







zero-shot learning
在零次学习(ZSL)中,训练集中的样本标签与测试集的标签是不相交的,即在训练时是没有见过测试集类别的样本的,而零次学习任务就是要识别出这些训练时没见过的类别的样本。既然要认出没见过的对象,那就要教会模型学习到更“本质”的知识,并且将这些知识“举一反三”,从已见过的类别(seen)迁移到没见过的类别(unseen)。在具体的实现中,模型会使用一层语义嵌入层,作为seen类和unseen类的迁移桥梁或者说中间表示,将seen类的知识迁移到unseen类,教会模型”举一反三“。而这个语义嵌入层具体会是对类别的一些描述,具体可能会是人工定义的属性或者词向量等语义表示。
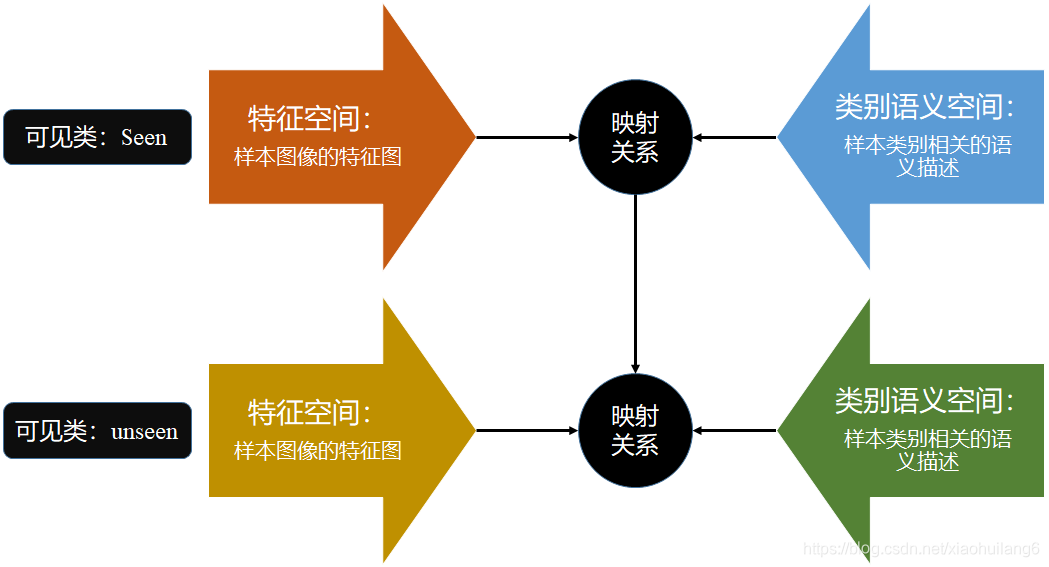
一般的,模型包括以下几个部分:(图1)
文章 Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer中描述了ZSL的两种类型:
Direct attribute prediction (DAP)

Indirect attribute prediction (IAP)

后续论文的创新主要建立在图1各个模块上的改进和创新,以及对上述文献中DAP模型的不足之处的改进:

Movtivation/Contribution:
其他模型依赖于额外的辅助信息(属性、词向量等)来建立seen类和unseen类之间的迁移——用每个类的类中心(KNN)/类均值(NCM)来取代ZSL中对于每个类的语义描述,然后学习一个度量,使得它们在seen和unseen类间共享,达到迁移的效果。
不要类别语义信息!!



Movtivation/Contribution:
线性映射,从特征空间到语义空间的映射。
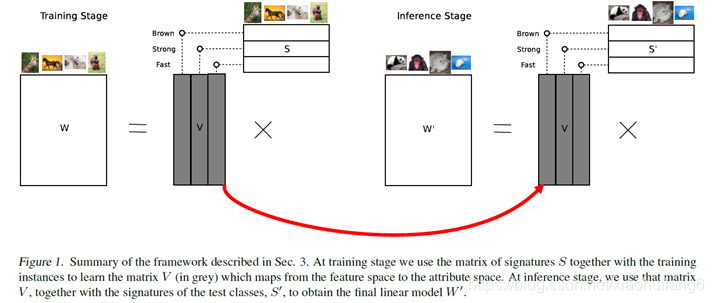

Movtivation/Contribution:
Contribution: 直接解决对类别的预测问题,而不是简单地对属性进行预测。
直接类别预测,不是属性预测(DAP)
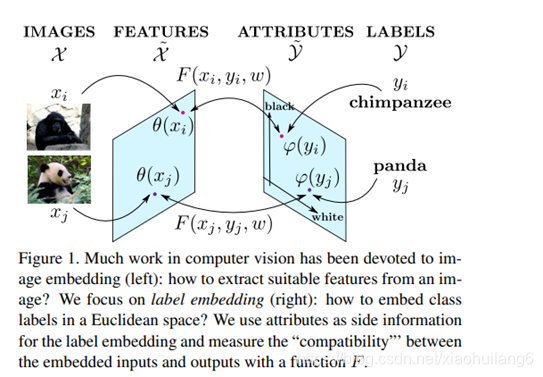



Movtivation/Contribution:
skip-gram文字模型对于无标注信息文字的语义信息浮点表示的有效性,该模型通过文档中的邻近项来学习 如何将一个文本表示为一个固定长度的嵌入向量(图1a右图)。由于同义词往往出现在相似的上下文中,所以这个简单的目标函数驱动模型学习语义相关单词的 相似嵌入向量。
Contribution:词嵌入具体相关性作为视觉神经网络监督信号训练网络。
类别语义信息方面的创新!!
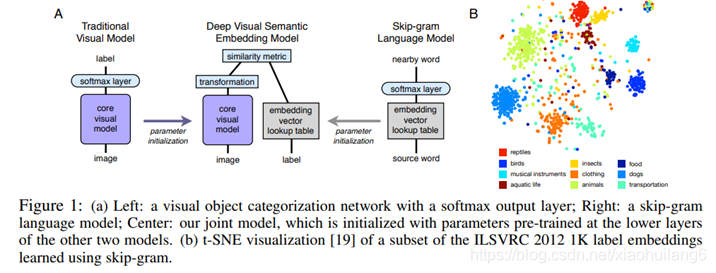
![]()

![]()

Movtivation/Contribution:
Contribution: 使用了多种辅助语义信息源,致力于取代ZSL的人工标注属性。
类别语义信息方面的创新!!
Structured Joint Embeddings(SJE)
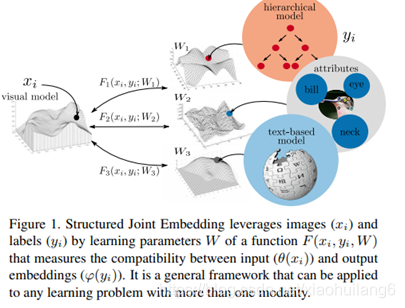


Movtivation/Contribution:
学习线性兼容函数并不特别适合于具有挑战性的细粒度分类问题。对于细粒度分类,需要一个能够自动将具有相似属性的对象分组在一起的模型,然后为每个组学习一个单独的兼容性模型。例如,可以分别学习两种不同的线性函数来区分棕色翅膀的蓝鸟和其他蓝色翅膀的蓝鸟。—通过一个隐变量,将SJE模型扩展为非线性:
多个模型实现非线性,映射方面创新!!
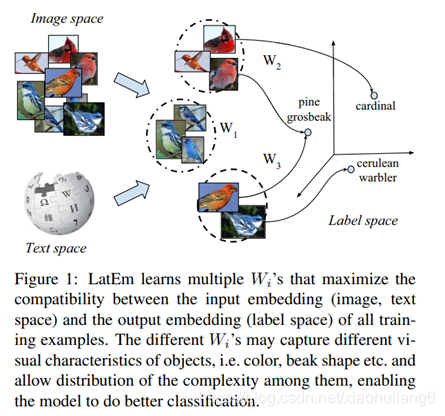

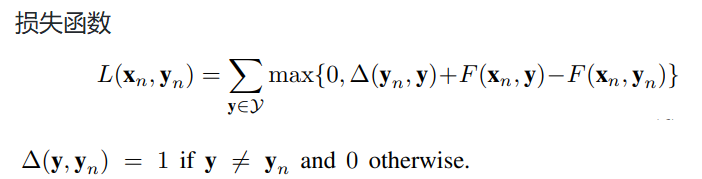

对于K的选取,有两种方法:
1.交叉验证;
2.基于剪枝的策略,该策略既具有竞争优势,又具有更快的训练速度。首先K取大值,并采用以下步骤修剪:
首先,对于每个样本,都选取一个线性模型进行评分,我们跟踪这些信息,并根据线性模型的数量建立一个直方图,计算每个线性模型被选择的次数。根据这个信息,在经过五次训练数据后,删除了选取次数不到选取5%的模型。
LatEm and SJE的不同:
1.LatEm为分段线性兼容函数,而SJE是线性的。不同的W针对不同的属性。
2.LatEm使用基于排序的损失,而SJE使用多类别损失。
Movtivation/Contribution:
两个不同域的空间的语义差距较大。增加一个中间的共享空间(第三方空间),将两个空间都嵌入该空间里,并且同时进行优化以保持语义一致性。
解决语义间隔问题:视觉特征与语义特征不一致
若目标域的混合比例和源域的混合比例相似,则他们来源于一个类别。
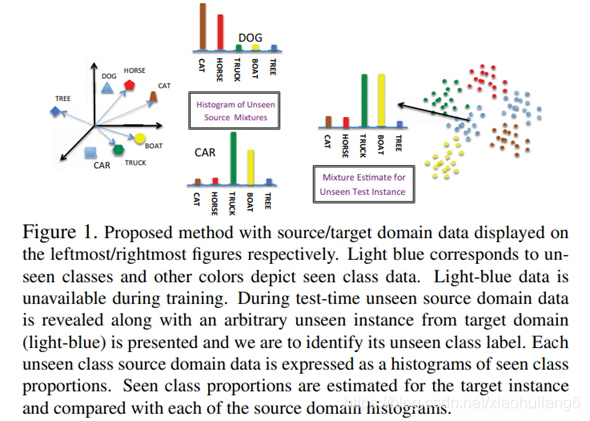



Movtivation/Contribution:
训练的可见类和测试的不可见类是不同的,,如果从可见类映射到可视特征上,不可见类图像的映射可能会丢失(漂移——通过自动编码机映射回去解决。)
解决邻域漂移问题:seen特征和unseen的不一样。
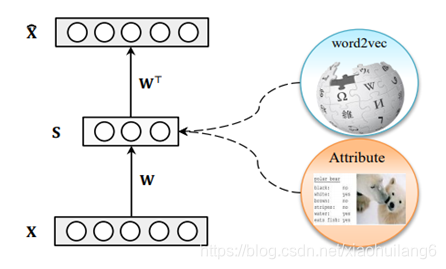


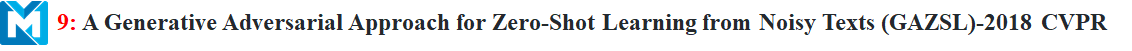
Movtivation/Contribution:
一般的模型语义空间到视觉空间是一对一映射的,但是文本描述可以对应视觉空间的各种点,是一对多的映射。因此存在偏差。(想象和实际样本之间的偏差)——通过添加噪声对抗学习一对多映射(一个可视化的中枢正则化器)。
解决邻域漂移问题:seen特征和unseen的不一样。



Movtivation/Contribution:
解决语义间隔问题:视觉特征与语义特征不一致




Movtivation/Contribution:
不可见类的属性信息在训练时没有使用!!
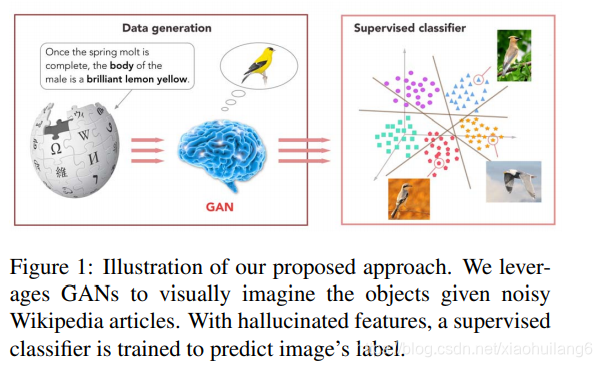
训练时利用整个词汇语义信息W进行学习,与ZSL不同的是,ZSL仅在测试时用到了测试类别的语义信息,而SS-Voc在训练时也使用了相同的语义信息。


Movtivation/Contribution:
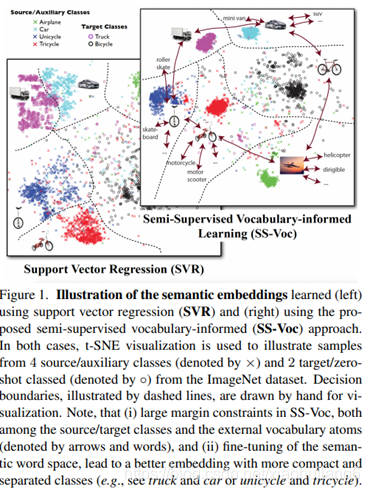
其他模型需要复杂的inference机制,专注于嵌入函数的设计和预定义的特征之间的度量(欧式距离)—该模型侧重于可迁移的深度度量(关系模型),提出一个包含ZSL和FSL的框架。
特征嵌入到属性空间后与属性之间的关系度量!!!

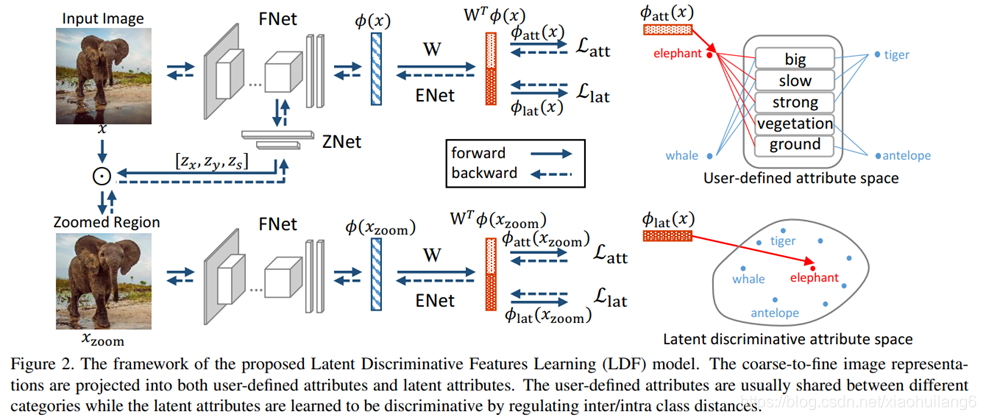
Movtivation/Contribution:
图像特征方面参与训练,语义特征方面挖掘潜在语义!!
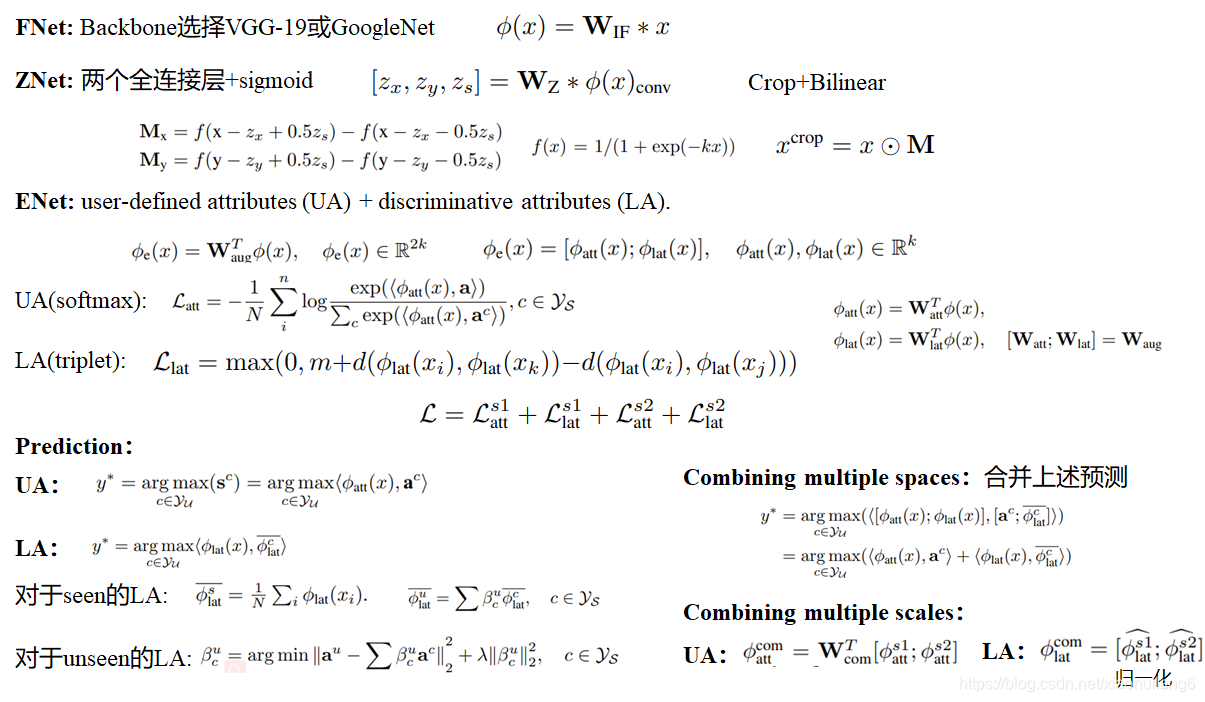
上述文章的详细内容见后续Zero-shot Learning 综述1-4


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









