>
int chmod(const char *pathname, mode_t mode);
函数参数及返回值如下所示:
- pathname:需要进行权限修改的文件路径,若该参数所指为符号链接,实际改变权限的文件是符号链接所指向的文件,而不是符号链接文件本身。
- mode:该参数用于描述文件权限,与open函数的第三个参数一样。
- 返回值:成功返回0;失败返回-1,并设置errno。
也可以用fchmod函数,其使用文件描述符代替文件路径,原型如下:
#include <sys/stat.h>
int fchmod(int fd, mode_t mode);
umask函数
umask命令用于查看/设置权限掩码,权限掩码主要用于对新建文件的权限进行屏蔽。umask在Ubuntu中一般为0002,调用open函数新建文件时,文件实际的权限并不等于mode参数所描述的权限,而是通过如下关系得到实际权限:
| mode & ~umask |
Linux系统提供了umask函数用于设置进程的权限掩码,该函数是一个系统调用,函数原型如下:
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);
函数参数和返回值含义如下:
- mask:需要设置的权限掩码值,可以发现make参数的类型与open函数、chmod函数中的mode参数对应的类型一样,所以其表示方式也是一样的。
- 返回值:返回设置之前的umask值,也就是旧的umask。
umask是进程自身的一种属性、A进程的umask与B进程的umask无关。
文件时间属性
在struct stat结构体的st_atim、st_mtim以及st_ctim变量中:

这里的状态改变是指文件的inode节点被改变。即改变文件的访问权限、文件的用户ID、用户组ID等。
utime()、utimes()修改时间属性
文件的时间属性虽然会在对文件进行相关操作的时候发生改变,但这些改变都是隐式、被动的发生改变,除此之外,还可以使用Linux系统提供的系统调用显式的修改文件的时间属性。
utime()函数原型如下:
#include <sys/types.h>
#include <utime.h>
int utime(const char *filename, const struct utimbuf *times);
函数参数和返回值含义如下:
- filename:需要修改时间属性的文件路径。
- times:将时间属性修改为该参数所指定的时间值,times是一个struct utimbuf结构体类型的指针,如果将times参数设置为NULL,则会将文件的访问时间和修改时间设置为系统当前时间。
- 返回值:成功返回值0;失败将返回-1,并会设置errno。
struct utimbuf结构体有2个time_t类型成员,用于表示访问时间和内容修改时间,以秒为单位。
使用时可以用time()这个Linux系统调用获取当前时间,然后设置utimbuf结构体的成员变量然后utime()修改文件的时间戳。
utimes()函数也是系统调用,与utime()最大
的区别在于前者可以以微秒级精度来指定时间值,其函数原型如下所示:
#include <sys/time.h>
int utimes(const char *filename, const struct timeval times[2]);
函数参数和返回值含义如下:
- filename:需要修改时间属性的文件路径。
- times:将时间属性修改为该参数所指定的时间值,times是一个struct timeval结构体类型的数组,数组共有两个元素,第一个元素用于指定访问时间,第二个元素用于指定内容修改时间,如果times参数为NULL,则会将文件的访问时间和修改时间设置为当前时间。
- 返回值:成功返回0;失败返回-1,并且会设置errno。
struct timeval结构体中,就是两个成员变量tv_sec和rv_usec,表示秒和微秒。
utimes()使用方法是跟utime()一样的。
futimens()、utimensat()修改时间属性
这两个系统调用相对于utime和utimes函数有以下三个优点:
- 可按纳秒级精度设置时间戳。相对于提供微秒级精度的utimes(),这是重大改进!
- 可单独设置某一时间戳。
- 可独立将任一时间戳设置为当前时间。
futimens()函数原型如下:
#include <fcntl.h>
#include <sys/stat.h>
int futimens(int fd, const struct timespec times[2]);
函数原型和返回值含义如下:
- fd:文件描述符。
- times:将时间属性修改为该参数所指定的时间值,times指向拥有2个struct timespec结构体类型变量的数组,数组共有两个元素,第一个元素用于指定访问时间,第二个元素用于指定内容修改时间。
- 返回值:成功返回0;失败将返回-1,并设置errno。
使用futimens()需要有超级用户进程,或者times=NULL,或者用户ID匹配才可使用来修改文件时间戳。
utimensat()函数可以直接用文件路径方式进行操作,功能与futimens()是一样的,原型如下:
#include <fcntl.h>
#include <sys/stat.h>
int utimensat(int dirfd, const char *pathname, const struct timespec times[2], int flags);
函数参数和返回值含义如下:
- dirfd:该参数可以是一个目录的文件描述符,也可以是特殊值AT_FDCWD;如果pathname参数指定的是文件的绝对路径,则此参数会被忽略。
- pathname:指定文件路径。如果pathname参数指定的是一个相对路径、并且dirfd参数不等于特殊值AT_FDCWD,则实际操作的文件路径是相对于文件描述符dirfd指向的目录进行解析。如果pathname参数指定的是一个相对路径、并且dirfd参数等于特殊值AT_FDCWD,则实际操作的文件路径是相对于调用进程的当前工作目录进行解析。
- times:与futimens()的times参数含义相同。
- flags : 此参数可以为0 , 也可以设置为AT_SYMLINK_NOFOLLOW , 如果设置为AT_SYMLINK_NOFOLLOW,当pathname参数指定的文件是符号链接,则修改的是该符号链接的时间戳,而不是它所指向的文件。
- 返回值:成功返回0;失败返回-1、并会设置时间戳。
符号链接(软链接)与硬链接
在Linux系统中有两种链接文件,分为软链接(也叫符号链接)文件和硬链接文件,软链接文件也就是七种文件类型之一,其作用类似于Windows下的快捷方式。
可以用ln命令创建链接文件:硬链接直接ln就可以,软链接需要ln -s。
硬链接文件与源文件有相同inode号,指向了物理硬盘的同一区块,证明硬链接文件与源文件是完全平等的文件。struct stat结构体中的st_nlink就是记录了文件的链接数;增减硬链接文件就是inode节点上的链接数的增减。
软链接文件与源文件有着不同的inode号,所以也就是意味着它们之间有着不同的数据块,但是软链接文件的数据块中存储的是源文件的路径名,链接文件可以通过这个路径找到被链接的源文件;原文件删除后,软链接文件指向了无效文件路径,被称为悬空链接。
硬链接是有限制的:
- 不能对目录创建硬链接(超级用户可以创建,但必须在底层文件系统支持的情况下)。
- 硬链接通常要求链接文件和源文件位于同一文件系统中。
而软链接文件的使用并没有上述限制条件,优点如下所示:
- 可以对目录创建软链接;
- 可以跨越不同文件系统;
- 可以对不存在的文件创建软链接。
创建链接文件
创建硬链接link()
原型如下:
#include <unistd.h>
int link(const char *oldpath, const char *newpath);
函数原型和返回值含义如下:
- oldpath:用于指定被链接的源文件路径,应避免oldpath参数指定为软链接文件。
- newpath:用于指定硬链接文件路径,如果newpath指定的文件路径已存在,则会产生错误。
- 返回值:成功返回0;失败将返回-1,并且会设置errno。
创建软链接symlink()
原型如下:
#include <unistd.h>
int symlink(const char *target, const char *linkpath);
函数参数和返回值含义如下:
- target:用于指定被链接的源文件路径,target参数指定的也可以是一个软链接文件。
- linkpath:用于指定硬链接文件路径,如果newpath指定的文件路径已存在,则会产生错误。
- 返回值:成功返回0;失败将返回-1,并会设置errno。
读取软链接文件
使用系统调用readlink,函数原型如下所示:
#include <unistd.h>
ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);
函数参数和返回值含义如下:
- pathname:需要读取的软链接文件路径。只能是软链接文件路径,不能是其它类型文件,否则调用函数将报错。
- buf:用于存放路径信息的缓冲区。
- bufsiz:读取大小,一般读取的大小需要大于链接文件数据块中存储的文件路径信息字节大小。
- 返回值:失败将返回-1,并会设置errno;成功将返回读取到的字节数。
目录
在Linux系统下,会有一些专门的系统调用或C库函数用于对文件夹进行操作。
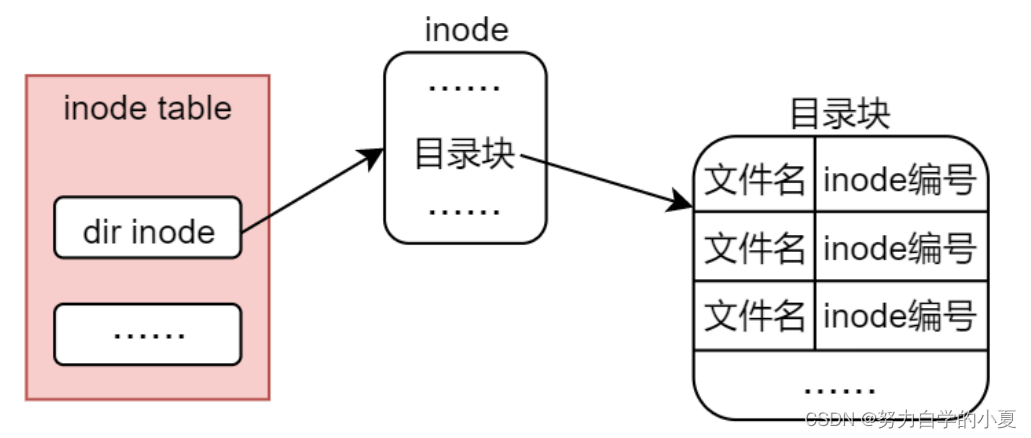
目录存储形式
目录在文件系统中的存储方式与常规文件类似,其存储形式则是由inode节点和目录块所构成,目录块当中记录了有哪些文件组织在这个目录下,记录它们的文件名以及对应的inode编号。如下图所示:
创建和删除目录
在Linux系统下,提供了专门用于创建目录mkdir以及删除目录rmdir相关的系统调用。
mkdir函数原型如下:
#include <sys/stat.h>
#include <sys/types.h>
int mkdir(const char *pathname, mode_t mode);
函数参数和返回值含义如下:
- pathname:需要创建的目录路径。
- mode:新建目录的权限设置,设置方式与open函数的mode参数一样,最终权限为(mode & ~umask)。
- 返回值:成功返回0;失败将返回-1,并会设置errno。
pathname可以是相对路径。
rmdir函数原型如下:
#include <unistd.h>
int rmdir(const char *pathname);
函数参数和返回值含义如下:
- pathname:需要删除的目录对应的路径名,并且该目录必须是一个空目录,也就是该目录下只有.和…这两个目录项;pathname指定的路径名不能是软链接文件,即使该链接文件指向了一个空目录。
- 返回值:成功返回0;失败将返回-1,并会设置errno。
打开、读取和关闭目录
opendir()函数用于打开一个目录,并返回指向该目录的句柄,供后续操作使用。opendir是一个C库函数,opendir()函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *name);
函数参数和返回值含义如下:
- name:指定需要打开的目录路径名,可以是绝对路径,也可以是相对路径。
- 返回值:成功将返回指向该目录的句柄,一个DIR指针(其实质是一个结构体指针),其作用类似于open函数返回的文件描述符fd,后续对该目录的操作需要使用该DIR指针变量;若调用失败,则返回NULL。
readdir()用于读取目录,获取目录下所有文件的名称以及对应inode号。readdir()是一个C库函数,其函数原型如下所示:
#include <dirent.h>
struct dirent *readdir(DIR *dirp);
函数参数和返回值含义如下:
- dirp:目录句柄DIR指针。
- 返回值:返回一个指向struct dirent结构体的指针,该结构体表示dirp指向的目录流中的下一个目录条目。在到达目录流的末尾或发生错误时,返回NULL。
struct dirent结构体内容如下:

只需要关注d_ino和d_name两个字段即可,分别记录了文件的inode编号和文件名。每调用一次readdir(),就会从drip所指向的目录流中读取下一条目录项(目录条目),并返回struct dirent结构体指针,指向经静态分配而得的struct dirent类型结构,每次调用readdir()都会覆盖该结构。一旦遇到目录结尾或是出错,readdir()将返回NULL,针对后一种情况,还会设置errno以示具体错误,通过如下代码判断具体错误:
error = 0;
direntp = readdir(dirp);
if (NULL == direntp) {
if (0 != error) {
/* 出现了错误 */
} else {
/* 已经到了目录末尾 */
}
}
rewinddir()是C库函数,可将目录流重置为目录起点,以便对readdir()的下一次调用将从目录列表中的第一个文件开始。rewinddir函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
void rewinddir(DIR *dirp);
函数参数和返回值含义如下:
- dirp:目录句柄。
- 返回值:无返回值。
closedir()函数用于关闭处于打开状态的目录,同时释放它所使用的资源,其函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
int closedir(DIR *dirp);
函数参数和返回值含义如下:
- dirp:目录句柄。
- 返回值:成功返回0;失败将返回-1,并设置errno。
进程的当前工作目录
Linux下的每一个进程都有自己的当前工作目录(current working directory),当前工作目录是该进程解析、搜索相对路径名的起点(不是以" / "斜杆开头的绝对路径)。
一般情况下,运行一个进程时、其父进程的当前工作目录将被该进程所继承,成为该进程的当前工作目录。可通过getcwd函数来获取进程的当前工作目录,如下所示:
#include <unistd.h>
char *getcwd(char *buf, size_t size);
函数参数和返回值含义如下:
- buf:getcwd()将内含当前工作目录绝对路径的字符串存放在buf缓冲区中。
- size:缓冲区的大小,分配的缓冲区大小必须要大于字符串长度,否则调用将会失败。
- 返回值:如果调用成功将返回指向buf的指针,失败将返回NULL,并设置errno。
系统调用chdir()和fchdir()可以用于更改进程的当前工作目录,函数原型如下所示:
#include <unistd.h>
int chdir(const char *path);
int fchdir(int fd);
函数参数和返回值含义如下:
- path:将进程的当前工作目录更改为path参数指定的目录,可以是绝对路径、也可以是相对路径,指定的目录必须要存在,否则会报错。
- fd:将进程的当前工作目录更改为fd文件描述符所指定的目录。
- 返回值:成功均返回0;失败均返回-1,并设置errno。
chdir()通过路径方式指定;fchdir()则是通过文件描述符(可调用open()打开相应目录)。
删除文件
unlink()用于删除一个文件(不包括目录),函数原型如下所示:
#include <unistd.h>
int unlink(const char *pathname);
函数参数和返回值含义如下:
- pathname:需要删除的文件路径,可使用相对路径、也可使用绝对路径,如果pathname参数指定的文件不存在,则调用unlink()失败。
- 返回值:成功返回0;失败将返回-1,并设置errno。
unlink()系统调用实质上是移除pathname参数指定的文件路径对应的目录项(从其父级目录中移除该目录项),并将文件的inode链接计数置1,如果该文件还有其它硬链接,则仍可通过其它链接访问该文件的数据;只有当链接计数变为0时,该文件的内容才可被删除。如果是软链接文件,则删除的是软链接文件本身。
remove()是一个C库函数,用于移除一个文件或空目录,其函数原型如下所示:
#include <stdio.h>
int remove(const char *pathname);
函数参数和返回值含义如下:
- pathname:需要删除的文件或目录路径,可以是相对路径、也可是决定路径。
- 返回值:成功返回0;失败将返回-1,并设置errno。
如果是软链接文件,则remove()会删除链接文件本身、而非所指向的文件。
文件重命名
rename()既可以对文件进行重命名,又可以将文件移至同一文件系统中的另一个目录下,其函数原型如下所示:
#include <stdio.h>
int rename(const char *oldpath, const char *newpath);
函数参数和返回值含义如下:
- oldpath:原文件路径。
- newpath:新文件路径。
- 返回值:成功返回0;失败将返回-1,并设置errno。
rename()调用仅操作目录条目,而不移动文件数据(不改变文件inode编号、不移动文件数据块中存储的内容),重命名既不影响指向该文件的其它硬链接,也不影响已经打开该文件的进程。
字符串处理
C语言库函数中已经提供了丰富的字符串处理相关函数,基本常见的字符串处理需求都可以直接使用这些库函数来实现,而不需要自己编写代码,使用这些库函数可以大大减轻编程负担。这些库函数大致可以分为字符串的输入、输出、合并、修改、比较、转换、复制、搜索等几类。
字符串输入/输出
输出
putchar()、puts()、fputc()、fputs()这些函数只能输出字符串,不能进行格式转换。printf()可以格式化输出,所以使用更多,但之前这些函数用起来更简单。
puts()函数用来向标准输出设备(屏幕、显示器)输出字符串并自行换行。把字符串输出到标准输出设备,将’ \0 ‘转换为换行符’ \n '。原型如下:
#include <stdio.h>
int puts(const char *s);
函数参数和返回值含义如下:
- s:需要进行输出的字符串。
- 返回值:成功返回一个非负数;失败将返回EOF,EOF其实就是-1。
putchar()函数可以把参数c指定的字符(一个无符号字符)输出到标准输出设备,其输出可以是一个字符,可以是介于0-127之间的一个十进制整型数(包含0和127,输出其对应的ASCII码字符),也可以是用char类型定义好的一个字符型变量。原型如下:
#include <stdio.h>
int putchar(int c);
函数参数和返回值含义如下:
- c:需要进行输出的字符。
- 返回值:出错将返回EOF。
fputc()与putchar()类似,也用于输出参数c指定的字符(一个无符号字符),与putchar()区别在于,putchar()只能输出到标准输出设备,而 fputc()可把字符输出到指定的文件中,既可以是标准输出、标准错误设备,也可以是一个普通文件。原型如下:
#include <stdio.h>
int fputc(int c, FILE *stream);
函数参数和返回值含义如下:
- c:需要进行输出的字符。
- stream:文件指针。
- 返回值:成功时返回输出的字符;出错将返回EOF。
fputs()与puts()类似,也用于输出一条字符串,与puts()区别在于,puts()只能输出到标准输出设备,而fputs()可把字符串输出到指定的文件中,既可以是标准输出、标准错误设备,也可以是一个普通文件。原型如下:
#include <stdio.h>
int fputs(const char *s, FILE *stream);
函数参数和返回值含义如下:
- s:需要输出的字符串。
- stream:文件指针。
- 返回值:成功返回非负数;失败将返回EOF。
输入
scanf()与gets()、getchar()、fgetc()、fgets()这些函数相比,在功能上确实有它的优势,但是在使用上不如它们方便、简单、更易于使用。
gets()函数用于从标准输入设备(譬如键盘)中获取用户输入的字符串,原型如下:
#include <stdio.h>
char *gets(char *s);
函数参数和返回值含义如下:
- s:指向字符数组的指针,用于存储字符串。
- 返回值:如果成功,该函数返回指向s的指针;如果发生错误或者到达末尾时还未读取任何字符,则返回NULL。
gets()函数是不推荐使用的,在Ubuntu中编译就会出现警告。
gets()允许输入字符串有空格,且会将回车换行符在输入缓冲区中取出并丢弃。
getchar()函数用于从标准输入设备中读取一个字符(一个无符号字符),原型如下:
#include <stdio.h>
int getchar(void);
函数参数和返回值含义如下:
- 无需传参。
- 返回值:该函数以无符号char强制转换为int的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回EOF。
getchar()只读取1个字符,包括空格,TAB,换行回车等。
fgets()与gets()一样用于获取输入的字符串,fgets()函数原型如下所示:
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
函数参数和返回值含义如下:
- s:指向字符数组的指针,用于存储字符串。
- size:这是要读取的最大字符数。
- stream:文件指针。
fgets()既可以从标准输入设备获取字符串、也可以从一个普通文件中获取输入字符串。可以设置字符串的最大字符数。会将换行符读取但是不会丢弃,而是作为字符串的组成字符存在,读取结束自动添加结束字符’\0’。
fgetc()与getchar()一样,用于读取一个输入字符,函数原型如下所示:
#include <stdio.h>
int fgetc(FILE *stream);
函数参数和返回值含义如下:
- stream:文件指针。
- 返回值:该函数以无符号char强制转换为int的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回EOF。
fgetc()可以指定输入字符的文件,既可以从标准输入设备输入字符,也可以从一个普通文件中输入字符。
字符串长度
C语言函数库中提供了一个用于计算字符串长度的函数strlen(),其函数原型如下所示:
#include <string.h>
size_t strlen(const char *s);
函数参数和返回值含义如下:
- s:需要进行长度计算的字符串,字符串必须包含结束字符’\0’。
- 返回值:返回字符串长度(以字节为单位),字符串结束字符’\0’不计算在内。
sizeof和strlen的区别如下:
- sizeof是C语言内置的操作符关键字,而strlen是C语言库函数;
- sizeof仅用于计算数据类型的大小或者变量的大小,而strlen只能以结尾为’\0’的字符串作为参数;
- 编译器在编译时就计算出了sizeof的结果,而strlen必须在运行时才能计算出来;
- sizeof计算数据类型或变量会占用内存的大小,strlen计算字符串实际长度。
字符串拼接
strcat()函数或strncat()函数用于将两个字符串连接起来,strcat函数原型如下所示:
#include <string.h>
char *strcat(char *dest, const char *src);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- 返回值:返回指向目标字符串dest的指针。
必须要保证dest有足够的存储空间来容纳两个字符串,否则会导致溢出错误。
strncat()与strcat()的区别在于,strncat()可以指定源字符串追加到目标字符串的字符数量,原型如下:
#include <string.h>
char *strncat(char *dest, const char *src, size_t n);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- n:要追加的最大字符数。
- 返回值:返回指向目标字符串dest的指针。
字符串拷贝
C语言函数库中提供了strcpy()函数和strncpy()函数用于实现字符串拷贝,strcpy函数原型如下所示:
#include <string.h>
char *strcpy(char *dest, const char *src);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- 返回值:返回指向目标字符串dest的指针。
strcpy()会把src(必须包含结束字符’\0’)指向的字符串复制(包括字符串结束字符’\0’)到dest,所以必须保证dest指向的内存空间足够大,能够容纳下src字符串,否则会导致溢出错误。
strncpy()与strcpy()的区别在于,strncpy()可以指定从源字符串src复制到目标字符串dest的字符数量,strncpy函数原型如下所示:
#include <string.h>
char *strncpy(char *dest, const char *src, size_t n);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- n:从src中复制的最大字符数。
- 返回值:返回指向目标字符串dest的指针。
还可以使用memcpy()、memmove()以及bcopy()这些库函数实现拷贝操作,字符串拷贝本质上也只是内存数据的拷贝,所以这些库函数同样也是适用的。
内存填充
memset()函数用于将某一块内存的数据全部设置为指定的值,原型如下:
#include <string.h>
void *memset(void *s, int c, size_t n);
函数参数和返回值含义如下:
- s:需要进行数据填充的内存空间起始地址。
- c:要被设置的值,该值以int类型传递。
- n:填充的字节数。
- 返回值:无返回值。
bzero()函数用于将一段内存空间中的数据全部设置为0,原型如下:
#include <strings.h>
void bzero(void *s, size_t n);
函数参数和返回值含义如下:
- s:内存空间的起始地址。
- n:填充的字节数。
- 返回值:无返回值。
字符串比较
C语言函数库提供了用于字符串比较的函数strcmp()和strncmp(),strcmp()函数原型如下所示:
#include <string.h>
int strcmp(const char *s1, const char *s2);
函数参数和返回值含义如下:
- s1:进行比较的字符串1。
- s2:进行比较的字符串2。
- 返回值:如果返回值小于0,str1小于str2;如果返回值大于0,str1大于str2;如果返回值等于0,字符串str1等于字符串str2。
strncmp()与strcmp()函数一样,也用于对字符串进行比较操作,但最多比较前n个字符,原型如下:
#include <string.h>
int strncmp(const char *s1, const char *s2, size_t n);
函数参数和返回值含义如下:
- s1:参与比较的第一个字符串。
- s2:参与比较的第二个字符串。
- n:最多比较前n个字符。
- 返回值:返回值含义与strcmp()函数相同。
字符串查找
strchr()函数可以查找到给定字符串当中的某一个字符,函数原型如下所示:
#include <string.h>
char *strchr(const char *s, int c);
函数参数和返回值含义如下:
- s:给定的目标字符串。
- c:需要查找的字符。
- 返回值:返回字符c第一次在字符串s中出现的位置,如果未找到字符c,则返回NULL。
如果将参数c指定为’ \0 ',则函数将返回指向结束字符的指针。
strrchr()与strchr()函数一样,两者唯一不同的是,strrchr()函数在字符串中是从后到前(或者称为从右向左)查找字符,找到字符第一次出现的位置就返回,返回值指向这个位置,原型如下:
#include <string.h>
char *strrchr(const char *s, int c);
函数参数和返回值含义与strchr()函数相同。
strstr()可在给定的字符串haystack中查找第一次出现子字符串needle的位置,不包含结束字符’ \0 ',函数原型如下所示:
#include <string.h>
char *strstr(const char *haystack, const char *needle);
函数参数和返回值含义如下:
- haystack:目标字符串。
- needle:需要查找的子字符串。
- 返回值:如果目标字符串haystack中包含了子字符串needle,则返回该字符串首次出现的位置;如果未能找到子字符串needle,则返回NULL。
C函数库中还提供其它的字符串查找函数,譬如strpbrk()、index()以及rindex()等。
字符串与数字互转
字符串转整型数据
C函数库中提供了一系列函数用于实现将一个字符串转为整形数据,主要包括atoi()、atol()、atoll()以及strtol()、strtoll()、strtoul()、strtoull()等,它们之间的区别主要包括数据类型以及不同进制表示的数字字符串。
atoi()、atol()、atoll()三个函数可用于将字符串分别转换为int、long int以及long long类型的数据,函数原型如下:
#include <stdlib.h>
int atoi(const char *nptr);
long atol(const char *nptr);
long long atoll(const char *nptr);
函数参数和返回值含义如下:
- nptr:需要进行转换的字符串。
- 返回值:分别返回转换之后得到的int类型数据、long int类型数据以及long long类型数据。
目标字符串nptr中可以包含非数字字符,转换时跳过前面的空格字符直到遇上数字字符或正负符号才开始做转换,而再遇到非数字或字符串结束时(‘/0’)才结束转换,并将结果返回。只能转换十进制表示的数字字符串。
strtol()、strtoll()两个函数可分别将字符串转为long int类型数据和long long int类型数据,与之前的函数区别在于可以实现将多种不同进制数表示的字符串转为整型,原型如下:
#include <stdlib.h>
long int strtol(const char *nptr, char **endptr, int base);
long long int strtoll(const char *nptr, char **endptr, int base);
函数参数和返回值含义如下:
- nptr:需要进行转换的目标字符串。
- endptr:char **类型的指针,如果endptr不为NULL,则strtol()或strtoll()会将字符串中第一个无效字符的地址存储在endptr 中。如果根本没有数字,strtol()或strtoll()会将nptr的原始值存储在endptr 中(并返回0)。也可将参数endptr设置为NULL,表示不接收相应信息。
- base:数字基数,参数base必须介于2和36(包含)之间,或者是特殊值0。
- 返回值:分别返回转换之后得到的long int类型数据以及long long int类型数据。
base=0的情况下,如果字符串包含一了“0x”前缀,表示该数字将以16为基数;如果包含的是“0”前缀,表示该数字将以8为基数。
strtoul()、strtoull()函数与strtol()、strtoll()一样,区别在于返回值的类型不同,strtoul()返回值类型是unsigned long int,strtoull()返回值类型是unsigned long long int,函数原型如下所示:
#include <stdlib.h>
unsigned long int strtoul(const char *nptr, char **endptr, int base);
unsigned long long int strtoull(const char *nptr, char **endptr, int base);
函数参数与strtol()、strtoll()一样。
字符串转浮点型数据
atof()用于将字符串转换为一个double类型的浮点数据,函数原型如下所示:
#include <stdlib.h>
double atof(const char *nptr);
函数参数和返回值含义如下:
- nptr:需要进行转换的字符串。
- 返回值:返回转换得到的double类型数据。
strtof()、strtod()以及strtold()三个库函数可分别将字符串转换为float类型数据、double类型数据、long double类型数据,函数原型如下所示:
#include <stdlib.h>
double strtod(const char *nptr, char **endptr);
float strtof(const char *nptr, char **endptr);
long double strtold(const char *nptr, char **endptr);
函数参数与strtol()含义相同,但是少了base参数。
数字转字符串
推荐使用前面介绍的格式化IO相关库函数,譬如使用printf()将数字转字符串、并将其输出到标准输出设备或者使用sprintf()或snprintf()将数字转换为字符串并存储在缓冲区中。
给应用程序传参
一般的main函数中的写法是两个参数,int argc以及char argv**。传递进来的参数以字符串的形式存在,字符串的起始地址存储在argv数组中,参数argc表示传递进来的参数个数,包括应用程序自身路径名,多个不同的参数之间使用空格分隔开来,如果参数本身带有空格、则可以使用双引号" "或者单引号’ '的形式来表示。
正则表达式
给定一个字符串,检查该字符串是否符合某种条件或规则、或者从给定的字符串中找出符合某种条件或规则的子字符串,将匹配到的字符串提取出来。这就可以用到正则表达式。
正则表达式定义
正则表达式,又称为规则表达式(Regular Expression),正则表达式通常被用来检索、替换那些符合某个模式(规则)的字符串,正则表达式描述了一种字符串的匹配模(pattern),可以用来检查一个给定的字符串中是否含有某种子字符串、将匹配的字符串替换或者从某个字符串中取出符合某个条件的子字符串。
在Linux系统下运行命令的时候,使用?或*通配符来查找硬盘上的文件或者文本中的某个字符串,?通配符匹配0个或1个字符,而*通配符匹配0个或多个字符。
正则表达式其实也是一个字符串,该字符串由普通字符(譬如,数字0-9、大小写字母以及其它字符)和特殊字符(称为“元字符”)所组成,由这些字符组成一个“规则字符串”,这个“规则字符串”用来表达对给定字符串的一种查找、匹配逻辑。
C中使用正则表达式
这里就是根据实际需求,等到要使用的时候自己上网查询一下使用就可以了。
总结
这一篇笔记针对的是Linux的C应用编程的入门篇,主要是基础的一些应用程序概念、Linux下基础文件和目录的读写开关操作,以及标准IO库的函数学习,和最后的C中的字符串操作函数学习。

















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









