






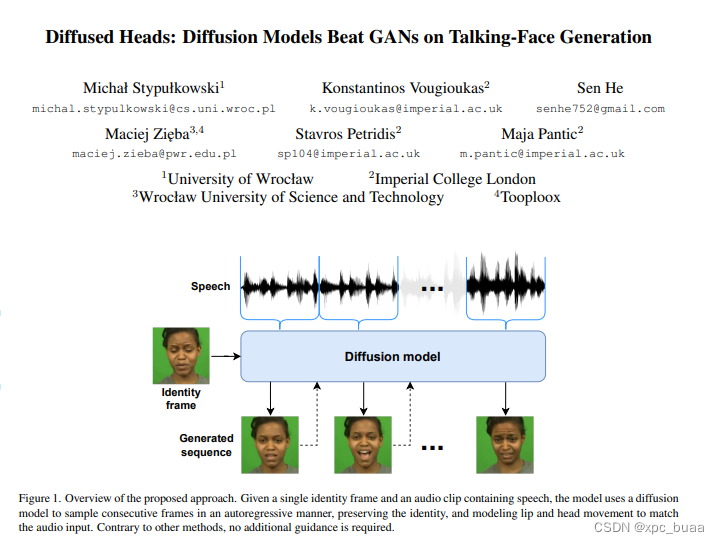
贡献
- 第一个在talking face generation上应用扩散模型
- 为了维持生成图像的连续性,引入了motion frames进行自回归的预测
- 有很好的泛化性
方法
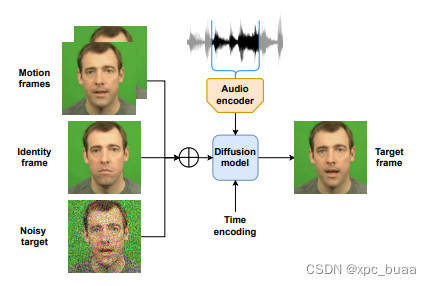
- diffusion model采用improved diffusion model
- 输入为Motion frames(t-2,t-1时刻图像),Identity frame随机选择的一帧,Noisy target当前时刻加噪图像
- Audio encoder选用的是梅尔普图特征+1层卷积(pretrain), audio condition类似 label embedding采用adaptive IN方式
- Lip sync loss,单独对嘴部区域约束
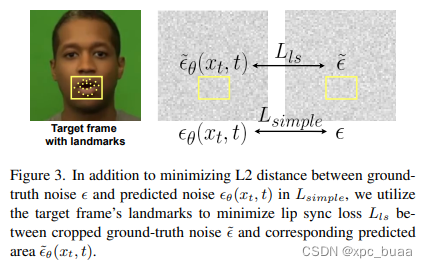
- 损失函数:improve diffusion的损失函数+lip sunc loss
- 采用DDIM加速采样,为了强制模型尽可能从身份帧中获取关于人物外貌的信息,把每个运动帧转换成黑白图像
实验
- 数据集
- CREMA
- LRW
- 实现细节
- 128*128分辨率
- UNet 256-512-768通道,只在middle block使用attention, 4head和64head channels
- 主观效果
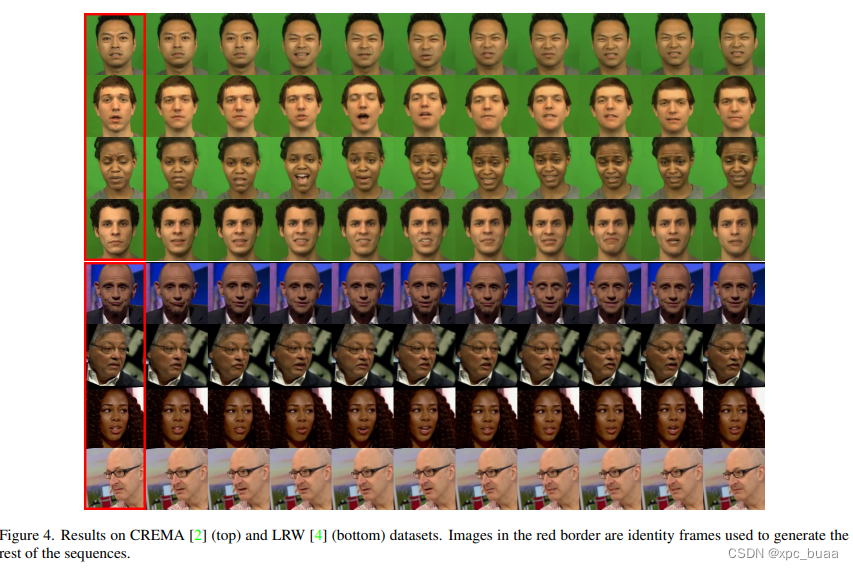
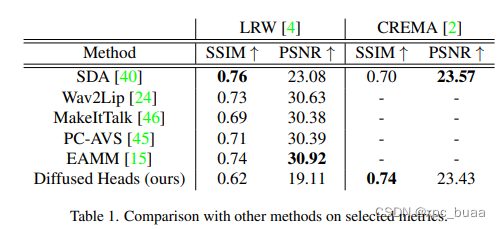
- 量化结果(
- Moreover, as explained in [20], PSNR favors blurry images and is not a perfect metric in our task,although used commonly.
- we do not provide anything but a single frame and audio, allowing the model to generate anything itwants. For that reason, our synthesized videos are not consistent with the reference ones and get worse measures inthe standard metrics
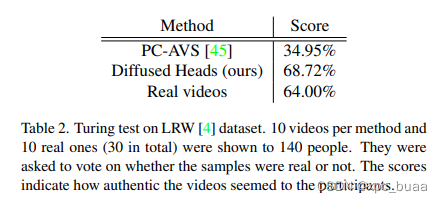
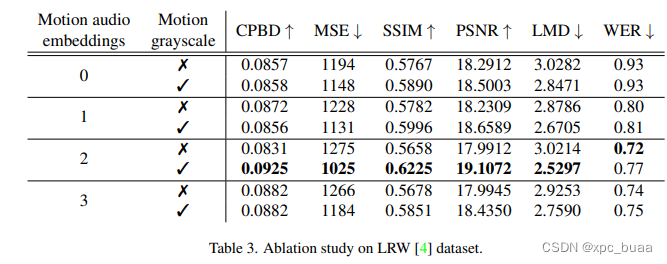
- 消融实验
- 泛化性证明
















 2018
2018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









