






写在前面:
黄宁然,看你看过的算法系列*,不如,就到此吧。
参考文献镇楼:
[1]扫地机器人
[2]王雯涛,ORB图像特征提取算法的FPGA设计与实现
[3]房亮,基于ORB特征的单目视觉SLAM算法研究
[4]opencv官方源码,version:3.4.12
[5]一抹烟霞,ORB_SLAM3原理源码解读系列
注:csdn发文助手提示“外链过多”,故文献链接网址请见评论区。
问题来源:
笔者的执念。
1、原理简介
继上节BRIEF描述算子,BRIEF描述子的缺点是不具备尺度不变性、不具备旋转不变性[1]。2011年,Ethan Rublee等人提出了检测速度极快的ORB算法,该算法分为特征点提取和特征描述2个部分[2],包括oFAST(FAST keypoint Orientation,在文献3中,称之为oriented FAST)和rBRIEF(rotation Binary Robust Independent Elementary Feature)[3]。ORB算子改进了FAST算子,在使用FAST算子检测关键点之后,还为每个关键点计算主方向,弥补FAST本身不具有方向性的缺陷[2];同时,ORB在使用BRIEF算子生成描述符时,会用到关键点的方向信息,构造旋转矩阵,使得具备旋转不变性。
另外,ORB算子会对原始图像构造图像金字塔,对每层(尺度)金字塔图像均会检测关键点,因而具备尺度不变性。
ORB算子的主要步骤流程分为:构造图像金字塔、使用oFAST检测图像关键点、使用rBRIEF为关键点生成描述符。
2. 图像金字塔
图像金字塔是将图像放在多个尺度进行观察,从小尺度到大尺度多个尺度层面上表达图像信息的一种处理方法[3]。一般图像金字塔类型有两种:根据高斯滤波操作进行降采样得到的高斯金字塔和根据拉普拉斯操作进行降采样得到的拉普拉斯金字塔。查看opencv源码的orb.cpp文件,ORB算子在构造图像金子塔时,使用的是不断降采样的方法,而降采样具体使用的是resize函数[4]。ORB算子预先定义好需要构造的金字塔的层数以及每层之间的比例系数,然后进行逐层构造。
3. oFAST检测图像关键点
FAST角点检测,之前博文已介绍,其基本原理在此不再赘述,这里只介绍ORB在使用FAST角点检测时不一样的地方。
3.1 计算关键点的方向
在oFAST检测出关键点位置之后,使用灰度质心法,计算每个关键点的方向信息。灰度质心的计算公式:

其中:
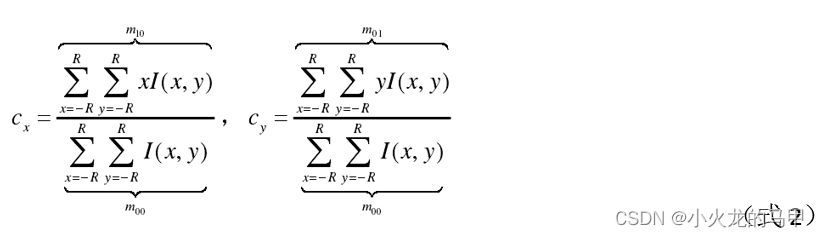
式中,I为图像,x、y是区域R内的坐标,可见,质心的计算主要就是计算灰度矩。在实际计算中,首先需要确定区域R(即参与灰度矩计算的像素集)。在orb.cpp文件中,体现为计算umax数组的过程,如示意图下图。
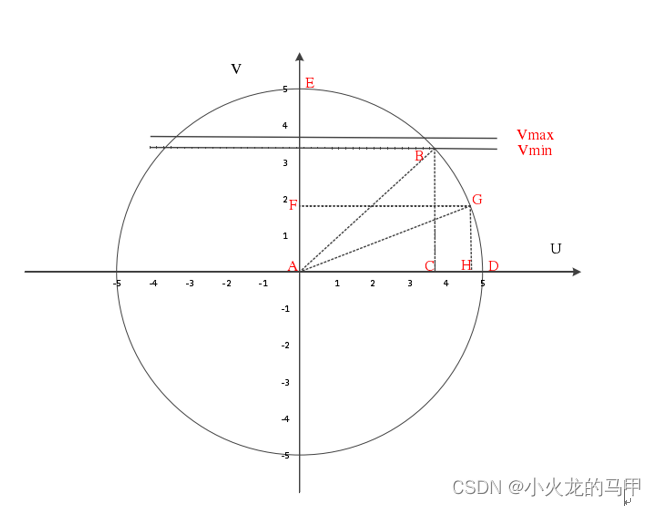
参与质心计算的区域是圆形区域,且对称,所以只需计算第一象限中参与质心计算的点集。而第一象限点集的计算又分为0~45度和45~90度两部分。对于0~45度区间,先确定vmax,然后使用勾股定理,计算出当v取值在[0,vmax]时的umax;对于45~90度区间,先确定vmin,然后结合与0~45度区间的对称性,计算出当v取值在[vmin,r]时的umax(r为圆半径)[3,5]。求得灰度矩后,关键点的方位角按下式计算:

3.2 关键点的筛选剔除
据orb.cpp文件,在使用FAST检测出关键点后,会有2次的关键点剔除。第一次剔除,是根据FAST算子计算出的关键点的响应值,保留响应值较大的前N1个关键点;第二次剔除,则是在第一次保留的关键点基础上,使用Harris算子为每个关键点重新计算响应值,然后再次根据响应值大小,保留响应值较大的前N2个关键点。Harris角点相应的求取请见之前博文。
注意,ORB算子规定了最终最多保留的nfeatures个关键点,ORB算子会为每一金字塔层图像分配相应的关键点数量。
4. rBRIEF生成描述符
BRIEF算子生成描述符的原理请见上节博文,这里,仅介绍不一样的地方。rBRIEF在为每个关键点生成描述符时,还考虑到关键点的方向信息。
在oBRIEF算子中,当kBytes取32时,是在关键点31×31的邻域内,选择256对比较点[3]。使用2×n的矩阵来表示这些点集:

oBRIEF算子中不是直接使用这些点对,而是根据关键点的方向角θ,构造旋转矩阵,

并对原始点集进行变换:

然后使用新的点集进行比对。个人理解是,将原始点集旋转到主方向上,因此,当原始图像发生旋转后,比较的点集也会自动跟着算转,算子便具备了方向不变性。
5. python源码实现
orb参数,选择与opencv中ORB::create()函数中参数相同的默认值。
#coding=utf8
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
import cv2
import os,sys
import scipy.ndimage
import time
import scipy
import re
from pygame import Rect
# 对应于opencv中ORB类的成员变量,取值均为 ORB::create()函数中参数的默认取值 #
kBytes = 32;
HARRIS_SCORE = 0;
FAST_SCORE = 1
nfeatures = 500;
scaleFactor = 1.2;
nlevels = 8
edgeThreshold = 31 #边界阈值,进行fast角点检测后,超过边界阈值的关键点,将会被剔除
firstLevel = 0
WTA_K = 2; wta_k = WTA_K;
scoreType = HARRIS_SCORE;
patchSize = 31; #对应于BRIEF算子中的PATCH_SIZE,
fastThreshold = 20;
HARRIS_K = 0.04
基础子函数
######################################### 基础子函数 ##### ###########################################################
# 计算每一金字塔层相对于第一层的缩放系数
def getScale( level, firstLevel, scaleFactor):
return np.power(scaleFactor,(level - firstLevel) )
# 剔除越界的关键点
def runByImageBorder(kps,img_src,border_size):
r = Rect(border_size,border_size,img_src.shape[1]-border_size,img_src.shape[0]-border_size)
newkp=[]
for kp in kps:
x,y = kp.pt
if x>=r[0] and y>=r[1] and x<r[2] and y<r[3]:
newkp.append(kp)
return newkp
# 保留前n_points个关键点,依据是每个keypoint的response大小
def retainBest( keypoints, n_points):
if n_points>=0 and len(keypoints)>n_points:
res = np.array([kp.response for kp in keypoints])#记录所有keypoints的response
index = np.argsort(res) #得到排序index
index = index[::-1] #从大到小排序
new_kps = np.array(keypoints)[index[0:n_points]] #取前npoints个
new_kps = list(new_kps)
else: #若允许保留的数量大于本身keypoints的数量,则全部保留
new_kps = keypoints
return new_kps
计算keypoints相关函数
################################ 下面为计算keypoints用到的函数 ########################################################
# 使用harris方法计算角点响应, 输入参数img为整个金字塔图像
def HarrisResponses(img, layerinfo, pts, blockSize, harris_k):
radius = (int)(blockSize/2)
scale = 1.0 / ((1 << 2) * blockSize * 255.0)
scale_sq_sq = scale * scale * scale * scale
for ptidx in range(0,len(pts)):# 对于每一个keypoints
# 每个keypoint的pt位置,仅仅是对于所在层的局部位置,不是整个金字塔图像的全局位置
# 而输入图像img是整个金字塔图像,所以需要将局部位置转换为全局位置
x0 = (int)(np.round( pts[ptidx].pt[0] ) ) # 得到关键点的pt.x
y0 = (int)(np.round(pts[ptidx].pt[1] ) ) # 得到关键点的pt.y
z = (int)(pts[ptidx].octave) #得到所在layer信息
# layerinfo[z]保存的是该层图像在整个金字塔图像中的位置,[x,y,w,h]
center_r,center_c = (layerinfo[z])[1]+y0,(layerinfo[z])[0]+x0
a, b, c = 0, 0, 0
for index_r in range(-radius,blockSize-radius): #保证窗口大小为 :(blockSize-radius)-(-radius) = blockSize
for index_c in range(-radius,blockSize-radius):
rr,cc = center_r+index_r,center_c+index_c
# 使用sobel系数计算x、y方向的偏导数
Ix = (1.0 * img[rr, cc + 1] - img[rr, cc - 1]) * 2 + (
1.0 * img[rr - 1, cc + 1] - img[rr - 1, cc - 1]) + (
1.0 * img[rr + 1, cc + 1] - img[rr + 1, cc - 1])
Iy = (1.0 * img[rr + 1, cc] - img[rr - 1, cc]) * 2 + (
1.0 * img[rr + 1, cc - 1] - img[rr - 1, cc - 1]) + (
1.0 * img[rr + 1, cc + 1] - img[rr - 1, cc + 1])
a += Ix * Ix
b += Iy * Iy
c += Ix * Iy
# 计算harris角点响应,详见https://blog.csdn.net/xiaohuolong1827/article/details/125559091,
# 但不明白为什么要乘以scale系数
pts[ptidx].response = (a * b - c * c - harris_k * (a + b) * (a + b))*scale_sq_sq
return pts
# 使用灰度质心法,计算keypoint的方向
def ICAngles( img, layerinfo, pts, u_max, half_k):
step = img.shape[1] #img为uint8
ptsize = len(pts)
for ptidx in range(0,ptsize):#对于每一个keypoint
layer = layerinfo[pts[ptidx].octave];#获取该keypoint所在的位置信息,不含border部分
# 计算keypoint时,使用的图像是不包含border部分的,得到的keypont位置是个局部位置,
# 而现在计算方向,输入img是整个金字塔图像,所以先将keypoint的pt位置转换到全局位置
center_r,center_c = np.round(pts[ptidx].pt[1]) + layer[1] , np.round(pts[ptidx].pt[0]) + layer[0]
# 开始计算质心,v代表y方向,u代表x方向
m_01 = 0; m_10 = 0;
# 先对v=0时,做特殊处理,
for u in range(-half_k,half_k+1):
r,c = int(center_r) ,int(center_c+u)
m_10 += u * img[r,c];
# 对于v的其它取值,进行逐行扫描,
# 只扫描v取值为正的情况,即圆的下部分,而上部分则是用对称的方法,顺带进行了计算
for v in range(1,half_k+1):
v_sum,d = 0 ,u_max[v]#u_max[v]代表当前行中,可取的最大列
for u in range(-d,d+1): #『-d,+d],可见取了圆的左边、右边
r, c = int(center_r+v), int(center_c + u)# +v,取了圆的下边部分
val_plus = int(img[r,c])
r, c = int(center_r - v), int(center_c + u)#-v,取了圆的上边部分
val_minus = int(img[r,c])
v_sum += (val_plus - val_minus)
m_10 += u * (val_plus + val_minus)#乘以x方向的坐标,累加
m_01 += v * v_sum; #乘以y方向的坐标,累加
pts[ptidx].angle = cv2.fastAtan2( (float)(m_01), (float)(m_10))#完善方向角信息
return pts
# 计算keypoints
def computeKeyPoints(imagePyramid, uimagePyramid,maskPyramid, layerInfo, ulayerInfo, layerScale,allKeypoints,nfeatures,
scaleFactor, edgeThreshold, patchSize, scoreType, useOCL, fastThreshold):
nlevels = len(layerInfo) #获取金字塔层数
nfeaturesPerLevel=[]
factor = (float)(1.0 / scaleFactor)
ndesiredFeaturesPerScale = nfeatures * (1 - factor) / (1 - np.power(factor, nlevels) ) #每层金子塔允许的关键点数,
sumFeatures = 0;#累计关键点数量
for level in range(0,nlevels-1):
nfeaturesPerLevel.append( (int)( np.round(ndesiredFeaturesPerScale)) )
sumFeatures += nfeaturesPerLevel[level]
ndesiredFeaturesPerScale *= factor#计算每层金子塔允许的关键点数
nfeaturesPerLevel.append ((int)( np.max((nfeatures - sumFeatures, 0)) ) )#将剩余的数量,赋给最后一层
halfPatchSize =(int)( patchSize / 2)
allKeypoints = []
counters=[]
for level in range(0,nlevels):
featuresNum = (int)(nfeaturesPerLevel[level])
r = layerInfo[level] #获取该层图像位于金字塔图像数组中的具体位置,不含border部分
img = imagePyramid[r[1]:r[1]+r[3],r[0]:r[0]+r[2]] #从金子塔中提取该层的图像
mask = None
# 借助fast算子,计算该层图像的keypoints
fd = cv2.FastFeatureDetector_create(threshold=fastThreshold,nonmaxSuppression=True,type=cv2.FastFeatureDetector_TYPE_9_16)
keypoints = fd.detect(img,mask=mask)
# 对获取到的keypoints,剔除越界的点
keypoints = runByImageBorder(keypoints,img, edgeThreshold)
# 根据response的大小,仅仅保留前前N个关键点,这里N为2 * featuresNum,在下一阶段,还有一次关键点的剔除,所以这次会多保留一些关键点,
keypoints = retainBest(keypoints, (2 * featuresNum) if (scoreType == HARRIS_SCORE) else featuresNum)
nkeypoints =len(keypoints)
counters.append(nkeypoints)#记录每层金字塔图像的关键点数量
sf =float( layerScale[level])#获取每层金字塔图像的缩放系数
for i in range(0,nkeypoints):
keypoints[i].octave = level;#为每个keypoints的octave赋值
keypoints[i].size = patchSize * sf;#每层金字塔图像的尺寸会按sf进行缩放,所以每层的patcshSzie也要相应的缩放
for kp in keypoints:
allKeypoints.append(kp) #保存每层金字塔图像的的每个keypoint
nkeypoints = len(allKeypoints)
if (nkeypoints == 0):
return
# 使用Harris算子重新 计算每个keypoint的response值,后续将根据新的response值,进行第二轮筛选
allKeypoints = HarrisResponses(imagePyramid, layerInfo, allKeypoints, 7, HARRIS_K)
newAllKeypoints=[]
offset = 0
# 对每层金字塔的keypoints进行重新筛选
for level in range(0,nlevels): #对于每一层金字塔
keypoints = []
featuresNum = int(nfeaturesPerLevel[level]) #获取该层金字塔图像允许的最大关键点数量
nkeypoints = int(counters[level]) #得到该层金字塔图像当前拥有的关键点数量
for i in range(0+offset,0+offset+nkeypoints): #从总的keypoinsts数组中,提取出该层金字塔图像的keypoints
keypoints.append(allKeypoints[i])
offset += nkeypoints #跟新offset,为提取下一层做准备
#print(len(keypoints))
keypoints2 = retainBest(keypoints,featuresNum)# 按response大小,仅仅保留前featuresNum个关键点
for kp in keypoints2:
newAllKeypoints.append(kp) #将当前层金字塔图像的keypoints保存到新的数组中
#keypoints的第二轮筛选完毕,更新赋值
allKeypoints = newAllKeypoints
nkeypoints = len(allKeypoints)
# 接下来开始计算每个keypoint的方向信息
# 方向信息使用灰度质心法计算,对于每个keypoint,需要确定该中心点周围的哪些像素会参与计算,即u和v坐标范围
# 开始计算u和v的取值范围,u和v即是使用灰度质心法求方向时使用到的所有像素的坐标
# u代表x方向,表示列,v代表y方向,表示行
# 这些坐标保存在umax数组内,数组的长度代表了v的取值范围,数组的值,代表了u的取值范围;其实umax仅仅保存的是第一象限部分,其它象限使用对称方法计算
# 例如,若umax[0]=15,则表示,当v取值为0时,u的取值范围是[-15,+15],
# 例如,若umax[1]=15,则表示,当v取值为1或者-1时,u的取值范围是[-15,+15]
umax = np.zeros((halfPatchSize + 2,)).astype(int) #确定umax的数组大小
vmax = (int)(np.floor((halfPatchSize * np.sqrt(2.) / 2 + 1))) # 对第一象限的1/4圆,在0到45度时,v的最大取值
for v in range(0, vmax + 1):
umax[v] = ( np.round( np.sqrt( (np.float64)(halfPatchSize * halfPatchSize) - v * v ) ) )#根据勾股定理,求出umax
vmin = np.ceil( halfPatchSize * np.sqrt(2.0) / 2 )# 对第一象限的1/4圆,在45到90时,v的最小取值
#这里使用对称法,求45到90度时,umax的取值,个人没弄明白,可参阅参考文献
v ,v0 = halfPatchSize, 0
while (v >= vmin):
while (umax[v0] == umax[v0 + 1]):
v0 = v0 + 1
umax[v] = v0
v0 = v0 + 1
v = v - 1
# umax存储了计算质心时使用到的周围像素点,开始计算keypoints的方向
allKeypoints = ICAngles(imagePyramid, layerInfo, allKeypoints, umax, halfPatchSize)
# 对每层金字塔图像keypoints的pt信息进行更新,以折算到原始图像尺寸大小对应的pt
for i in range(0,nkeypoints):
scale = layerScale[ allKeypoints[i].octave] #octave代表了l所在的evel信息
allKeypoints[i].pt = (allKeypoints[i].pt[0] * scale, allKeypoints[i].pt[1] * scale)#将pt折算到原始图像尺寸对应的位置
return allKeypoints
################################# 下面为计算descriptor用到的函数 ######################################################
# 将opencv源码orb.cpp文件中的bit_pattern_31_[256 * 4]数组,存为txt文件,
# 再由python读取,获得比较点对 ,在构造描述符中会用到 #
def get_bit_pattern_31():
with open('bit_pattern_31.txt') as f:
rawtxt = f.read()
str1 = rawtxt
str1 = str1.replace("\t","")
str1 = str1.replace("\n","")
str1 = (re.findall("\{(.+?)\}", str1))[0]
temp = re.findall("\/(.+?)\/",str1)
for t in temp:
s = '/'+t+"/"
str1 = str1.replace(s,"")
str1 = str1.replace(" ","")
str1 = str1.split(",")
data = np.array([int(s) for s in str1])
return data
# 从图像金字塔中取像素
# pattern和idx确定了初始的位置信息
# a和b反映了keypoint方向信息(cos和sin的值),用来对初始位置信息进行旋转变换
def GET_VALUE(idx,pattern,a,b,imagePyramid,cy,cx):
# pattern存放的是待比较点的位置,但这里并不是直接取用,还需要考虑keypoint本身的方向性,
# 结合sin和cos值,得到旋转变换后的位置
x = pattern[idx][0]* a - pattern[idx][1] * b
y = pattern[idx][0]* b + pattern[idx][1] * a
ix = int(np.round(x))#得到旋转后的坐标
iy = int(np.round(y))#得到旋转后的坐标
return imagePyramid[cy+iy,cx+ix] #返回像素值
# 计算keypoints的描述符descriptor
def computeOrbDescriptors(imagePyramid, layerInfo, layerScale, keypoints, _pattern, dsize, wta_k):
descriptors = []
for i in range(0,len(keypoints)):#对于每一个keypoint
kpt = keypoints[i]
layer = layerInfo[int(kpt.octave)] #获取所在level层金字塔图像位于整个金字塔图像的位置,[x,y,w,h]
scale = 1.0/layerScale[int(kpt.octave)] # 得到缩放系数
angle = kpt.angle/180.0*np.pi #得到方向角
a,b = np.cos(angle),np.sin(angle) #计算sin和cos,接下来取位置点时会用到,主要是用来旋转、满足旋转不变性
# 在上述计算keypoint时,pt经过了scale缩放、统一变换到原始图像尺寸的位置了,所以这里要再缩放回去
# 同时pt位置是相对于每层金字塔图像的局部位置,而接下来使用的是整个金字塔图像,所以需要将pt换算到整个金字塔图像的绝对位置
cy,cx = int(np.round(kpt.pt[1]*scale)+layer[1]), int(np.round(kpt.pt[0]*scale)+layer[0])#imagePyramid
pattern_idx = 0
pattern = _pattern[pattern_idx:]#初始指向256个点对的起始位置,
des=[]
if wta_k==2: #这里,仅仅计算wta_k=2的情况,具体可参考opencv库中的orb.cpp文件
for j in range(0,dsize):#本文中,dsize为32,即每个keypoint的描述符由32个字节组成
byte_v = 0
for nn in range(0,8):#计算每个bit位,其中pattern存放的是待比较的点对位置,0和1为一对,2和3为一对,...,具体参考orb.cpp
t0 ,t1= GET_VALUE(2*nn, pattern, a, b, imagePyramid, cy, cx), GET_VALUE(2*nn+1, pattern, a, b, imagePyramid, cy, cx)
bit_v = int(t0<t1)
byte_v += (bit_v<<nn)
des.append(byte_v) #得到一个byte
pattern_idx += 16 #计算8个bit,需要8对个点,所以索引加上8×2,为下一次计算做准备
pattern = _pattern[pattern_idx:]
descriptors.append(np.array(des))
else:
raise("only wta_k=2 supported here")
return descriptors
# ORB检测关键点并生成描述符接口函数 #
def my_orb_detectAndCompute(img_src,_mask=None,keypoints=None,useProvidedKeypoints=False):
HARRIS_BLOCK_SIZE = 9; #求取harris角点响应时的窗口的大小
halfPatchSize = np.int(patchSize / 2)
descPatchSize = np.int(np.ceil(halfPatchSize*np.sqrt(2.0))) #圆形区域半径
border =np.int( np.max( (edgeThreshold, descPatchSize, HARRIS_BLOCK_SIZE / 2) ) + 1 )#border取几个阈值参数的较大者
useOCL = False
image = img_src.copy()
if len(image.shape)==3:
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# 1. 构造图像金字塔,包括根据需要构造金字塔的层数,计算出每层金字塔图像的尺寸大小、建二维数组用以存放金字塔图像、构造金字塔等 #
nLevels = nlevels
layerScale=[]
layerInfo=[]#记录每一金子塔层图像的存放位置,N*[x,y,w,h]的数组
level_dy =(int) (image.shape[1] + border * 2) #该层图像的高度
level_ofs = np.array([0,0]) #Point(x,y),指示存放每一层图的起始点坐标
bufSize = np.array([ np.bitwise_and( (np.round(image.shape[1] / getScale(0, firstLevel, scaleFactor)) + border * 2 + 15).astype(int),-16)
,0] )#存放整个金字塔所占的空间,w,h,这里保证width为16的倍数;随着金字塔层级的增加,图像越来越小,所以整个金字塔的宽度取决于第一层
# 1.1 计算每一层金字塔图像的尺寸、实际占据空间尺寸、以及在二维数组中的存放位置,这只是在底层c中需要节省空间在这样处理
for level in range(0,nLevels): #计算每一金字塔层的参数
scale = getScale(level, firstLevel, scaleFactor);
layerScale.append(scale)
sz = np.array( [np.round(image.shape[1]/scale),np.round(image.shape[0]/scale)] ).astype(int) #获得该层的图像大小
wholeSize = np.array( [sz[0] + border * 2, sz[1] + border * 2]) #在上下左右加上boder,得到该层的实际占据的最终大小尺寸
if level_ofs[0] + wholeSize[0] > bufSize[0]: #如果当前层剩余的宽度不够存放新的层,则另起一层
level_ofs = np.array([0, level_ofs[1] + level_dy])#另起一层后,x坐标归0,y坐标在当前的基础上加上一层的高度
level_dy = wholeSize[1] #更新当前层的高度
linfo = np.array([level_ofs[0] + border, level_ofs[1] + border, sz[0], sz[1]]) #当前层图像的实际位置,x,y,width,height,但不是占据的空间位置
layerInfo.append(linfo) #保存每一层图像的实际位置,不含border部分
level_ofs[0] += wholeSize[0] #更新当前层起点坐标x,为存放下一层做准备
bufSize[1] = level_ofs[1] + level_dy #得到最终金字塔占据的高度
# 1.2 构造二维数组,用来存放金字塔 #
imagePyramid = np.zeros((bufSize[1],bufSize[0]) ).astype(np.uint8)
# 1.3 开始构造金字塔,使用的是resize函数,获取每一层
prevImg = image #初始值为原始图像
for level in range(0,nLevels):
linfo = layerInfo[level] #先获取当前层金字塔图像的位置[x,y,width,height],不含border
sz = np.array([linfo[2],linfo[3]]) #得到该层图像的尺寸w、h
wholeSize = np.array( [ sz[0] + border * 2, sz[1] + border * 2]) #加上border尺寸
wholeLinfo = np.array([ linfo[0] - border, linfo[1] - border, wholeSize[0], wholeSize[1] ])#当前层实际占据空间的位置
if level==firstLevel: #如果是第一层,则直接添加border、赋值
extImg = cv2.copyMakeBorder(image, border, border, border, border, cv2.BORDER_REFLECT_101)
imagePyramid[wholeLinfo[1]:wholeLinfo[1] + wholeLinfo[3],wholeLinfo[0]:wholeLinfo[0] + wholeLinfo[2]] = extImg.copy()
else:
currImg = cv2.resize(prevImg, tuple(sz), 0, 0, cv2.INTER_LINEAR_EXACT)#不含border部分
extImg = cv2.copyMakeBorder(currImg, border, border, border, border,cv2.BORDER_REFLECT_101 + cv2.BORDER_ISOLATED)#扩展border
imagePyramid[wholeLinfo[1]:wholeLinfo[1] + wholeLinfo[3],wholeLinfo[0]:wholeLinfo[0] + wholeLinfo[2]] = extImg.copy()
if (level > firstLevel):
prevImg = currImg.copy()
#python计算出的金字塔,与C++中计算出的有些许差距,每个像素点最大相差2个像素,经查,是在resize函数中,c++计算与python计算有差距
#为保持一致性,使用c++计算出的金字塔结果进行后续计算
imagePyramid = ( np.loadtxt('imagePyramid.txt') ).astype(np.uint8)
# 2. 开始计算关键点 #
keypoints = computeKeyPoints(imagePyramid, None, None, layerInfo, None, layerScale, keypoints, nfeatures, scaleFactor,
edgeThreshold, patchSize, scoreType, useOCL, fastThreshold)
# 3. 开始为每个关键点计算描述符 #
# 3.1 初始化生成描述符需要的相关参数 #
dsize = kBytes
nkeypoints =len(keypoints)
npoints = 512 #kBytes=32,即每个keypoint的描述符为32个bytes,共计32×8=256个bit位,即在pt周围,共计比较了256次,因而选择了256对位置,
# 共计512个点,每个点位置由x、y坐标组成,共计1024个数值,也就是bit_pattern_31数组元素的数量
bit_pattern_31 = get_bit_pattern_31() # 从txt文件中,读取出256对比较点位置
if (nkeypoints == 0):
return ([],[])
pattern = []#存放每个点位的x,y坐标
if (wta_k == 2):
for i in range(npoints):#共计256对比较点,即512个点,从bit_pattern_31数组中将每个点位按顺序提取出来
x,y = bit_pattern_31[2*i],bit_pattern_31[2*i+1]
pattern.append([x,y])
# 3.2 对于每层金字塔图像,进行高斯滤波 #
for level in range(0,nlevels):
x,y,w,h = layerInfo[level]
workingMat = imagePyramid[y:y+h,x:x+w]
workingMat = (workingMat).astype(np.float32) #先转换为float32,滤波后再转回uint8,这样可以使得计算结果与c++结果一致
workingMat = cv2.GaussianBlur(workingMat,(7,7),sigmaX=2,sigmaY=2,borderType=cv2.BORDER_REFLECT_101)
workingMat = ( np.round(workingMat) ).astype(np.uint8)
imagePyramid[y:y + h, x:x + w] = workingMat #将高斯滤波后的图像存到金字塔数组中
# 3.3 开始计算keypoint是的描述符 #
descriptors = computeOrbDescriptors(imagePyramid, layerInfo, layerScale, keypoints, pattern, dsize, wta_k)
#至此,keyponts和descriptors计算完毕,可算!
return keypoints,descriptors
6. 基于opencv实现
Opencv自带ORB,可以直接对关键点生成描述子。这里使用的opencv版本为3.4.11。
调用方式为:
orb = cv2.ORB_create()
kp2,des2 =orb.detectAndCompute(img_src,None)
主程序调用:
if __name__ == '__main__':
print("注意:python计算出的金字塔,与C++中计算出的有些许差距,每个像素点最大相差2个像素,经查,是在resize函数中,c++计算与python计算有差距,")
print("为验证关键点检测、描述符生成代码计算结果是否与opencv计算结果一致,在程序的第321行,使用了c++计算出的金字塔结果进行后续计算。")
print("请根据需要屏蔽此行!!!")
img_src = cv2.imread('susan_input1.png',cv2.IMREAD_GRAYSCALE)
# 1. 自行编写代码测试 #
kp1,des1 = my_orb_detectAndCompute(img_src, None, [])
# 按照response的大小,对kp1和des1排序,方便与opencv计算结果比较
res = np.zeros((len(kp1),))
for i in range(0,len(kp1)):
res[i] = kp1[i].response
index = np.argsort(res)[::-1]
kp1 = list(np.array(kp1)[index])
des1 = list(np.array(des1)[index])
# 2.调用opencv库实现 #
orb = cv2.ORB_create()
kp2,des2 =orb.detectAndCompute(img_src,None)
# 按照response的大小,对kp2和des2排序,方便与自行编写代码的计算结果比较
res = np.zeros((len(kp2),))
for i in range(0,len(kp2)):
res[i] = kp2[i].response
index = np.argsort(res)[::-1]
kp2 = list(np.array(kp2)[index])
des2 = list(np.array(des2)[index])
# 3.两种实现方法的误差比较 #
if len(kp1) != len(kp2):
print("not equal")
else:
N = len(kp1)
err = np.zeros((N,6))
for i in range(0,N):
L ,R = kp1[i],kp2[i]
err[i,0] = L.pt[0] - R.pt[0]
err[i,1] = L.pt[1] - R.pt[1]
err[i, 2] = L.size - R.size
err[i, 3] = L.angle - R.angle
err[i, 4] = L.response - R.response
err[i, 5] = L.octave - R.octave
print("kps err:",np.max(abs(err)))
if len(des1) != len(des2):
print("not equal")
else:
N = len(des1)
err = np.zeros((N,))
for i in range(0,N):
L ,R = des1[i],des2[i]
err[i] = np.max(abs(L-R))
print("des err:",np.max(abs(err)))
print('end')
注意:在运行程序过程中发现,在构造图像金字塔时,自行编写代码构造的金字塔与C++中opencv库构造的金字塔存在偏差,在像素上最大相差2(进一步发现,是在调用resize库函数时,存在误差,同样的输入,c++库和python计算的结果不同),这个误差导致后续计算keypoints、descriptors偏差,影响后续的对比。为此,为验证后续代码的正确性,将c++中计算出的图像金字塔导出为txt,再由python导入,进行后续计算。
结果表明,自行编写代码的结果与opencv库实现的结果误差为:
kps err: 4.57763671875e-05
des err: 0.0
7、python源码下载
Python程序源码下载地址
https://download.csdn.net/download/xiaohuolong1827/86242761
8、其它(完结)
与黄宁然共事过,却不曾同过窗。所以,浅浅读过黄宁然学生时代曾读的算法,就算是同过窗了。
7月12日,正在整理这篇博文时,黄宁然送来了一本书,《中国最美的100个地方》。所以,看你看过的算法系列,从黄宁然曾读的书开始,到收到这本新书为止。
其实,在3月份时就在思考,每一段经历都应该有所收获。与HNR共事多年,我想HNR教会的是:用心去感受这一花一草,一亭一阁,山川河海值得你去看一看。也正应了这本书。
9、后续
接下来,可能就是看,与HNR,谁先w了。愿顺利w。
*注:看你看过的算法系列博文,仅代表笔者在2022.03.01~2022.05.31期间的感悟。














 7640
7640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









