






大家好,今天我将向大家介绍如何使用免费的Stable Diffusion实现类似于Photoshop的创成式填充功能。
Photoshop的创成式填充功能非常强大。比如,在一张风景照的左右两侧,利用AI自动填充新的内容。

只需要选中要填充的区域,哪怕不写提示词,Photoshop也能够很好地进行扩图。

然而,这个功能是收费的。
今天,我们将探讨如何使用免费的Stable Diffusion实现类似的效果。
这张16:9的图片是我用Midjourney生成的。

通过WebUI,我们可以分别向上和向下扩展图像内容。扩展的方向和范围完全由我们决定,非常灵活,而且填充的内容和原图非常契合。

依赖大模型的实现
用StableDiffusion实现这个效果非常依赖Checkpoint。在这部分,我们将通过一个消除画面中人物的例子,来说明Checkpoint在StableDiffusion中的重要性。
步骤说明
1️⃣ 导入图片 :将我们之前的图片导入到WebUI的局部重绘功能中。
2️⃣ 涂抹蒙版 :将图片中的女子涂抹成一个蒙版。

3️⃣ 调整蒙版模糊度 :为了避免重绘后的边缘产生接缝,将蒙版的模糊度调高一些。
4️⃣ 勾选Soft inpainting :勾选“Soft inpainting”选项,以进一步降低接缝的概率。
5️⃣ 保持尺寸一致 :确保重绘后的图像尺寸与原图一致。
6️⃣ 调整降噪强度
:将降噪强度拉到最大。

7️⃣ 选择模型 :选择一个SDXL的模型,这里我们选择的是“juggernautXL”。等待模型加载完成。
8️⃣ 添加提示词 :写一些提示词,以更精准地控制重绘区域的内容。

9️⃣ 生成图片 :运行生成操作。

模型效果对比
初次生成的图片效果可能不理想,我们可以尝试更换Checkpoint。
1️⃣更换Checkpoint :选择另一个Checkpoint,比如“juggerxl
Inpaint”。这是一个专门用于局部重绘的模型。下载地址是:pan.baidu.com/s/1Vtb8uuuW… 。
2️⃣保持其他参数不变 :为了对比不同模型的效果,保持其他参数不变,再次生成一张图片。

观察效果
第二次生成的图片效果明显比第一次好很多。通过这个对比,我们可以看到选择适合的Checkpoint对于获得理想的重绘效果是多么重要。有了适合的Checkpoint后,我们可以正式开始用它进行扩图。
简单创成式填充案例
我们将换一张新图,内容是一位美女坐在汽车引擎盖上,并将其扩展成正方形的图像。

设置初始参数
1️⃣ 选择缩放模式 :在WebUI中选择"缩放和填充"模式。
2️⃣ 调整高度 :将高度设置为1456,以生成正方形的图像。当然,你也可以选择其他尺寸。

3️⃣ 修改提示词 :由于我们换了一张新图,提示词也需要修改为:“年轻女子,休闲装,坐在老爷车的车盖上,秋天湖边的树木”。
4️⃣ 生成图片 :运行生成操作,查看效果。

初次生成的图片可能只是简单的拉伸,并没有填充实质性的内容。我们需要进一步操作。
再次进行局部重绘
1️⃣拖入局部重绘 :将这张图片拖到局部重绘功能中。如果图片上传卡住,关闭等待上传的图像,然后重新拖入。
2️⃣涂抹重绘区域 :涂抹图片上部需要重绘的区域,再次生成一张图片。

处理下半部分
接下来,我们处理下半部分:
1️⃣ 拖回局部重绘 :将生成的图再次拖回局部重绘。
2️⃣ 涂抹下半部分 :涂抹需要重绘的下半部分,再次生成图片。

处理细节问题
虽然扩充这张图有一定挑战性,如汽车头部复杂的构造和人类的肢体,这些对于AI来说不太好处理,但通过多次处理,我们可以逐步解决这些小问题。
最终版本的局部重绘效果大致完成,不过后视镜部分可能仍存在问题。可以使用Photoshop将后视镜P上去,再进行局部重绘,这样后视镜的效果会更好。这个步骤就不在此演示了。

复杂创成式填充案例
刚才这个案例,我们扩充的上部区域和下部区域的高度是相同的。Stable Diffusion里面没有自己设置高度的选项。

但我视频开头提到的案例,我们扩充的上部区域和下部区域的高度是不同的。

这里,我们将详细演示如何处理扩充上部和下部区域高度不同的情况。
扩充不同高度的步骤
1️⃣ 导入图片 :回到WebUI,把需要处理的图片放进来。
2️⃣ 修改提示词 :描述新图片的内容,调整提示词以反映图像的新内容。这里提示词可以是:“修车女子,车库场景,背景是工具和设备”。
3️⃣ 设置缩放模式 :选择"缩放和填充",图片尺寸与之前的设置相同,都是正方形的。
4️⃣ 生成初始图片 :运行生成操作,得到初始图片,并保存下来。

Photoshop处理图片
1️⃣打开Photoshop :新建一个文件,尺寸与WebUI中设置的一致。

2️⃣导入初始图片 :将保存的初始图片拖到这个空白图层上面。为了让下面填充的区域高一些,将图层向上移动。
3️⃣合并图层 :按"Ctrl+E"合并图层。
4️⃣框选白色区域 :框选白色填充区域。
5️⃣内容识别填充 :按"Shift+F5"打开填充对话框,选择“内容识别填充”。

6️⃣导出处理好的图片 :将处理好的图片导出。

WebUI进一步重绘
1️⃣重新导入图片 :将处理好的图片再放到WebUI中。
2️⃣重绘上部和下部区域 :分别对上部区域和下部区域进行重绘。
3️⃣再次重绘细节 :将效果较好的图片拖到局部重绘中,进一步完善细节。
经过多次尝试和细节调整,最终的效果如下图所示。虽然过程中遇到了一些挑战,但通过不断调整提示词和重绘区域,我们成功地实现了创成式填充,效果还是相当不错的。

总结
以上就是将修车女子图片进行创成式填充的详细步骤。通过使用Stable
Diffusion结合Photoshop的内容识别填充,我们可以实现复杂的图像扩展和重绘。
另外,给大家准备了一份SD学习资料,文末可以免费领取
但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

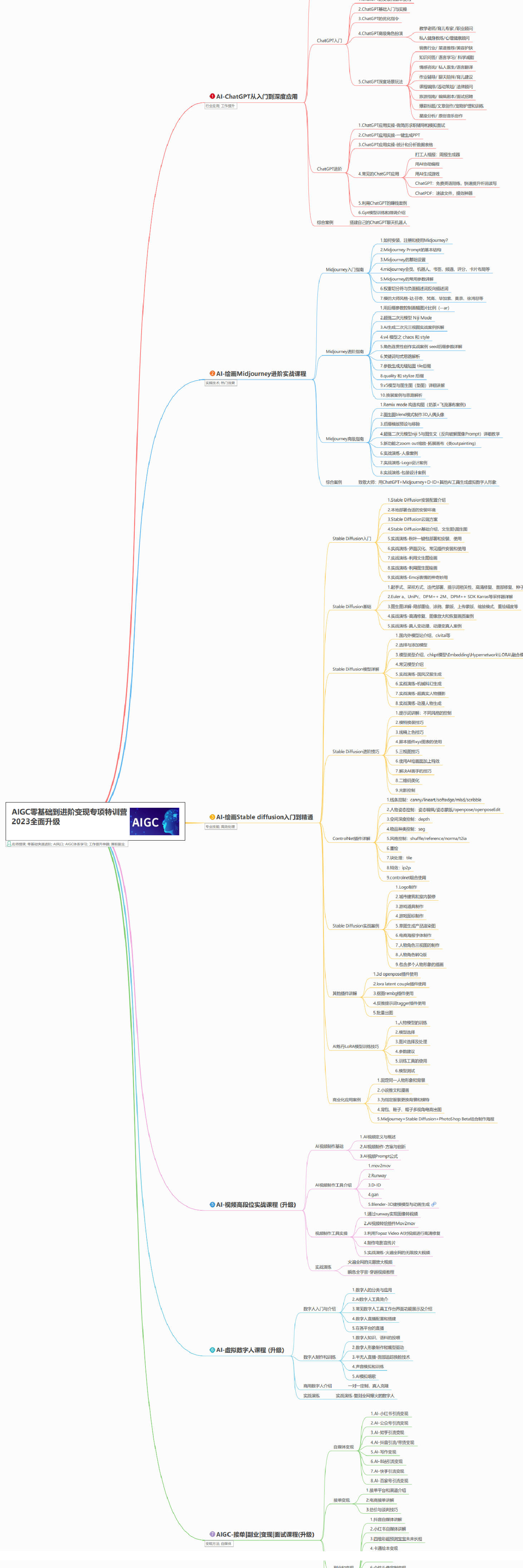
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









