






大家好,我是独孤风。在当今数据驱动的商业环境中,数据治理成为企业成功的关键因素之一,而数据血缘正是数据治理成功的一个关键。
进行数据血缘的分析一定要注重全链路方式的构建,针对数据的全生命周期,主要包括血缘采集层、血缘处理层、血缘存储层、血缘接口层、血缘应用层这5个层次。
本文为《数据血缘分析原理与实践 》一书读书笔记,部分观点参考自书中原文,如需更详细的了解学习,请大家支持原作者的辛苦付出。
本文思维导图如下所示:
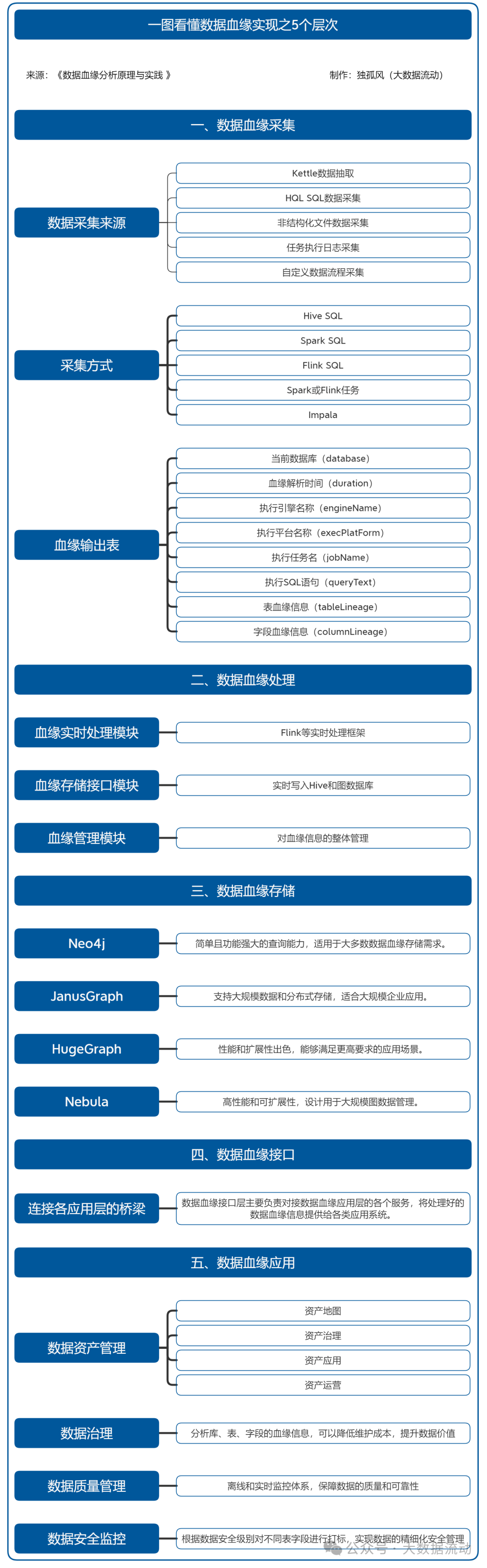
随着数据驱动业务的重要性日益凸显,数据治理逐渐成为企业实现数据价值最大化的核心策略之一。而在数据治理的众多环节中,数据血缘分析无疑是至关重要的一环。数据血缘通过追溯数据的来源、传输和变更路径,为数据的质量控制、安全管理和价值提升提供了坚实的基础。本文将结合数据血缘的全生命周期管理,详细探讨数据血缘采集、处理、存储、接口和应用五个层次的构建方法和实际应用。
一、数据血缘采集:多渠道的数据源整合
数据血缘采集层是数据治理的起点,通过多种渠道收集和整合数据源信息,以便后续处理。主要的数据采集来源包括:Kettle数据抽取、HQL SQL数据采集、非结构化文件数据采集、任务执行日志采集和自定义数据流程采集。这些采集方式分别适用于不同类型和格式的数据,使得数据血缘信息的覆盖范围更加广泛。
具体的采集方式如Hive SQL、Spark SQL、Flink SQL、Spark或Flink任务以及Impala等,能够满足企业在不同场景下的需求。采集到的数据血缘信息通常存储在血缘输出表中,包含字段如当前数据库(database)、血缘解析时间(duration)、执行引擎名称(engineName)、执行平台名称(execPlatForm)、执行任务名(jobName)、执行SQL语句(queryText)、表血缘信息(tableLineage)和字段血缘信息(columnLineage)。这些数据字段为后续的血缘分析和处理提供了详实的基础数据。
| 字段 | 描述 | 字段类型 | 示例 |
|---|---|---|---|
| database | 当前数据库 | String | default |
| duration | 血缘解析时间 | Integer | 123 |
| engineName | 执行引擎名称 | String | Hive |
| execPlatForm | 执行平台名称 | String | Hadoop |
| jobName | 执行的任务名 | String | data_import |
| queryText | 执行SQL语句 | String | SELECT * FROM table |
| tableLineage | 表血缘信息 | String | table1 -> table2 |
| columnLineage | 字段血缘信息 | String | column1 -> column2 |
二、数据血缘处理:实时与批处理的高效结合
在数据血缘的处理层,主要由血缘实时处理模块、血缘存储接口模块和血缘管理模块组成。通过Flink等实时处理框架,可以将采集到的数据血缘信息实时写入Hive和图数据库中,实现数据的高效处理和及时更新。这种实时与批处理相结合的方式,不仅提升了数据处理的效率,还确保了数据的实时性和准确性。
血缘管理模块则负责对血缘信息的整体管理,包括数据的调度、监控和异常处理等功能。通过构建完善的血缘处理体系,企业能够更好地应对复杂的数据治理需求,提升数据处理的整体水平。
三、数据血缘存储:图数据库的优势与应用
数据血缘信息的存储是确保数据可追溯性和高效查询的关键环节。虽然MySQL等关系型数据库也可以用于存储数据血缘信息,但图数据库如Neo4j、JanusGraph、HugeGraph和Nebula由于其在处理复杂关系和快速查询方面的优势,逐渐成为主流选择。
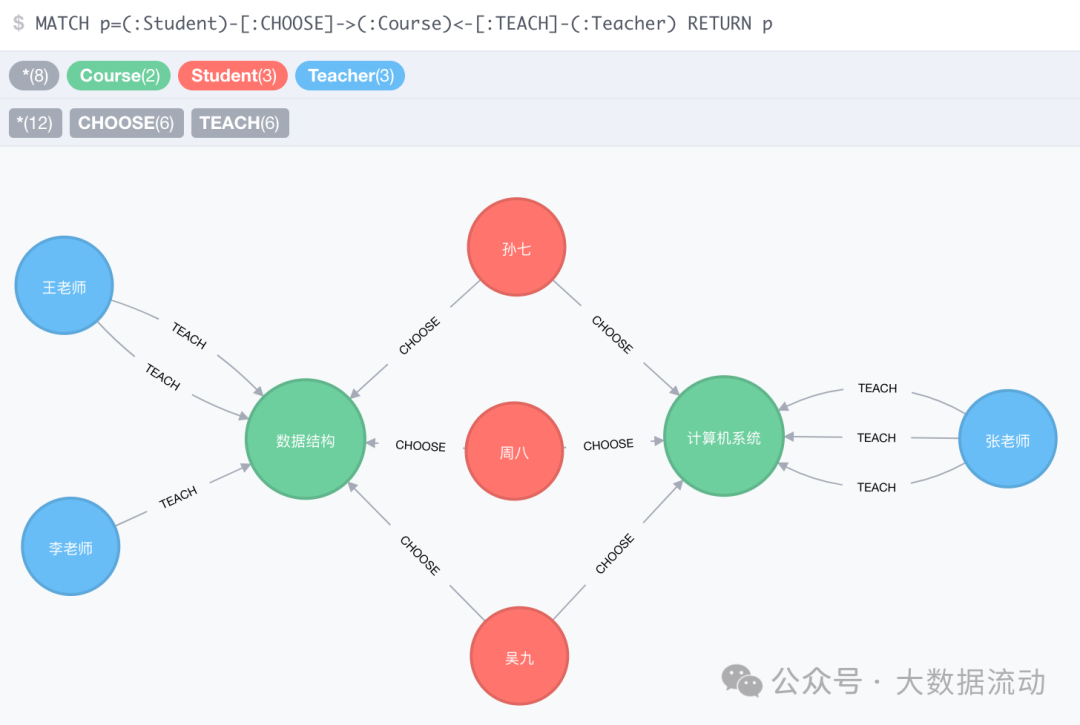
这些图数据库各自具有不同的特点,Neo4j以其简单易用和强大的查询功能著称,适用于大多数数据血缘存储需求;JanusGraph则支持大规模数据和分布式存储,适合大规模企业应用;HugeGraph和Nebula则在性能和扩展性上有着出色的表现,能够满足更高要求的应用场景。通过选择合适的图数据库,企业可以实现数据血缘信息的高效存储和管理。
| 图数据库 | 特点 | 优势 | 劣势 | 使用场景 |
|---|---|---|---|---|
| Neo4j | 简单且功能强大的查询能力,适用于大多数数据血缘存储需求。 | 用户友好,使用Cypher进行强大的查询。 | 对大规模数据处理时可能性能不足。 | 数据血缘存储和查询。 |
| JanusGraph | 支持大规模数据和分布式存储,适合大规模企业应用。 | 高度可扩展,支持多种后端(HBase, Cassandra等)。 | 配置和管理复杂度较高。 | 企业级大数据应用。 |
| HugeGraph | 性能和扩展性出色,能够满足更高要求的应用场景。 | 针对大规模图进行了优化,易于横向扩展。 | 社区和生态系统相对较小。 | 高性能图计算和分析。 |
| Nebula | 高性能和可扩展性,设计用于大规模图数据管理。 | 高效的存储和查询性能,强大的分布式部署支持。 | 学习曲线较陡峭,社区支持有限。 | 分布式大规模图数据管理。 |
四、数据血缘接口:连接各应用层的桥梁
数据血缘接口层主要负责对接数据血缘应用层的各个服务,将处理好的数据血缘信息提供给各类应用系统。通过构建灵活、高效的接口层,企业能够实现数据血缘信息在不同系统间的无缝对接,提升整体数据治理能力。
接口层的构建需要考虑不同应用系统的需求和特点,采用RESTful API等标准化接口方式,可以确保数据血缘信息的高效传输和应用。此外,通过建立完善的接口管理和监控机制,可以有效保障数据血缘信息的准确性和实时性,为数据应用提供坚实的支持。
五、数据血缘应用:多维度的数据治理与价值提升
数据血缘的最终目的是实现数据的高效治理和价值提升。在数据血缘应用层,主要包括数据资产管理、数据治理、数据质量管理和数据安全监控等方面。数据资产管理平台通过提供资产地图、资产治理、资产应用和资产运营等功能,实现对企业数据资产的全面管理和高效利用。
数据治理方面,通过分析库、表、字段的血缘信息,可以降低维护成本,提升数据价值。数据质量管理平台则通过离线和实时监控体系,保障数据的质量和可靠性。基于数据血缘的实时告警机制,可以在数据出现异常时及时通知相关负责人,确保数据的持续健康。
在数据安全监控方面,通过对数据血缘信息的分析,可以根据数据安全级别对不同表字段进行打标,实现数据的精细化安全管理,保障企业数据的安全性和合规性。
通过对数据血缘的全生命周期管理,从数据采集、处理、存储、接口到应用的全方位解读,企业可以更好地实现数据治理的目标,提升数据价值,确保数据安全,为业务发展提供强有力的支持。
下一章,我们进入到数据血缘的落地实现部分,先来探讨数据血缘实施的难点。
下一章再见!


















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











