







系列篇章💥
目录
前言
在AI大模型技术飞速发展的当下,图像生成领域不断涌现令人惊艳的创新成果。其中,由Tiamat AI、ShanghaiTech University、National University of Singapore、Liblib AI等机构联合打造的EasyControl框架脱颖而出,其衍生的EasyControl Ghibli更是备受瞩目。这款AI模型专注于将普通图像转化为极具魅力的吉卜力风格图像,为广大用户开启了一场独特的艺术创作之旅。本文将深入剖析EasyControl Ghibli的技术原理、功能特性、应用场景以及使用方法,帮助大家全面了解这一创新技术。

一、项目概述
EasyControl Ghibli 是基于强大的 EasyControl 框架精心开发的 AI 模型,目前已在 Hugging Face 平台上线。它的定位非常明确,那就是专注于把普通图像转化为充满魅力的吉卜力风格图像。这款模型的训练数据别具一格,仅仅使用了 100 张亚洲人脸照片以及由 GPT - 4o 生成的对应吉卜力风格图像。但令人惊叹的是,它却能精准地捕捉到吉卜力作品中那些柔和的光影、细腻的情感和温暖的色调,同时还能很好地保留人物的面部特征。对于用户而言,操作极为简便,只需上传照片或者输入简单指令,就能免费生成吉卜力风格的图像。
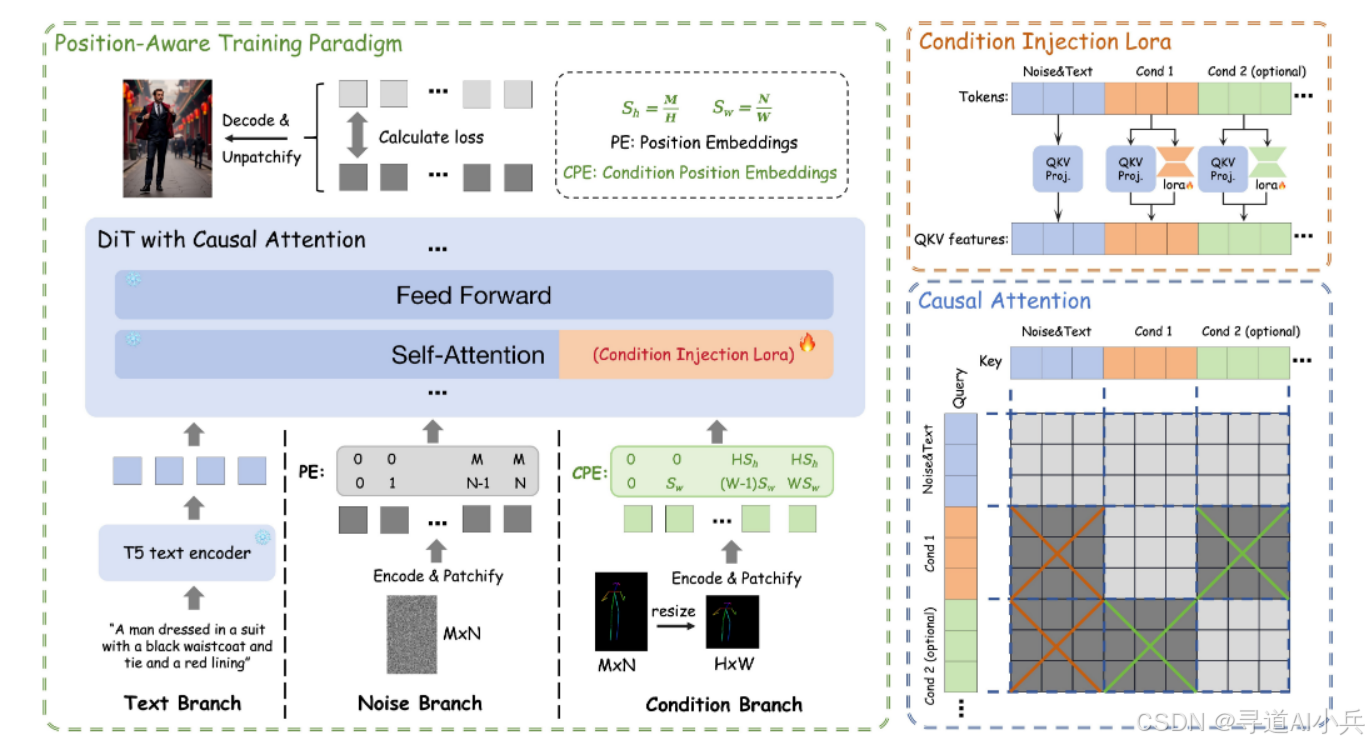
二、技术原理
(一)扩散模型架构基础
EasyControl Ghibli基于扩散模型架构,这是一种在图像生成领域表现卓越的技术。扩散模型的核心原理是通过在数据分布上逐步添加噪声,然后学习如何从噪声中反向恢复出原始数据,从而生成高质量且多样化的图像。在这个过程中,模型不断学习噪声与图像之间的关系,使得生成的图像能够符合预期的分布特征。
(二)条件注入模块
项目引入了基于LoRA(Low - Rank Adaptation)技术的条件注入模块。该模块将条件信号独立处理并注入到模型中,具体通过对条件分支进行低秩投影,同时保持文本和噪声分支的权重不变,实现了条件信号的高效注入。这使得模型能够根据用户输入的特定条件,如吉卜力风格要求,准确地生成相应的图像。例如,在生成吉卜力风格图像时,模型可以根据预设的风格条件,调整图像的光影、色调等元素,使其呈现出吉卜力作品的独特风格。
(三)Position - Aware Training Paradigm与KV Cache技术
Position - Aware Training Paradigm和KV Cache技术是EasyControl Ghibli实现高效性的关键。Position - Aware Training Paradigm通过对图像的位置信息进行有效编码,使得模型能够学习到图像中不同位置的特征差异,从而更好地处理不同分辨率和宽高比的图像。而KV Cache技术则通过缓存计算过程中的中间结果,避免了重复计算,显著降低了计算复杂度和推理时间,提高了模型的运行效率。
(四)小数据集训练与特征学习
EasyControl Ghibli仅使用100张真实亚洲面孔照片及对应的GPT - 4o生成的吉卜力风格图像进行训练,却能精准捕捉吉卜力作品的风格特征。这得益于模型强大的学习能力和高效的训练算法。在训练过程中,模型能够从有限的数据中提取关键的风格和内容特征,并进行有效融合,使得生成的图像在保留面部特征的同时,完美呈现吉卜力风格。
三、主要功能
(一)图像风格转换
将普通照片转换为吉卜力动画风格图像是EasyControl Ghibli的核心功能。吉卜力风格以其柔和的光影、细腻的情感表达和温暖的色调著称,EasyControl Ghibli能够精准捕捉这些特点。无论是人物照片还是风景照片,经过模型处理后,都能呈现出如吉卜力动画般的艺术效果,为用户带来全新的视觉体验。
(二)面部特征保留
在风格转换过程中,模型能较好地保留人物面部特征。它通过对图像内容和风格的有效分离与融合,确保生成的吉卜力风格图像既具备独特的艺术风格,又能让观众清晰识别出原图像中的人物主体,实现了风格与内容的平衡。
(三)免费使用
目前,EasyControl Ghibli完全免费,这大大降低了使用门槛,让更多用户能够轻松体验吉卜力风格图像的生成乐趣。无论是专业艺术家还是普通爱好者,都可以在无需支付费用的情况下,利用该工具进行创意创作。
四、应用场景
(一)插画与绘画
对于艺术家和设计师来说,EasyControl Ghibli是一个强大的创作助手。它可以快速生成具有吉卜力风格的插画草图或灵感图,为创作提供丰富的素材和创意启发。在绘制插画时,用户可以将自己的创意通过简单的文本描述或上传参考图像,借助模型生成的吉卜力风格图像,进一步完善和细化作品,提高创作效率。
(二)动画制作
动画工作室可以利用EasyControl Ghibli快速生成吉卜力风格的角色和场景设计。在动画前期制作阶段,这些设计可以为动画师提供初步的视觉参考,帮助他们更好地理解和把握角色形象和场景氛围,节省设计时间和成本。同时,生成的吉卜力风格图像也可以作为动画风格测试的素材,为动画风格的确定提供更多选择。
(三)广告与宣传
广告公司可以运用生成的吉卜力风格图像吸引观众的注意力。吉卜力风格独特的艺术魅力能够为广告和宣传材料增添艺术感和吸引力,尤其适合针对年轻受众的市场推广。例如,在制作电子产品、文化活动等广告时,使用吉卜力风格图像可以更好地传达产品或活动的创意和活力,提升广告效果。
(四)照片风格转换
普通用户可以将自己的照片转换为吉卜力风格,体验独特的创作乐趣。无论是个人生活照片还是旅行照片,经过EasyControl Ghibli处理后,都能变成具有艺术感的作品。用户可以将这些照片分享到社交媒体上,展示自己的创意和个性,吸引更多关注和互动。
(五)社交媒体分享
在社交媒体时代,用户热衷于分享独特的内容。EasyControl Ghibli生成的吉卜力风格图像因其独特的艺术风格,在社交媒体上具有很高的传播价值。用户可以将这些图像分享到各大社交平台,吸引更多用户的关注和点赞,增加个人账号的影响力。
五、在线体验
想要便捷体验 EasyControl Ghibli 的功能,可以直接访问Hugging Face 模型库提供的平台;
在线地址:https://huggingface.co/spaces/jamesliu1217/EasyControl_Ghibli
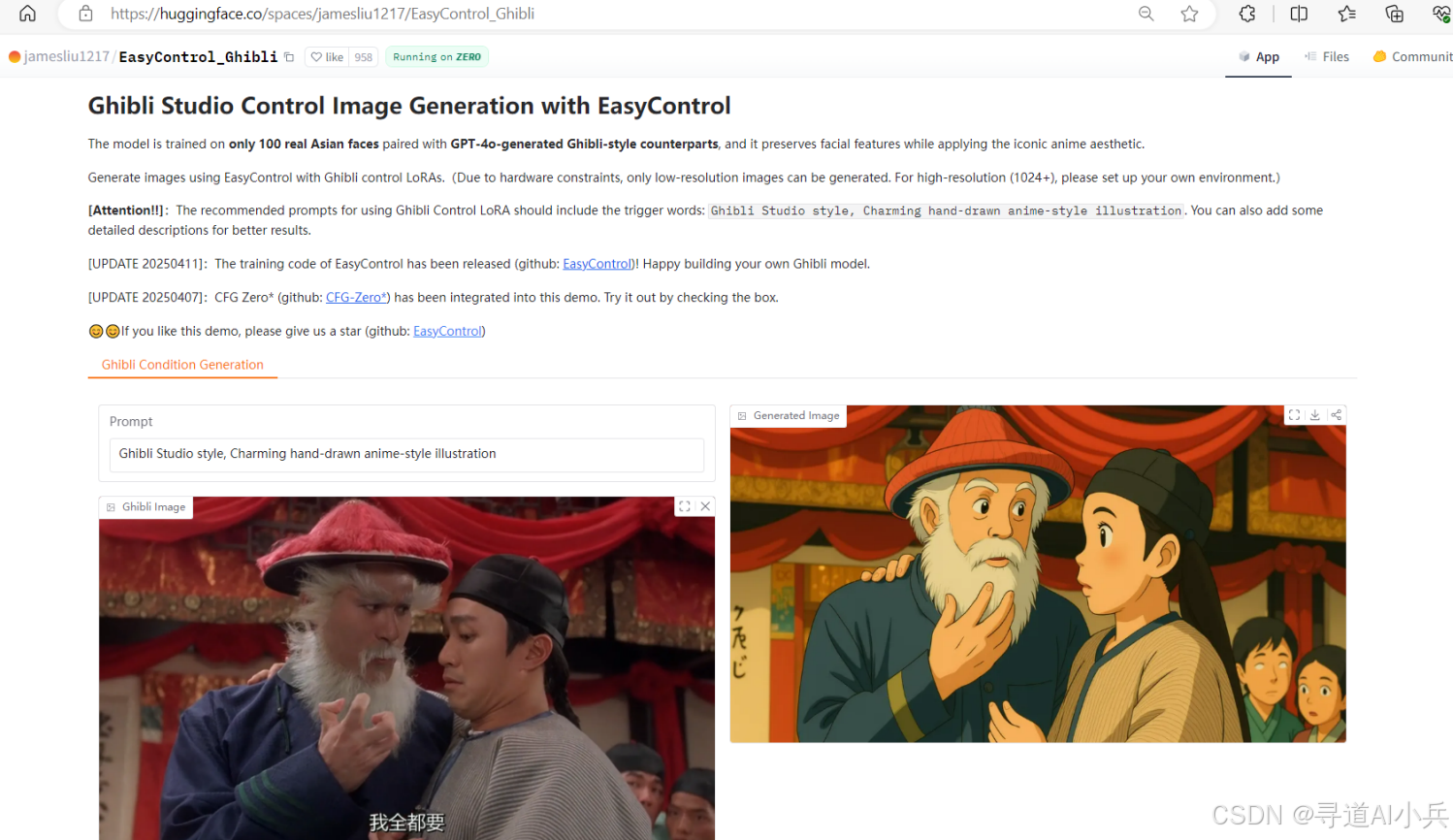
六、快速使用
(一)环境搭建
- 首先,需要创建一个新的conda环境。打开终端,输入以下命令:
conda create -n easycontrol python=3.10
conda activate easycontrol
这将创建一个名为easycontrol的conda环境,并激活该环境,确保后续安装的依赖都在这个环境中。
2. 安装其他依赖项。在激活的conda环境中,执行以下命令安装项目所需的依赖:
pip install -r requirements.txt
这些依赖包括项目运行所需的各种库,如PyTorch、Hugging Face相关库等,确保项目能够正常运行。
(二)模型下载
- 从Hugging Face下载模型。可以使用Python脚本进行下载,示例代码如下:
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="Xiaojiu-Z/EasyControl", filename="models/canny.safetensors", local_dir="./")
hf_hub_download(repo_id="Xiaojiu-Z/EasyControl", filename="models/depth.safetensors", local_dir="./")
# 依次下载其他模型文件,如hedsketch、inpainting、pose、seg、subject、Ghibli等
- 如果无法访问Hugging Face,也可以使用hf - mirror进行下载。先设置环境变量:
export HF_ENDPOINT=https://hf-mirror.com
然后使用以下命令下载模型:
huggingface-cli download --resume-download Xiaojiu-Z/EasyControl --local-dir checkpoints --local-dir-use-symlinks False
(三)使用示例
以生成吉卜力风格图像为例,代码示例如下:
import spaces
import os
import json
import time
import torch
from PIL import Image
from tqdm import tqdm
import gradio as gr
from safetensors.torch import save_file
from src.pipeline import FluxPipeline
from src.transformer_flux import FluxTransformer2DModel
from src.lora_helper import set_single_lora, set_multi_lora, unset_lora
# 初始化图像处理器
base_path = "black-forest-labs/FLUX.1-dev"
lora_base_path = "./checkpoints/models"
pipe = FluxPipeline.from_pretrained(base_path, torch_dtype=torch.bfloat16)
transformer = FluxTransformer2DModel.from_pretrained(base_path, subfolder="transformer", torch_dtype=torch.bfloat16)
pipe.transformer = transformer
pipe.to("cuda")
def clear_cache(transformer):
for name, attn_processor in transformer.attn_processors.items():
attn_processor.bank_kv.clear()
# 定义生成图像的函数
@spaces.GPU()
def single_condition_generate_image(prompt, spatial_img, height, width, seed, control_type):
if control_type == "Ghibli":
lora_path = os.path.join(lora_base_path, "Ghibli.safetensors")
set_single_lora(pipe.transformer, lora_path, lora_weights=[1], cond_size=512)
spatial_imgs = [spatial_img] if spatial_img else []
image = pipe(
prompt,
height=int(height),
width=int(width),
guidance_scale=3.5,
num_inference_steps=25,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(seed),
subject_images=[],
spatial_images=spatial_imgs,
cond_size=512,
).images[0]
clear_cache(pipe.transformer)
return image
# 定义Gradio界面组件
control_types = ["Ghibli"]
with gr.Blocks() as demo:
gr.Markdown("# Ghibli Studio Control Image Generation with EasyControl")
gr.Markdown("The model is trained on **only 100 real Asian faces** paired with **GPT-4o-generated Ghibli-style counterparts**, and it preserves facial features while applying the iconic anime aesthetic.")
gr.Markdown("Generate images using EasyControl with Ghibli control LoRAs.(Due to hardware constraints, only low-resolution images can be generated. For high-resolution (1024+), please set up your own environment.)")
gr.Markdown("**[Attention!!]**:The recommended prompts for using Ghibli Control LoRA should include the trigger words: `Ghibli Studio style, Charming hand-drawn anime-style illustration`")
gr.Markdown("😊😊If you like this demo, please give us a star (github: [EasyControl](https://github.com/Xiaojiu-z/EasyControl))")
with gr.Tab("Ghibli Condition Generation"):
with gr.Row():
with gr.Column():
prompt = gr.Textbox(label="Prompt", value="Ghibli Studio style, Charming hand-drawn anime-style illustration")
spatial_img = gr.Image(label="Ghibli Image", type="pil")
height = gr.Slider(minimum=256, maximum=1024, step=64, label="Height", value=768)
width = gr.Slider(minimum=256, maximum=1024, step=64, label="Width", value=768)
seed = gr.Number(label="Seed", value=42)
control_type = gr.Dropdown(choices=control_types, label="Control Type")
single_generate_btn = gr.Button("Generate Image")
with gr.Column():
single_output_image = gr.Image(label="Generated Image")
single_generate_btn.click(
single_condition_generate_image,
inputs=[prompt, spatial_img, height, width, seed, control_type],
outputs=single_output_image
)
# 启动Gradio应用
demo.queue().launch()
在这个示例中,用户可以通过Gradio界面输入提示词、上传图像(可选)、设置图像尺寸和随机种子等参数,然后点击生成按钮,即可得到吉卜力风格的图像。
七、结语
EasyControl Ghibli作为一款创新的AI模型,为吉卜力风格图像生成提供了高效、便捷的解决方案。它基于先进的技术原理,具备强大的功能和广泛的应用场景,无论是对于专业人士还是普通用户,都具有极高的价值。随着技术的不断发展和完善,相信EasyControl Ghibli将在图像生成领域发挥更大的作用,为用户带来更多精彩的创作体验。
项目地址
开源地址:https://github.com/Xiaojiu-z/EasyControl
模型地址:https://huggingface.co/spaces/jamesliu1217/EasyControl_Ghibli

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!


















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











