







未接到的电话
上周六的早上,公司某个基地的MES数据库异常重启,结果因为夜里儿子发烧晚上没睡好,电话完全没听到,直到7点儿子醒来叫我起床。拿起手机一看十几个未接电话,十来个未接语音!微信群消息一堆,邮件报警一堆!作为公司唯一的DBA,可想而知,内心的惴惴不安~

处理问题
飞速打开电脑,连上VPN,登陆堡垒机,连接上数据库;除了节点2被踢出集群,未成功启动外,节点1正常,联系开发重启AP,即恢复了!恢复时间点为7:20!
应用恢复后开始梳理问题的整个时间线
6:09 节点1 /var/log/messages
节点1内存故障,是否有直接的关系?
Aug 3 06:09:36 sqmespmdb01 kernel: mce: Uncorrected hardware memory error in user-access at e52e5c7c0Aug 3 06:09:36 sqmespmdb01 kernel: Memory failure: 0xe52e5c: already hardware poisonedAug 3 06:09:36 sqmespmdb01 kernel: reserve_ram_pages_type failed [mem 0xe52e5c000-0xe52e5cfff], track 0x2, req 0x2Aug 3 06:09:36 sqmespmdb01 kernel: Could not invalidate pfn=0xe52e5c from 1:1 mapAug 3 06:09:36 sqmespmdb01 kernel: mce: Uncorrected hardware memory error in user-access at e52e5c7c0Aug 3 06:09:36 sqmespmdb01 kernel: Memory failure: 0xe52e5c: already hardware poisonedAug 3 06:09:36 sqmespmdb01 kernel: reserve_ram_pages_type failed [mem 0xe52e5c000-0xe52e5cfff], track 0x2, req 0x2Aug 3 06:09:36 sqmespmdb01 kernel: Could not invalidate pfn=0xe52e5c from 1:1 mapAug 3 06:09:36 sqmespmdb01 kernel: mce: Uncorrected hardware memory error in user-access at e52e5c7c0Aug 3 06:09:36 sqmespmdb01 kernel: Memory failure: 0xe52e5c: already hardware poisoned
6:17 节点2,alert log
提示关键信息ORA-15064/ORA-03113 实例被asmb kill
Sat Aug 03 06:17:09 2024NOTE: ASMB terminatingErrors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_asmb_73709.trc:ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channelProcess ID:Session ID: 1675 Serial number: 21Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_asmb_73709.trc:ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channelProcess ID:Session ID: 1675 Serial number: 21ASMB (ospid: 73709): terminating the instance due to error 15064Instance terminated by ASMB, pid = 73709
同时节点1的/u01/app/11.2.0/grid/log/hostname/alerthostname.log
集群alertlog 有节点被驱逐的信息
Node sqmespmdb02 is being evicted in cluster
[cssd(6403)]CRS-1615:No I/O has completed after 50% of the maximum interval. Voting file /dev/mapper/crs2 will be considered not functional in 8110 milliseconds2024-08-03 06:16:42.190:[cssd(6403)]CRS-1614:No I/O has completed after 75% of the maximum interval. Voting file /dev/mapper/crs2 will be considered not functional in 5150 milliseconds2024-08-03 06:16:43.628:[cssd(6403)]CRS-1611:Network communication with node sqmespmdb02 (2) missing for 75% of timeout interval. Removal of this node from cluster in 7.030 seconds2024-08-03 06:16:48.511:[cssd(6403)]CRS-1610:Network communication with node sqmespmdb02 (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.150 seconds2024-08-03 06:16:53.345:[cssd(6403)]CRS-1607:Node sqmespmdb02 is being evicted in cluster incarnation 552139512; details at (:CSSNM00007:) in /u01/app/11.2.0/grid/log/sqmespmdb01/cssd/ocssd.log.2024-08-03 06:17:37.971:[crsd(7231)]CRS-5504:Node down event reported for node 'sqmespmdb02'.2024-08-03 06:17:37.960:[cssd(6403)]CRS-1601:CSSD Reconfiguration complete. Active nodes are sqmespmdb01 .
理论上节点2被驱逐后,应该可以正常重启 并加入到集群,但是节点2 却没有能重启成功CRS-0215: Could not start resource 'ora.orcl.db'. 直到我后面手动startup才启动!why?
2024-08-03 06:34:46.106: [ CRSPE][895395584]{2:19175:2} CRS-2681: Clean of 'ora.orcl.db' on 'sqmespmdb02' succeeded2024-08-03 06:34:46.107: [ CRSPE][895395584]{2:19175:2} Sequencer for [ora.orcl.db 2 1] has completed with error: CRS-0215: Could not start resource 'ora.orcl.db'.
6:30 节点1 也出现异常重启
和前面节点2重启的报错类似,asmb将实例kill;至此时间点 两个节点均宕机,整个应用不可用,也是从6:30开始工厂端开始反馈系统异常。
Sat Aug 03 06:30:34 2024NOTE: ASMB terminatingErrors in file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_asmb_275469.trc:ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channelProcess ID:Session ID: 1675 Serial number: 1337Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_asmb_275469.trc:ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channelProcess ID:Session ID: 1675 Serial number: 1337Sat Aug 03 06:30:38 2024System state dump requested by (instance=1, osid=275469 (ASMB)), summary=[abnormal instance termination].System State dumped to trace file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_diag_275414_20240803063038.trcASMB (ospid: 275469): terminating the instance due to error 15064Sat Aug 03 06:31:07 2024
6:35 节点1重启完毕
节点1重启ok
Starting background process QMNCSat Aug 03 06:34:23 2024QMNC started with pid=92, OS id=221213Sat Aug 03 06:34:23 2024Redo thread 2 internally disabled at seq 61315 (CKPT)ARC1: LGWR is actively archiving destination LOG_ARCHIVE_DEST_1Completed: ALTER DATABASE OPEN /* db agent *//* {2:19175:2} */Archived Log entry 130567 added for thread 2 sequence 61314 ID 0x5f503d29 dest 1:ARC3: Archival startedARC0: STARTING ARCH PROCESSES COMPLETE
7:20 我上线 应用恢复
从时间线上看,整个应用宕机的时间应该是6:30-6:35,其他时间都至少有一个节点live,但是6:35-7:20这段时间为什么系统不可用呢?
应用为什么没自动恢复?
理论上6:35分后系统应该是正常的,那么我们需要找到可信的证据来证明数据库没问题,而是其他环节出了问题。
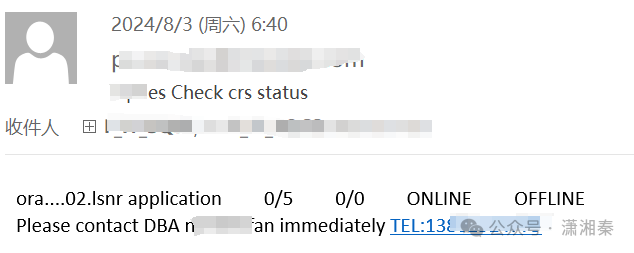
1.6:40集群邮件警报看,当前offline的服务只有节点2的listener,可以佐证节点1的各项服务正常
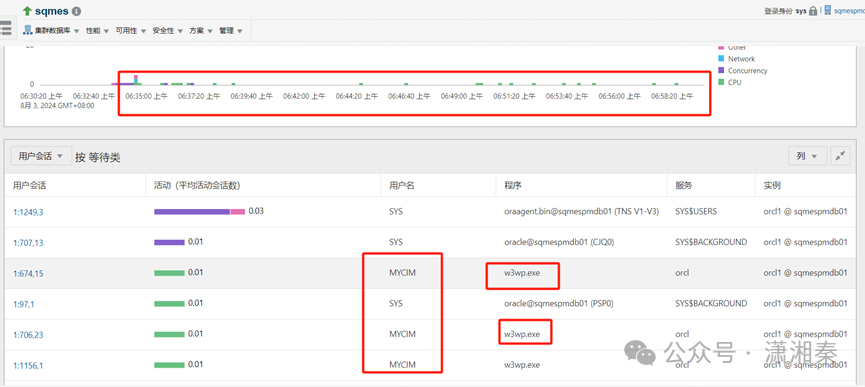
2.看OEM6:30-7:00的状态来看,6:35分后已经陆续有用户连接进数据库
数据库走势图看也没有明显的50分钟低负载
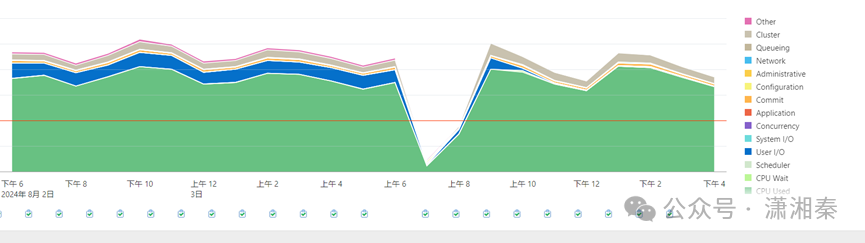
3.拉取节点1,7-8点的awr 也可以看到7点时已经有128的session
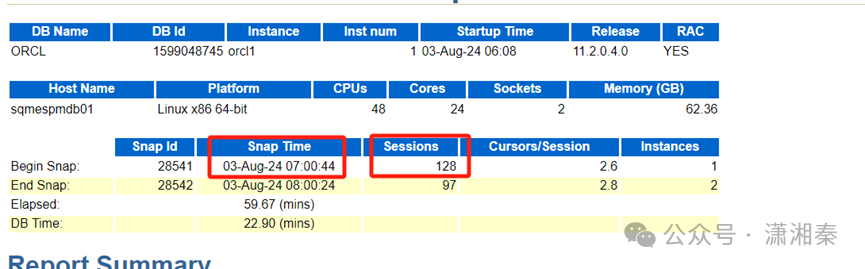
以上的这些数据都可以佐证6:35后数据库状态正常,用户可以连接,但是有个别应用模块,连接异常,导致应用未恢复。后面和开发同仁沟通也验证了我的猜测,是因为应用端自动重启脚本,检测的服务状态不准确,导致应用端未能自动重启。
全厂停线50分钟,这个锅谁来背
这次停线事故的锅谁来背?因为我没有接听到电话吗?因为开发端应用重启脚本不合理吗?
NO!NO!NO!都不是
根本原因是数据库挂了!oracle 这么大的公司,好好的数据库为啥会挂呢?这个锅必须要oracle来背!
问题处理完成第一时间就开了个SR,这种问题一般需要用oracle官方的TFA脚本收集系统数据,ORA-15064/ORA-03113的相关的BUG相当多,这次也不例外,具体如下
ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channel
从提供的信息我们看到,数据库实例检测到失去了和ASM的通信,所以导致实例被重启。NOTE: ASMB terminatingErrors in file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_asmb_275469.trc:ORA-15064: communication failure with ASM instanceORA-03113: end-of-file on communication channel而在ASM那边,可以看到如下的信息,这导致了ASM实例的重启。Sat Aug 03 06:20:25 2024LMON is running too slowly and in the middle of reconfiguration.LMON terminates the instance.Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_lmon_7147.trc:ORA-29702: error occurred in Cluster Group Service operationSat Aug 03 06:20:40 2024System state dump requested by (instance=1, osid=7167 (RBAL)), summary=[abnormal instance termination].System State dumped to trace file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_diag_7141_20240803062040.trcSat Aug 03 06:23:15 2024RBAL (ospid: 7167): terminating the instance due to error 481这里可以看到LMON检测到了 Cluster Group Service 的operation,并将ASM实例终止。在11.2.0.4 版本数据库中,这个问题看起来和 BUG 14674193 很相似。Bug 19496214 TERMINATION OF INSTANCE 2 CAUSES INSTANCE 1 AND INSTANCE 3 TO GET TERMINATED这个BUG 最终被 BUG 14674193 替代。Bug 14674193 : KJXGM_NOTIFY_EVICTION: EVICTION MEMBER COUNT 1 REASON 0X20000000这是由于在检测Cluster Group Service时 ,LMON 的行为过于激进,导致自我终止,并可能影响其他实例的问题。您可以尝试安装补丁 14674193 或者设置参数 _cgs_health_check_in_reconfig 来回避问题。Download Link:https://updates.oracle.com/download/14674193.htmlOralter system set "_cgs_health_check_in_reconfig"=false scope=both sid='*';This can be set dynamically for both ASM and database instances.
另外节点2 为什么重启失败 也是因为BUG
Sometimes the database instances are not restarted if ASM is killed
Bug 18336452 MANY DB INSTANCES FAIL TO START AFTER CRASH OF ASM
2024-08-03 06:34:46.106: [ CRSPE][895395584]{2:19175:2} CRS-2681: Clean of 'ora.orcl.db' on 'sqmespmdb02' succeeded2024-08-03 06:34:46.107: [ CRSPE][895395584]{2:19175:2} Sequencer for [ora.orcl.db 2 1] has completed with error: CRS-0215: Could not start resource 'ora.orcl.db'.参考文档:Sometimes the database instances are not restarted if ASM is killed ( Doc ID 1929526.1 )--CauseIt's due to the following:Bug 18336452 MANY DB INSTANCES FAIL TO START AFTER CRASH OF ASM
梳理下来整个过程大概如下:
6:09 节点1内存故障,导致节点1部分进程卡顿
6:17 节点2 lmon进程检测到cgs的缓慢触发bug19496214,导致集群reconfiguration,节点2重启,重启后又因为触发Bug 18336452 导致节点2的db启动失败,直到手动startup。
6:30 节点1 因为同样的BUG重启
6:35 节点1 重启完成,但因为应用端检测脚本问题应用未恢复
7:20 DBA介入后应用回复
所以最后锅全是oracle的,是因为oracle数据库的BUG,引起的系统宕机;我为什么一直建议甲方DBA一定要有个MOS账号,如果没有原厂来背书,哪怕你查到了问题,也难以让老板信服;外部厂商就是用来背锅的!而且对于oracle这样的厂家来说他们也乐于背锅!毕竟可以卖服务卖授权!
如果不会用mos可以参考如下文章
MOS(My Oracle Support)怎么用?Oracle DBA必备技能!_oracle mos-CSDN博客
参考文档
Sometimes the database instances are not restarted if ASM is killed (Doc ID 1929526.1)
Bug 19496214 TERMINATION OF INSTANCE 2 CAUSES INSTANCE 1 AND INSTANCE 3 TO GET TERMINATED
Bug 14674193 : KJXGM_NOTIFY_EVICTION: EVICTION MEMBER COUNT 1 REASON 0X20000000
Bug 18336452 MANY DB INSTANCES FAIL TO START AFTER CRASH OF ASM
















 1720
1720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











