







Pytorch1.1版本已经提供了相对稳定的c++接口,网上也有了众多的资料供大家参考,进行c++的接口的初步尝试。
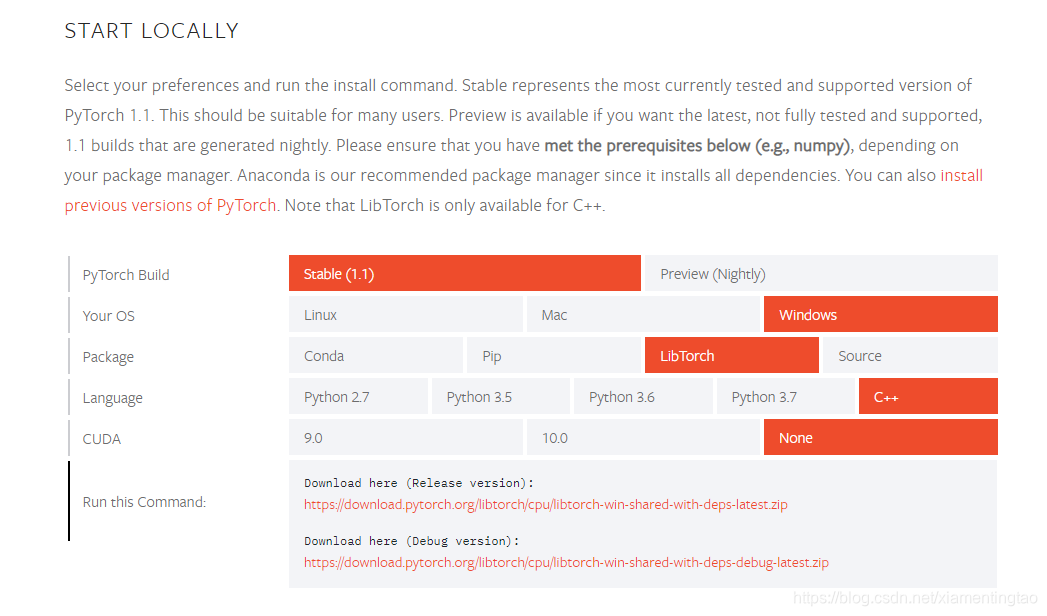
可以按照对应的选项下载,下面我们要说的是:
如何利用已经编译好的官方libtorch库和其他的opencv库等联合编写应用?
其实很简单,大概的步骤有三步:
第一步:在python环境下将模型导出为jit的模型
第二步:编写对应的c++ inference 程序。
第三步:直接在VS上(已经成功实验VS2015,高版本的应该也可以)配置相应的libtorch环境,主要是:
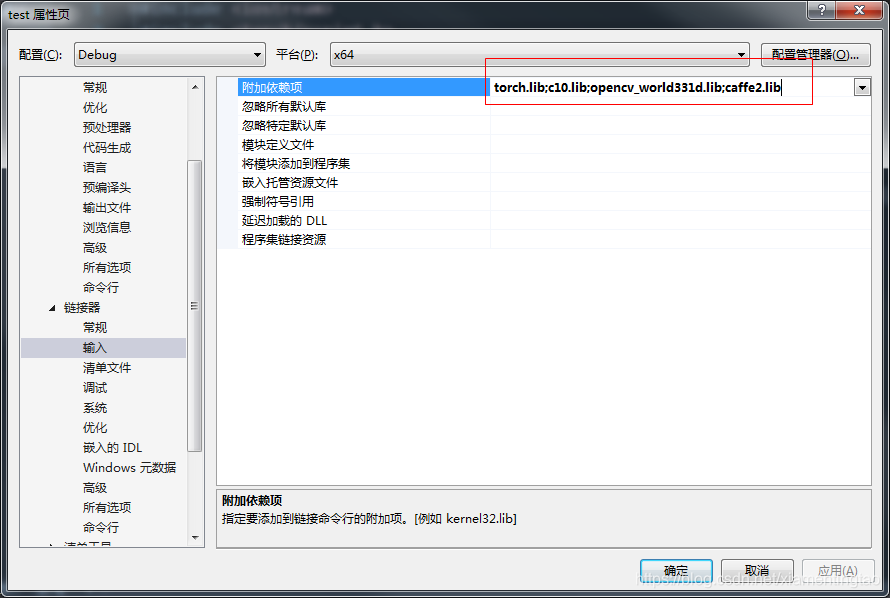
dll路径:
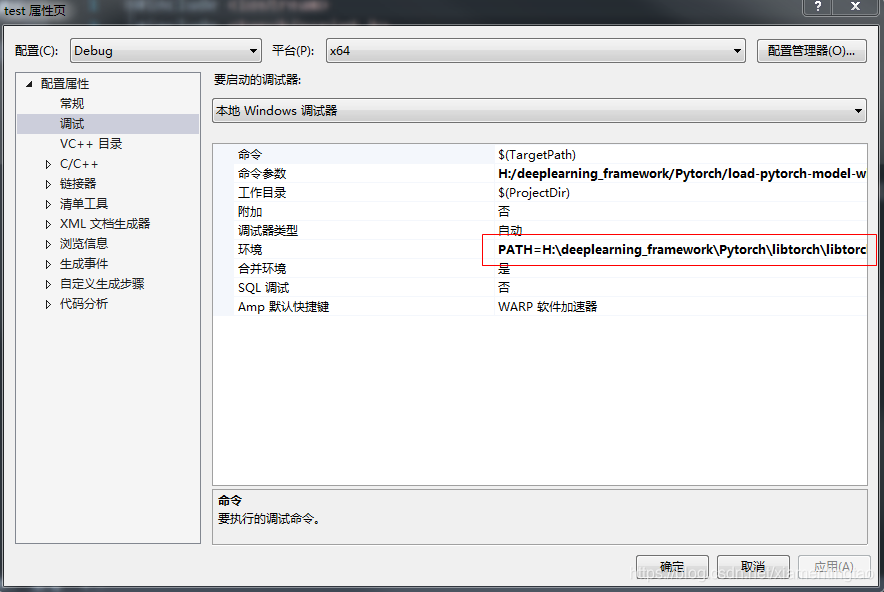
PATH=H:\deeplearning_framework\Pytorch\libtorch\libtorch-win-shared-with-deps-debug-latest_cpu\libtorch\lib%3bD:\opencv\build\x64\vc14\bin%3b$(PATH) 相应地去修改即可,不需要在PC的path环境下加入libtorch的路径,而是在这里加更加简单。
include路径:
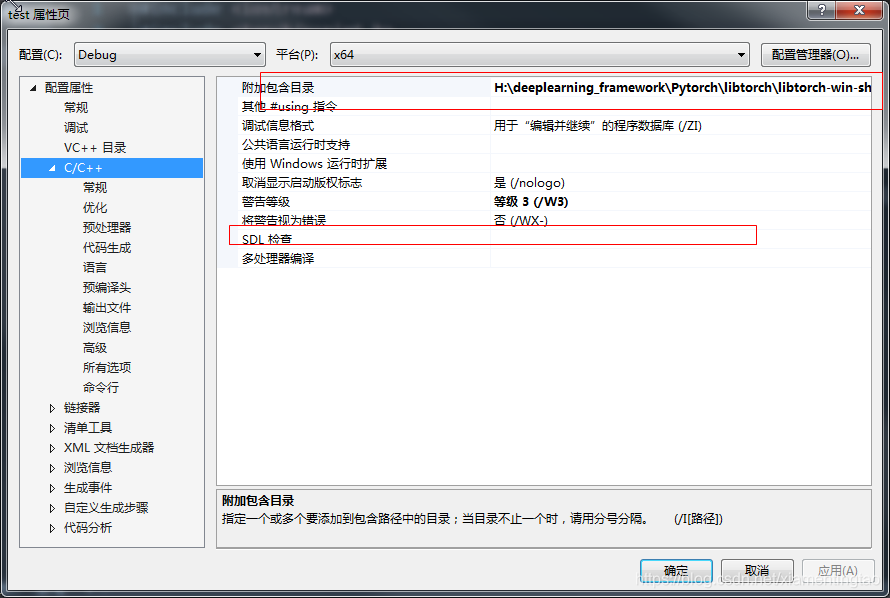
H:\deeplearning_framework\Pytorch\libtorch\libtorch-win-shared-with-deps-debug-latest_cpu\libtorch\include\torch\csrc\api\include;H:\deeplearning_framework\Pytorch\libtorch\libtorch-win-shared-with-deps-debug-latest_cpu\libtorch\include;D:\opencv\build\include\opencv2;D:\opencv\build\include\opencv;D:\opencv\build\include;%(AdditionalIncludeDirectories)
主要是加粗线那两个。
注意一定要去掉SDL的检查项,否则会出现错误警告。
lib路径:
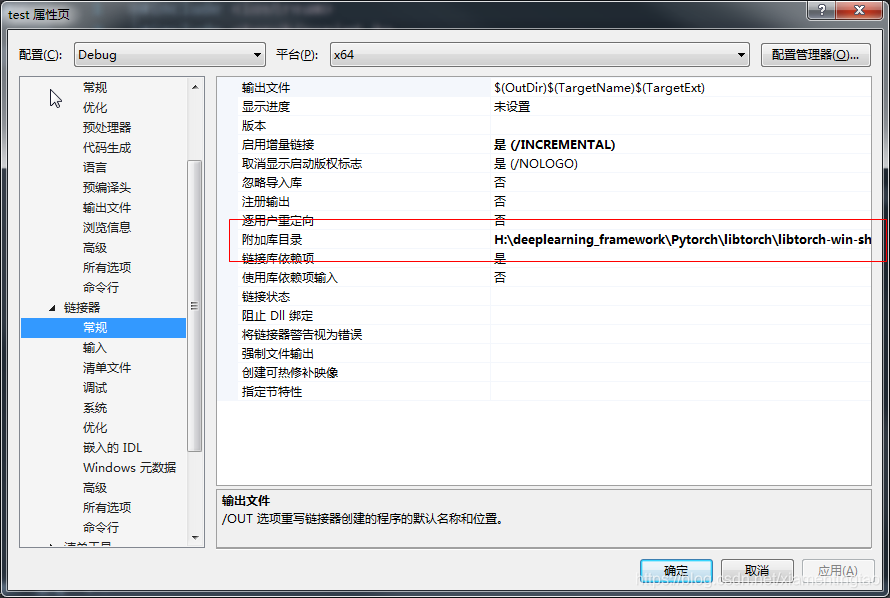
H:\deeplearning_framework\Pytorch\libtorch\libtorch-win-shared-with-deps-debug-latest_cpu\libtorch\lib;D:\opencv\build\x64\vc14\lib;%(AdditionalLibraryDirectories)
详细的工程见:https://download.csdn.net/download/xiamentingtao/11486608
这里我们主要改编自:《Win10+VS2017+PyTorch(libtorch) C++ 基本应用》
主要代码参考: https://github.com/zhpmatrix/load-pytorch-model-with-c-
一些 常见的问题:
1. opencv的mat读入libtorch
根据我的实践,这里的最佳写法是:
src = imread(s, cv::IMREAD_COLOR); //读图
// 图像预处理 注意需要和python训练时的预处理一致
int org_w = src.cols;
int org_h = src.rows;
torch::Tensor img_tensor = torch::from_blob(src.data, { org_h, org_w,3 }, torch::kByte); //将cv::Mat转成tensor,大小为448,448,3
img_tensor = img_tensor.permute({ 2, 0, 1 }); //调换顺序变为torch输入的格式 3,448,448
img_tensor = img_tensor.toType(torch::kFloat32).div_(255);注意要先将uint8的图像先读入,再转换成float型。
2. Tensor 转换成cv::Mat
cv::Mat input(img_tensor.size(1), img_tensor.size(2), CV_32FC1, img_tensor.data<float>());注意这里一定是CV_32FC1而不是CV_32FC3
另外的方式见:https://discuss.pytorch.org/t/convert-torch-tensor-to-cv-mat/42751/2
torch::Tensor out_tensor = module->forward(inputs).toTensor();
assert(out_tensor.device().type() == torch::kCUDA);
out_tensor=out_tensor.squeeze().detach().permute({1,2,0});
out_tensor=out_tensor.mul(255).clamp(0,255).to(torch::kU8);
out_tensor=out_tensor.to(torch::kCPU);
cv::Mat resultImg(512, 512,CV_8UC3);
std::memcpy((void*)resultImg.data,out_tensor.data_ptr(),sizeof(torch::kU8)*out_tensor.numel());3. model的输出处理
如果只有一个返回值,可以直接转tensor:
auto outputs = module->forward(inputs).toTensor();
如果有多个返回值,需要先转tuple:
auto outputs = module->forward(inputs).toTuple();
torch::Tensor out1 = outputs->elements()[0].toTensor();
torch::Tensor out2 = outputs->elements()[1].toTensor();
4.Tracing fails because of “parameter sharing”?
看这个案例:https://discuss.pytorch.org/t/help-tracing-fails-because-of-parameter-sharing/40324
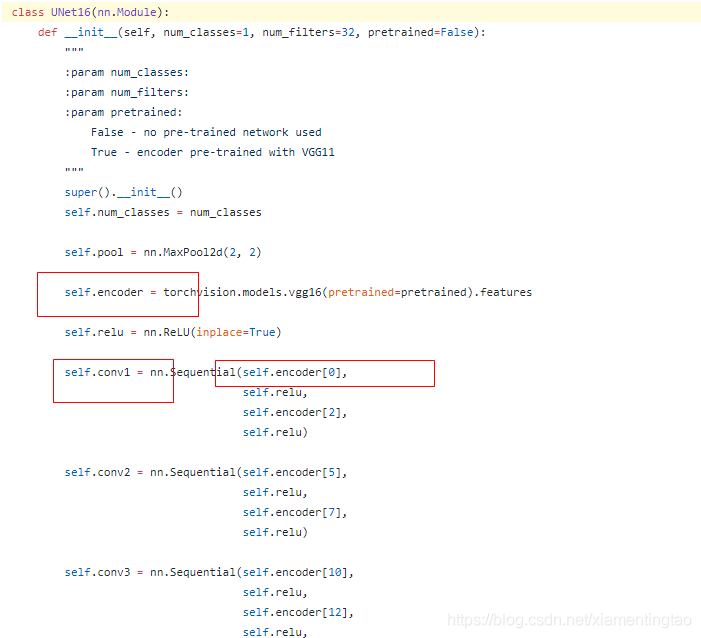
其中的部分代码如上,问题就出现在这些画框的地方,主要是这里初始化重复使用了相同的模块进行赋值,例如self.encoder与self.conv1。
解决的办法就是在构造slef.conv1时,对self.encoder[0]加入deepcopy修饰。
即:
from copy import deepcopy
self.conv1 = nn.Sequential(deepcopy(self.encoder[0]),
deepcopy(self.relu),
deepcopy(self.encoder[2]),
deepcopy(self.relu))参考:https://github.com/pytorch/pytorch/issues/8392#issuecomment-431863763
5. 关于python导出模型的问题
如果训练的pytorch模型保存在cpu上,想在测试时使用gpu模式,则我们需要设置python端保存模型在gpu上,然后才能c++上使用gpu测试。
主要的方法就是:
checkpoint = torch.load(model_path, map_location="cuda:0") #very important
# create model
model = TheModelClass(*args, **kwargs)
model.load_state_dict(checkpoint)
model.to(device)
model.eval()
x = torch.rand(1, 3, 448, 448)
x = x.to(device) # very important
traced_script_module = torch.jit.trace(model.model, x)
traced_script_module.save("**.pt")
然后才能在c++上使用gpu模式,方法为:
std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(argv[1]);
module->to(at::kCUDA);
assert(module != nullptr);
std::cout << "ok\n";
// 建立一个输入,维度为(1,3,224,224),并移动至cuda
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::ones({1, 3, 224, 224}).to(at::kCUDA));
// Execute the model and turn its output into a tensor.
at::Tensor output = module->forward(inputs).toTensor();
参考:
pytorch跨设备保存和加载模型(变量类型(cpu/gpu)不匹配原因之一)
https://pytorch.org/tutorials/beginner/saving_loading_models.html
https://blog.csdn.net/IAMoldpan/article/details/85057238
参考文献:
1.利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
2.Pytorch的C++端(libtorch)在Windows中的使用
3. https://pytorch.org/tutorials/advanced/cpp_frontend.html
4. https://zhpmatrix.github.io/2019/03/01/c++-with-pytorch/
6. 用cmake构建基于qt5,opencv,libtorch项目
7. c++调用pytorch模型并使用GPU进行预测 (较好的例子)














 3088
3088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









