







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布 的需求,这种需求统称为将数据“无量纲化”。譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经 网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模 型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,对决策 树我们不需要无量纲化,决策树可以把任意数据都处理得很好。) 数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Meansubtraction)处理和缩放处理(Scale)。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到 某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理
数据介绍
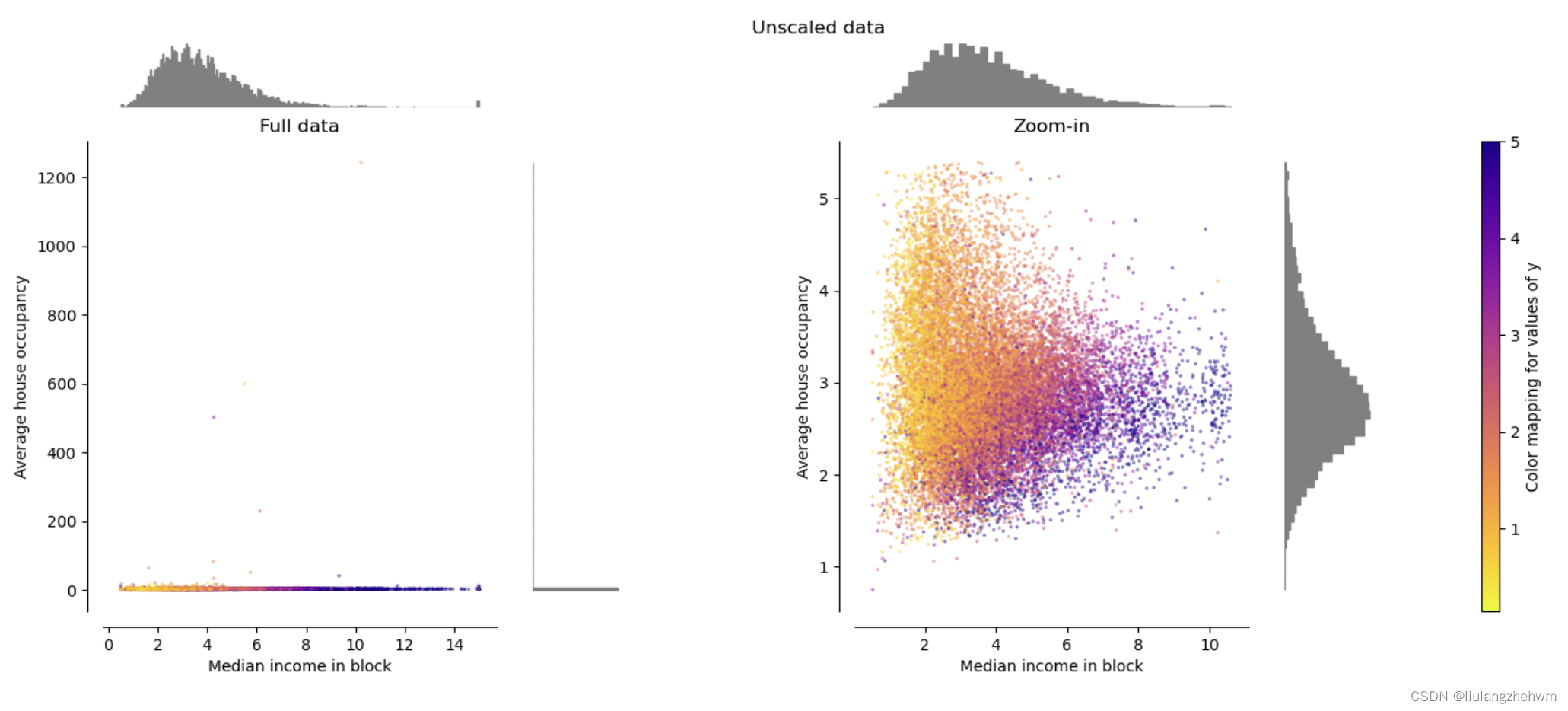
加州住房数据集的特征0(街区中的收入中位数)和特征5(平均住房入住率)具有非常不同的尺度,并且包含一些非常大的离群值。这两个特征导致数据难以可视化,更重要的是,它们会降低许多机器学习算法的预测性能。
原始数据显示和介绍
左侧图显示整个数据集(包含特征0和特征5),右侧放大以显示没有边缘离群值的数据集。绝大多数样本都被压缩到一个特定的范围,[0,10]是收入中位数,[0,6]是平均住房入住率。请注意,有一些边缘离群值(一些区块的平均入住率超过1200)。因此,根据应用,特定的预处理可能非常有益。在下文中,我们将介绍这些预处理方法在存在边缘离群值的情况下的一些见解和行为。
一、StandardScaler
1.1、详解
通过减掉均值并将数据缩放到单位方差来标准化特征,标准化完毕后的特征服从标准正态分布,即方差为1,均值为0。
1.1、缺点
然而,在计算经验平均值和标准差时,离群值会产生影响。特别要注意的是,由于每个特征上的异常值具有不同的幅度(量纲),因此每个特征上的转换数据的分布非常不同:对于转换后的中位数收入特征,大多数数据位于[-2,4]范围内,而对于转换后的平均住房入住率,相同的数据被挤压在较小的[-0.2,0.2]范围内。

二、MaxAbsScaler
2.1、详解
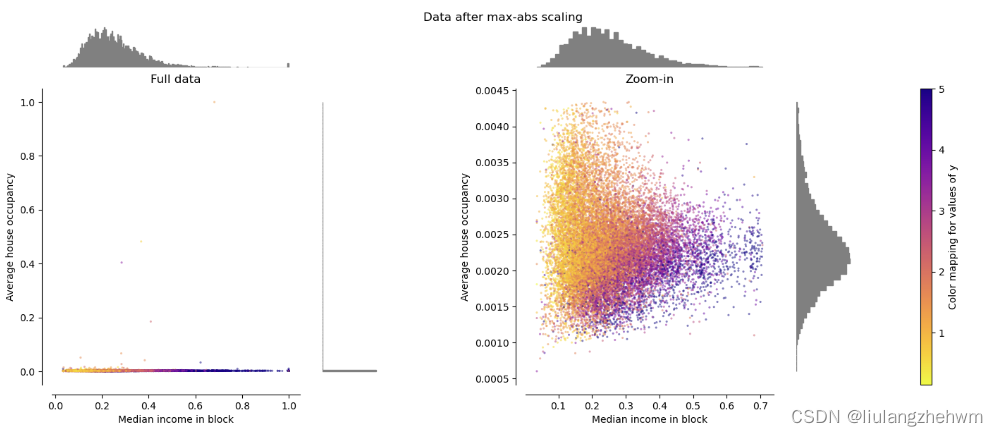
通过让每一个特征里的数据,除以该特征中绝对值最大的数值的绝对值,将数据压缩到[-1,1]之间 ,这种做法并没有中心化数据,因此不会破坏数据的稀疏性。数据的稀疏性是指,数据中包含0的比例,0越多,数据越稀疏。
2.2、缺点
MaxAbsScaler 类似于 MinMaxScaler ,不同之处在于,根据是否存在负值或正值,值被映射到多个范围。
- 如果只有正值,则范围为[0,1]。
- 如果只有负值,则范围为[-1,0]。
- 如果负值和正值都存在,则范围为[-1,1]。
仅在正数据上, MinMaxScaler 和 MaxAbsScaler 表现相似。 MaxAbsScaler 因此也遭受大离群值的存在。
三、RobustScaler
3.1、详解
使用可以处理异常值,对异常值不敏感的统计量来缩放数据。
这个缩放器减去中位数并根据百分位数范围(IRQ:Interquartile Range)缩放数据。IQR是第一分位数(25%)和第三分位数(75%)之间的范国。当异常值很多,噪音很大时,用中位数和四分位数范围通常会产生更好的效果。
3.1、缺点
与之前的缩放器不同, RobustScaler 的居中和缩放统计数据基于百分位数,因此不受少量非常大的边缘离群值的影响。因此,变换后的特征值的范围大于先前的缩放器,更重要的是,它们近似相似:对于这两个特征,大多数变换后的值位于[-2,3]范围内,如放大图所示。请注意,离群值本身仍然存在于转换后的数据中。如果需要单独的离群值裁剪,则需要非线性变换。
注意,离群值仍然会被进行转换。对单独的离群点裁剪,则需要进行非线性转换。

四、MinMaxScaler
4.1、详解
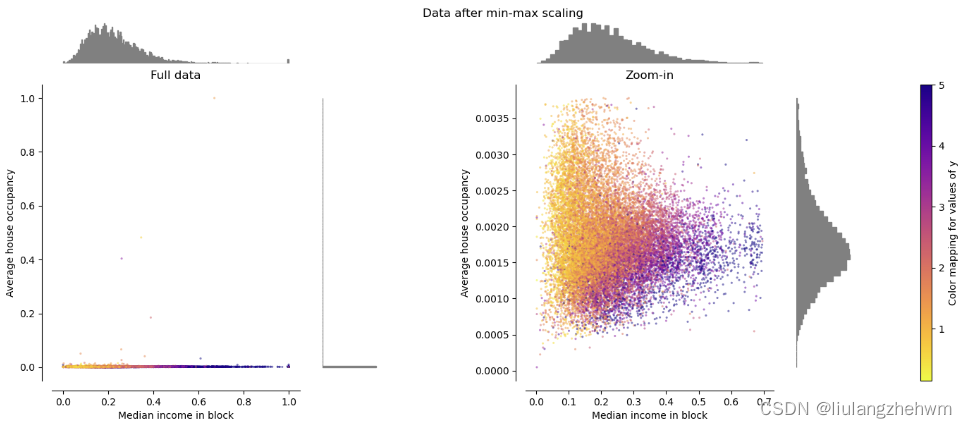
通过最大值最小值将每个特征缩放到给定范国,默认[0,1]
4.2、缺点
MinMaxScaler 重新缩放数据集,使所有特征值都在[0,1]范围内,如下面右侧面板所示。然而,这种缩放将所有内点压缩到转换后的平均房屋入住率的窄范围[0,0.005]中。
StandardScaler 和 MinMaxScaler 对离群值的存在非常敏感。
五、PowerTransformer
5.1、详解
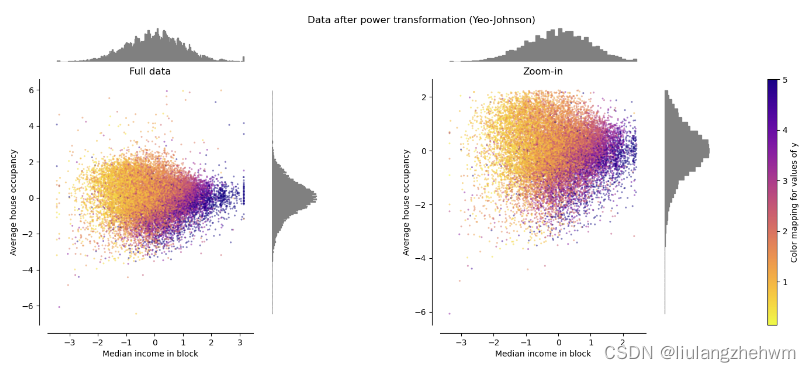
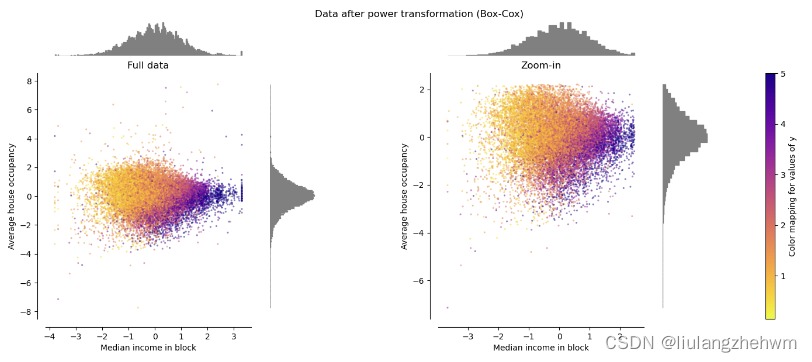
映射到高斯分布。在许多建模场景中,数据集中的特性是正常的。幂变换是一类参数的单调变换,其目的是将数据从任意分布映射到尽可能接近高斯分布,以稳定方差和最小化偏度。power_transform()通过最大似然估计来稳定方差,并确定最小化偏度的最佳参数。
偏度和峰度是描述数据分布特征的统计量,分别用于衡量数据的对称性和分布的集中趋势。
- 偏度(Skewness)描述了数据分布的不对称程度。当偏度大于0时,表示数据分布向右偏斜,即右侧的尾巴更长;当偏度小于0时,表示数据分布向左偏斜,即左侧的尾巴更长。偏度为0时,数据分布是对称的。12
- 峰度(Kurtosis)描述了数据分布的集中趋势,即数据分布的尖锐程度。峰度大于3表示数据分布比正态分布更尖锐,即有更厚的尾部;峰度小于3表示数据分布比正态分布更平坦。峰度为3时,表示数据分布与正态分布的尖锐程度相同。23
5.2、缺点
PowerTransformer 对每个特征应用幂变换,使数据更像高斯,以稳定方差并最小化偏度。目前支持Yeo-Johnson和Box-Cox变换,并且在这两种方法中通过最大似然估计来确定最佳缩放因子。默认情况下, PowerTransformer 应用零均值、单位方差归一化。请注意,Box-Cox仅适用于严格的正数据。收入和平均住房占用率恰好是严格的正值,但如果负值存在,则首选Yeo-Johnson转换。
六、QuantileTransformer (uniform output)
6.1、详解
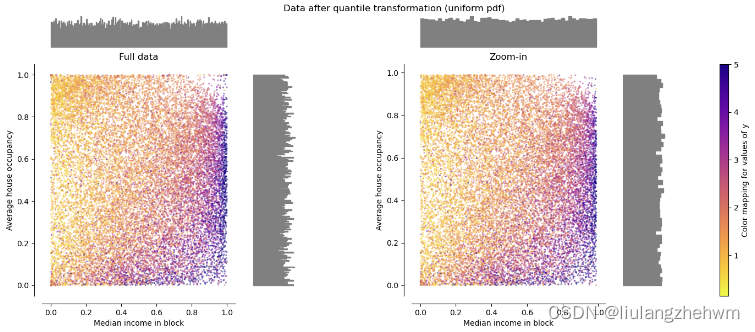
变换独立地应用于每个特征。首先,使用特征的累积分布函数的估计来将原始值映射到均匀分布。然后使用相关的分位数函数将获得的值映射到所需的输出分布。低于或高于拟合范围的新/未见过数据的特征值将映射到输出分布的边界。注意,该变换是非线性的。它可能会扭曲在同一尺度下测量的变量之间的线性相关性,但使在不同尺度下测量的变量更直接可比。
QuantileTransformer 应用非线性变换,使得每个特征的概率密度函数将被映射到均匀或高斯分布。在这种情况下,所有数据(包括离群值)将被映射到范围为[0,1]的均匀分布,从而使离群值与内点无法区分。
6.2、缺点
RobustScaler 和 QuantileTransformer 对离群值具有鲁棒性,因为在训练集中添加或删除离群值将产生大致相同的转换。但与 RobustScaler 相反, QuantileTransformer 也会通过将其设置为先验定义的范围边界(0和1)来自动折叠任何离群值(无法区分异常值,不同于RobustScaler,QuantileTransformer通过将异常值设为规定的范围值来达到消除异常值的目的。)。这可能导致极端值的饱和伪影。
七、QuantileTransformer(Gaussian output)
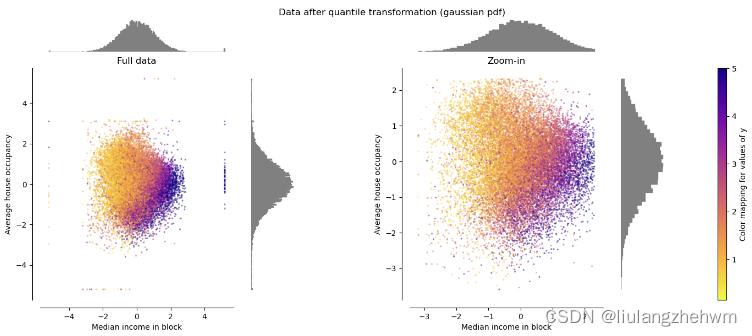
7.1、详解
使用百分位数转换特征,通过缩小边缘异常值和非异常值之间的距离来提供特征的非线性变换。可以使用参数
output distribution="normal’来将数据映射到标准正态分布。
八、Normalizer
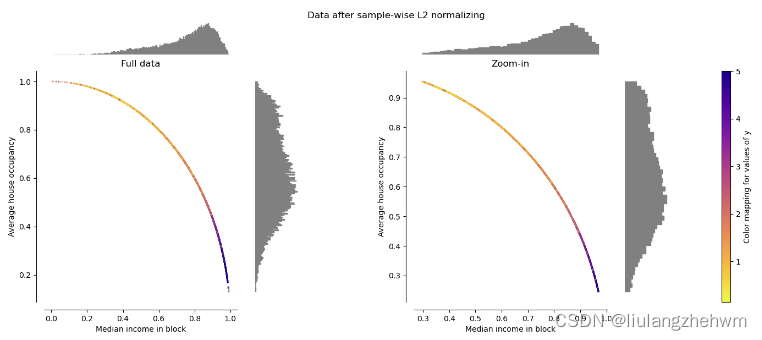
8.1、详解
Normalizer 重新缩放每个样本的向量,使其具有单位范数,与样本的分布无关。从下图可以看出,所有样本都映射到单位圆上。在我们的示例中,两个选定的特征只有正值;因此转换后的数据仅位于正象限。如果某些原始特征混合了正值和负值,情况就不是这样了。
- 优点:将每个样本向量的欧几里德长度缩放为1,适用于计算样本之间的相似性。
- 缺点:只对每个样本的特征进行缩放,不保留原始数据的分布形状。
- 公式:对于每个样本,公式为:x / ||x||,其中x是样本向量,||x||是x的欧几里德范数。
目的:经常在文本分类和内容聚类中使用
九、代码
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# 不太熟悉numpy的小伙伴,能够判断data的结构吗?
# 如果换成表是什么样子?
import pandas as pd
pd.DataFrame(data)
# 实现归一化
scaler = MinMaxScaler() # 实例化
scaler = scaler.fit(data) # fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) # 通过接口导出结果
result_ = scaler.fit_transform(data) # 训练和导出结果一步达成
scaler.inverse_transform(result) # 将归一化后的结果逆转
# 使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5, 10]) # 依然实例化
总结

参考文献:
1,https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html#sphx-glr-auto-examples-preprocessing-plot-all-scaling-py
2,https://www.bilibili.com/video/BV1vJ41187hk/
3,https://blog.csdn.net/qq_24831889/article/details/83344638
4,https://blog.csdn.net/qq_42658739/article/details/136574905
5,https://zhuanlan.zhihu.com/p/478699147















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









