






import pandas as pd
import numpy as np
a=pd.DataFrame(np.arange(12).reshape(3,4))
b=pd.DataFrame(np.arange(20).reshape(4,5))
print(a)
print(b)
c=b.add(a,fill_value=100) #空缺的位置加100代替
print(c)
d=a.mul(b,fill_value=0) #空缺的位置用0代替
print(d)
outer:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
0 1 2 3 4
0 0.0 2.0 4.0 6.0 104.0
1 9.0 11.0 13.0 15.0 109.0
2 18.0 20.0 22.0 24.0 114.0
3 115.0 116.0 117.0 118.0 119.0
0 1 2 3 4
0 0.0 1.0 4.0 9.0 0.0
1 20.0 30.0 42.0 56.0 0.0
2 80.0 99.0 120.0 143.0 0.0
3 0.0 0.0 0.0 0.0 0.0
Process finished with exit code 0
二维和一维、一维和零维间为广播运算
默认Seriers参与DataFrame的行运算
将Series的索引匹配到DataFrame的行,然后行一直向下传播,缺失元素Nan补全。
import pandas as pd
import numpy as np
s1=pd.Series(np.arange(4))
s2=pd.Series(np.arange(5))
d=pd.DataFrame(np.arange(12).reshape(3,4))
print(s1)
print(d)
print(d-s1)
print(d-s2)
print(d>s1)
outer:
0 0
1 1
2 2
3 3
dtype: int32
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3
0 0 0 0 0
1 4 4 4 4
2 8 8 8 8
0 1 2 3 4
0 0 0 0 0 NaN
1 4 4 4 4 NaN
2 8 8 8 8 NaN
0 1 2 3
0 False False False False
1 True True True True
2 True True True True
Process finished with exit code 0
Pandas排序操作
按索引排序
.sort_index(axis=0, ascending=True)
import pandas as pd
import numpy as np
a=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(a)
c=a.sort_index() #默认0轴升序排列
print(c)
d=c.sort_index(axis=1,ascending=False) #改为1轴降序
print(d)
outer:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
a 5 6 7 8 9
b 15 16 17 18 19
c 0 1 2 3 4
d 10 11 12 13 14
4 3 2 1 0
a 9 8 7 6 5
b 19 18 17 16 15
c 4 3 2 1 0
d 14 13 12 11 10
Process finished with exit code 0
按列值排序
DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False)
import pandas as pd
a = [[9, 3, 1], [1, 2, 8], [1, 0, 5]]
b=pd.DataFrame(a,index=["0", "2", "1"], columns=["c", "a", "b"])
print(b)
print(b.sort_values(by='c')) #ascending默认为True,即升序排列
print(b.sort_values(by=['c','a']))
print(b.sort_values(by="0",axis=1,ascending=False)) #按0行排序,降序排列
outer:
c a b
0 9 3 1
2 1 2 8
1 1 0 5
c a b
2 1 2 8
1 1 0 5
0 9 3 1
c a b
1 1 0 5
2 1 2 8
0 9 3 1
c a b
0 9 3 1
2 1 2 8
1 1 0 5
Process finished with exit code 0
3.按索引和列值排序
汇总和计算描述统计
import pandas as pd
import numpy as np
a=pd.Series(np.arange(5))
b=pd.DataFrame(np.arange(12).reshape(3,4))
c=b-a
print(c)
print(c.count()) #计算NaN的数量
print(c.describe()) #针对列进行汇总统计
print(b.max()) #每列的最大值
print(b.idxmax()) #最大值的索引值(列索引+行索引)
print(c.sum()) #默认按列求和, c.sum(axis=1)表示按行求和
print(c.mean()) #默认按列求均值, c.mean(axis=1)表示按行求均值
print(c.median()) #默认按列求中位数, c.median(axis=1)表示按行求中位数
print(c.var()) #默认按列求方差, c.var(axis=1)表示按行求方差
print(c.std()) #默认按列求标准差, c.std(axis=1)表示按行求标准差
print(c.cumsum(axis=1)) #样本累计求和,默认是列
print(c.cummin()) #样本值的累计最大值
print(c.cummax()) #累计最小值
print(a.cumprod()) #样本累积求积,默认是列
outer:
0 1 2 3 4
0 0 0 0 0 NaN
1 4 4 4 4 NaN
2 8 8 8 8 NaN
0 3
1 3
2 3
3 3
4 0
dtype: int64
0 1 2 3 4
count 3.0 3.0 3.0 3.0 0.0
mean 4.0 4.0 4.0 4.0 NaN
std 4.0 4.0 4.0 4.0 NaN
min 0.0 0.0 0.0 0.0 NaN
25% 2.0 2.0 2.0 2.0 NaN
50% 4.0 4.0 4.0 4.0 NaN
75% 6.0 6.0 6.0 6.0 NaN
max 8.0 8.0 8.0 8.0 NaN
0 8
1 9
2 10
3 11
dtype: int32
0 2
1 2
2 2
3 2
dtype: int64
0 12.0
1 12.0
2 12.0
3 12.0
4 0.0
dtype: float64
0 4.0
1 4.0
2 4.0
3 4.0
4 NaN
dtype: float64
0 4.0
1 4.0
2 4.0
3 4.0
4 NaN
dtype: float64
0 16.0
1 16.0
2 16.0
3 16.0
4 NaN
dtype: float64
0 4.0
1 4.0
2 4.0
3 4.0
4 NaN
dtype: float64
0 1 2 3 4
0 0.0 0.0 0.0 0.0 NaN
1 4.0 8.0 12.0 16.0 NaN
2 8.0 16.0 24.0 32.0 NaN
0 1 2 3 4
0 0 0 0 0 NaN
1 0 0 0 0 NaN
2 0 0 0 0 NaN
0 1 2 3 4
0 0 0 0 0 NaN
1 4 4 4 4 NaN
2 8 8 8 8 NaN
0 0
1 0
2 0
3 0
4 0
dtype: int32
Process finished with exit code 0
累计统计分析函数
import pandas as pd
import numpy as np
a=pd.DataFrame(np.arange(12).reshape(3,4))
print(a)
print(a.rolling(2).sum()) #依次计算相邻2个元素的值,默认相邻行之间(此行与上一行)
print(a.rolling(2).mean())
print(a.rolling(2).var())
print(a.rolling(2).std())
print(a.rolling(2).max())
outer:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3
0 NaN NaN NaN NaN
1 4.0 6.0 8.0 10.0
2 12.0 14.0 16.0 18.0
0 1 2 3
0 NaN NaN NaN NaN
1 2.0 3.0 4.0 5.0
2 6.0 7.0 8.0 9.0
0 1 2 3
0 NaN NaN NaN NaN
1 8.0 8.0 8.0 8.0
2 8.0 8.0 8.0 8.0
0 1 2 3
0 NaN NaN NaN NaN
1 2.828427 2.828427 2.828427 2.828427
2 2.828427 2.828427 2.828427 2.828427
0 1 2 3
0 NaN NaN NaN NaN
1 4.0 5.0 6.0 7.0
2 8.0 9.0 10.0 11.0
Process finished with exit code 0
唯一值、值计数
import pandas as pd
a=pd.Series(['c','a','d','a','a','b','b','c','c'])
print(a.unique()) #保留唯一值
print(a.value_counts()) #统计值出现的次数,降序排序
outer:
['c' 'a' 'd' 'b']
c 3
a 3
b 2
d 1
dtype: int64
成员资格
import pandas as pd
df=pd.DataFrame({'num_legs': [2, 4],'num_wings': [2, 0]},index=['falcon', 'dog'])
other = pd.DataFrame({'num_legs': [8, 2], 'num_wings': [0, 2]},index=['spider', 'falcon'])
print(df)
print(df.isin([0,2])) #来查看参数values是否在Series/Data Frame内,有返回按DataFrame分布布尔值True,否则False。
print(df.isin({'num_wings': [0, 3]}))
print(df.isin(other))
outer:
num_legs num_wings
falcon 2 2
dog 4 0
num_legs num_wings
falcon True True
dog False True
num_legs num_wings
falcon False False
dog False True
num_legs num_wings
falcon True True
dog False False
Process finished with exit code 0
函数映射
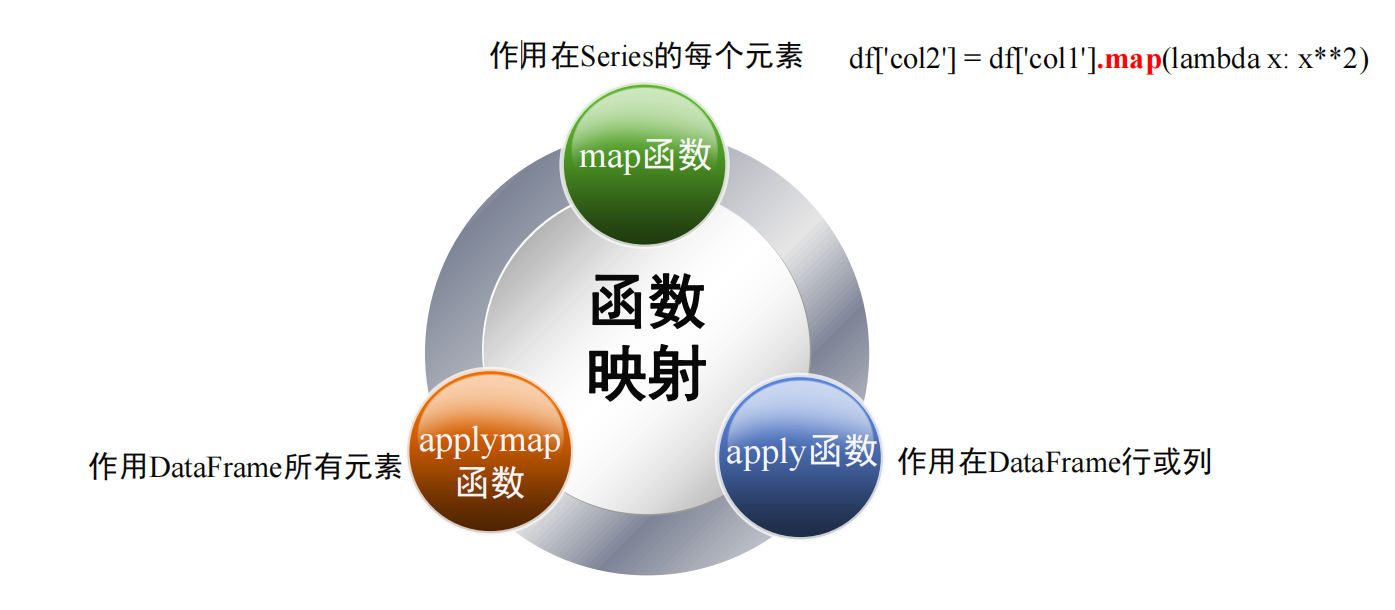
apply函数-对行、列用函数处理
apply函数是pandas里面所有函数中自由度最高的函数
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
◆func : 函数,应用于每个列或行的函数;
◆axis:=0或1将函数应用于每一列或行;
◆raw:默认将每个行或列作为系列传递给函数,否则传递的函数将改为接收
ndarray对象;
◆result_type : {‘expand’,‘reduce’,‘broadcast’,None},默认为None。仅在
axis=1情况下起作用,‘expand’:类似列表的结果将变成列,'reduce':如果可
能,返回一个Series。' broadcast ':结果将广播到DataFrame的原始形状。
import pandas as pd
import numpy as np
name=['王大','李二','刘三']
idx=['tar1','tar2','tar3','tar3']
df=pd.DataFrame(np.random.randint(60,100,12).reshape(3,4),index=name,columns=idx)
df_apply=df.apply(lambda x:((x-min(x))/(max(x)-min(x))),axis=1) #归一化处理(按行进行)
print(df)
print(df_apply)
outer:
tar1 tar2 tar3 tar3
王大 78 98 82 73
李二 68 65 62 94
刘三 72 63 98 96
tar1 tar2 tar3 tar3
王大 0.200000 1.00000 0.36 0.000000
李二 0.187500 0.09375 0.00 1.000000
刘三 0.257143 0.00000 1.00 0.942857
Process finished with exit code 0
import pandas as pd
import numpy as np
df=pd.DataFrame([[4,9]]*3,columns=['A','B'])
print(df)
df_sqrt=df.apply(np.sqrt)
print(df_sqrt)
df_sum=df.apply(np.sum,axis=0)
print(df_sum)
outer:
A B
0 4 9
1 4 9
2 4 9
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
A 12
B 27
dtype: int64
Process finished with exit code 0















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









