







Faster R-CNN
Faster R-CNN主要贡献是提出RPN网络,用于替代Selective Search或其他的图像处理分割算法,实现端到端的训练(end-to-end)。

1.卷积层后插入RPN
RPN经过训练后直接产生Region Proposal,无需单独产生Region Proposal。
2. RPN后接ROI Pooling和分类层、回归层,同Fast R-CNN。
候选区域(anchor)
特征图可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{1282,2562,5122}×三种比例{1:1,1:2,2:1}这些候选窗口称为anchors。下图示出51*39个anchor中心,以及9种anchor示例。
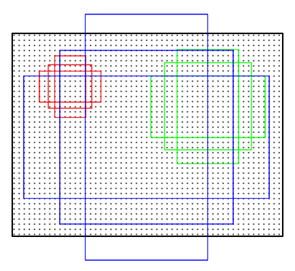
网络结构(RPN)
- 用一个小窗口滑动(3*3),生成256-d向量(N, H, W, 256)
- 连接分类层和Box回归层:分类层为2分类(前景和背景)。
- 3*3的窗口提供了图像的局部信息
- Box回归提供了更佳的定位信息。

- 每个位置有N个Anchor
- 回归输出Anchor Boxes的偏移量
- 分类器指定每个Anchor为前景的概率
1. 在原文中使用的是ZF model,其Conv Layers 中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
2.在conv5之后,做了rpn_conv/3x3卷积,相当于每个点又融合了周围3x3的空间信息。
3.假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
4.全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
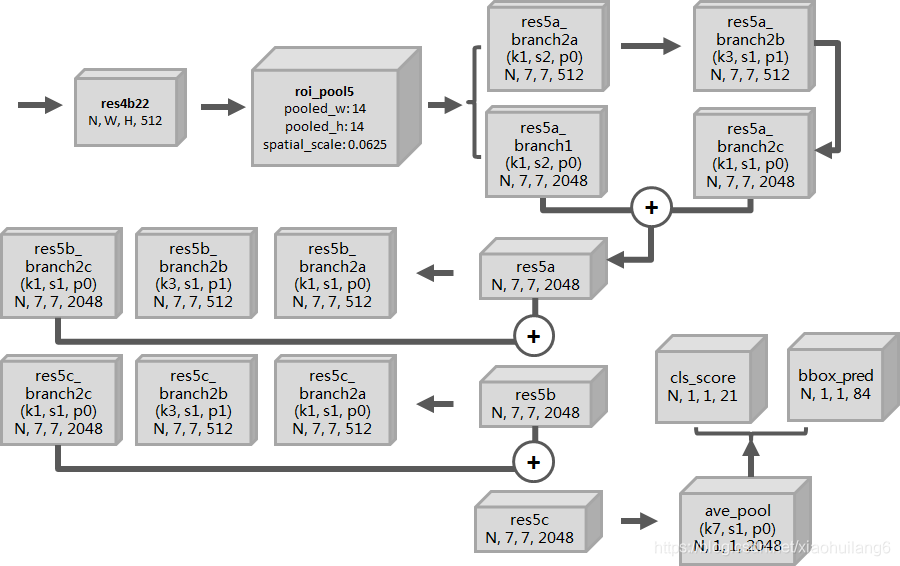
网络结构(RPN)(resnet-101)
| Name | Output | Param |
| res4b22 | N, W, H, 1024 |
|
| rpn/output | N, W, H, 256 | K3, p1, s1 |
| rpn_cls_score | N, W, H, 18 | K1,p0, s1 |
| rpn_cls_score_reshape | N, 2, W*H/2, 18 |
|
| rpn_loss_cls | 输入:rpn_labels | Weight:1 |
| Name | Output | Param |
| res4b22 | N, W, H, 1024 |
|
| rpn/output | N, W, H, 256 | K3, p1, s1 |
| rpn_cls_score | N, W, H, 18 | K1,p0, s1 |
| rpn_cls_score_reshape | N, 2, W*H/2, 18 |
|
| rpn_loss_cls | 输入:rpn_labels | Weight:1 |
AnchorTargetLayer层
bottom: 'rpn_cls_score'
bottom: 'gt_boxes'
bottom: 'im_info'
bottom: ‘data‘(特征图)
top: 'rpn_labels'
top: 'rpn_bbox_targets'
top: 'rpn_bbox_inside_weights'
top: 'rpn_bbox_outside_weights'
Proposal Layer forward(caffe layer的前传函数),即测试时,按照以下顺序依次处理:
1.生成anchors,计算得分。
2.利用im_info将fg anchors从MxN尺度映射回PxQ原图,判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors。
3.按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
4.进行nms(nonmaximum suppression,非极大值抑制)
5.再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
6.background样本同上。
根据筛选的Anchors计算rpn_bbox_targets
RPN损失:分类损失+正样本的SmoothL1Loss
Fast R-CNN模块网络结构
训练:
缩进Faster CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。实际中训练过程分为6个步骤:
1.在已经训练好的model上,训练RPN网络rpn_train1
2.利用步骤1中训练好的RPN网络,收集proposals, rpn_test
3.第一次训练Fast RCNN网络,fast_rcnn_train1
4.第二训练RPN网络,rpn_train2
5.再次利用步骤4中训练好的RPN网络,收集proposals, rpn_test
6.第二次训练Fast RCNN网络,对应fast_rcnn_train2
检测结果:
|
| R-CNN | Fast R-CNN | Faster R-CNN |
| Test time per image (with proposals) | 50 seconds | 2 seconds | 0.2 seconds |
| Speedup | 1x | 25x | 250x |
| mAP (VOC 2007) | 66.0 | 66.9 | 66.9 |
Res-Net 101 + Faster R-CNN + some extras

ImageNet 检测结果:2013-2015

参考文献:
https://arxiv.org/abs/1506.01497














 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









