







Cortex-A510——Cache
小狼@http://blog.csdn.net/xiaolangyangyang
1、M7 Cache基本参数
ARM Cortex-A510系列Cache参数如下:
Cache Level:L1/L2/L3/SLC
L1 ICache/DCache
size:64K、32K
cache-line:4B、64B、512B
L2 Cache
size:1M、512K、256K
cache-line:16B
L3 Cache
size:16M
cache-line:128B
SLC Cache
size:4M * 4
cache-line:64B
2、Cortex-A510 Cache组织结构
以cache-size为32k,cache-line为32Byte为例:
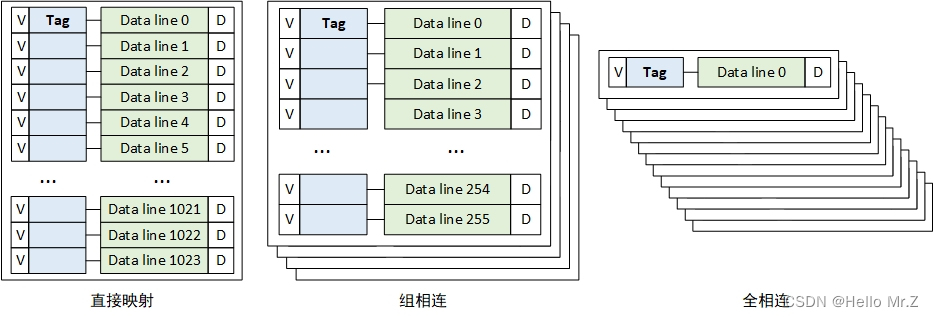
- 组相连(常用结构):4-way,256-set
- 直接映射:相当于1-way,1024-set的组相连
- 全相连:相当于1024-way,1-set的组相连
3、组相连
如果一个数据可以放在n个line,则称这个Cache是n路组相连的Cache(n-wayset-associativeCache),如下图所示为4-way,4-set的Cache。
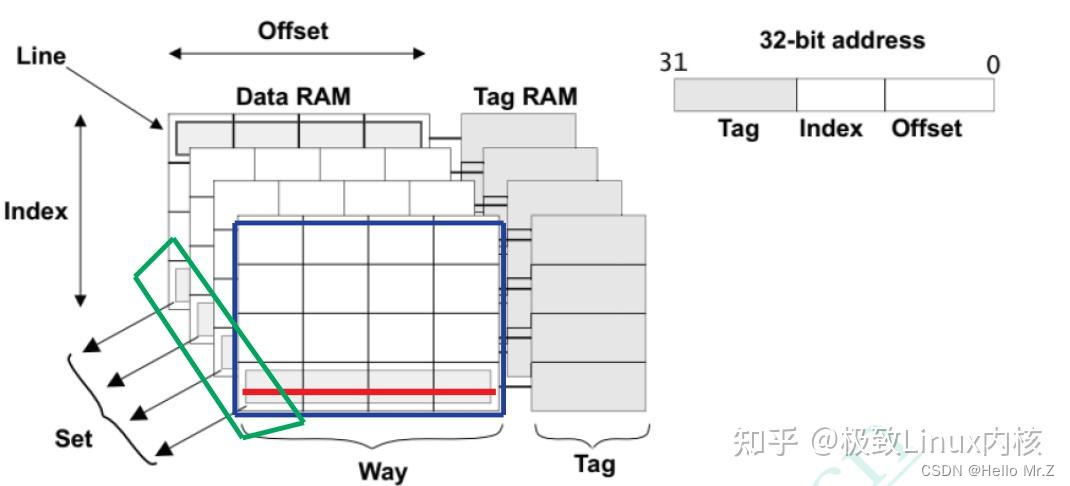
组相连结构图
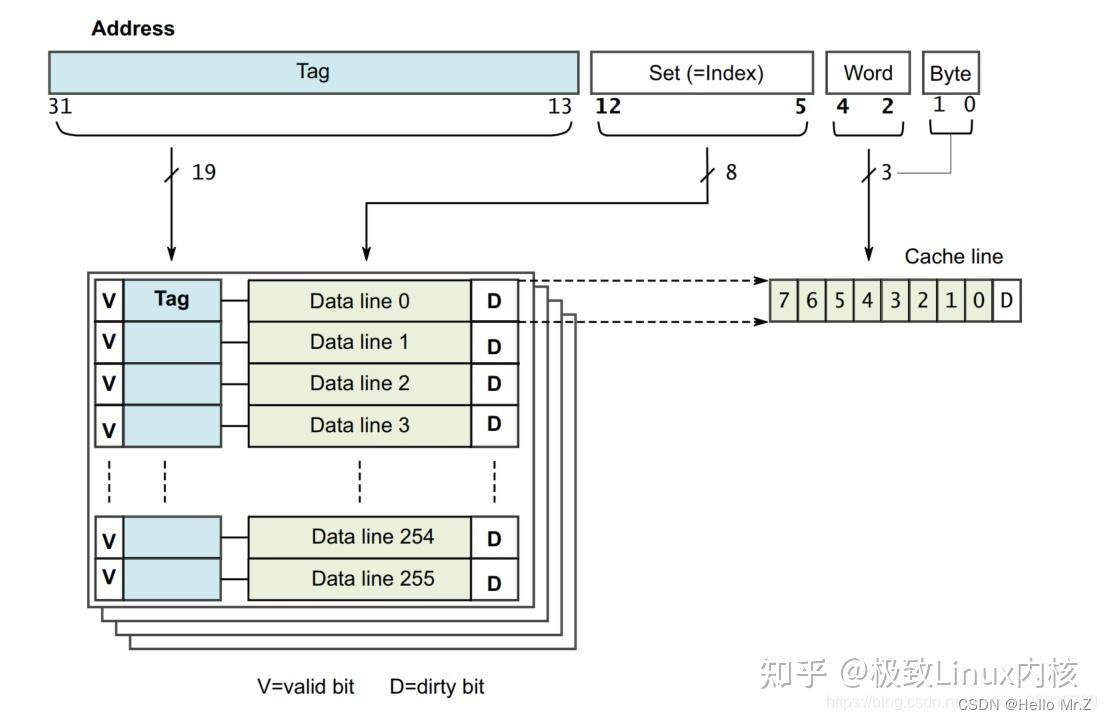
组相连映射图
- offset:确定cache-line中数据位置,offset为图中Word+Byte;
- set:确定way中cache-line位置,即哪个组,如果数据被缓存,则V标志为1;
- tag:确定cache中way的位置,如果数据被缓存,tag中保存有地址信息,与处理器地址进行比对;
- V:cache-line有效标记;
- D:脏数据标记。
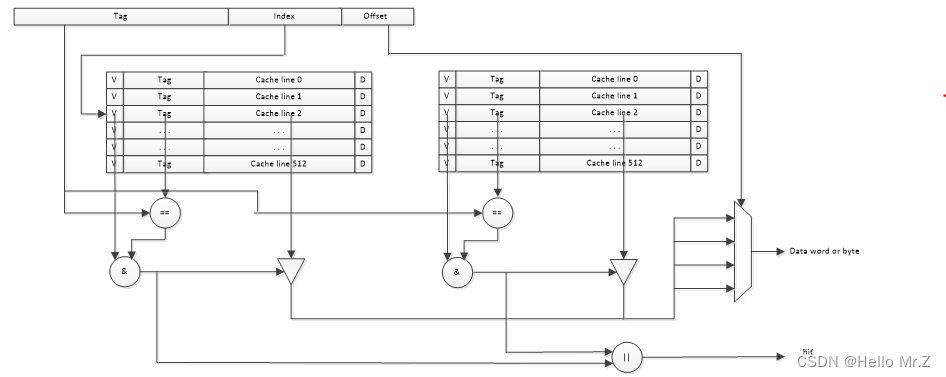
组相连映射硬件逻辑图
4、VIVT/VIPT/PIPT
VIVT(Virtual Index Virtual Tag):使用虚拟地址Index域和虚拟地址Tag域
多个VA可能映射到同一PA,导致多个cache line组(VA不同,index域不同,查找到的cache 组则不同)映射到同一物理地址,这种现象叫做cache alias(高速缓存别名)。一旦一个VA到PA的映射关系改变,cache内容将会写回物理内存。此时,由于物理内存内容的变化需要同步到cache,就需要clean和invalidate(这两个操作结合起来就叫做flush)其余同名cache line,导致系统性能下降。
VIPT(Virtual Index Physical Tag):使用虚拟地址Index域和物理地址Tag域
如果index域位于地址的bit0~bit11(因为linux kernel以4KB(12bit位宽)大小为页面进行物理内存管理),就不会引起cache alias,否则还是会引起该问题。因为对于一个页面来说,虚拟地址和物理地址的低12bit是完全一样的,如果index域位于bit0~bit11,此时VIPT等价于PIPT。
PIPT(Physical Index Physical Tag):使用物理地址Index域和物理地址Tag域
就不会存在cache alias问题,但是结构更复杂。ARM Cortex-A系列处理器使用的是PIPT方式。
5、Cache硬件替换策略
常用策略有:PLRU、NRU、FIFO、Round-Robin
6、Cache一致性
MESI协议:
- M:这行数据有效,数据已被修改,和内存中的数据不一致,数据只存在于该高速缓存中
- E:这行数据有效,数据和内存中数据一致,数据只存在于该高速缓存中
- S:这行数据有效,数据和内存中数据一致,多个高速缓存有这行数据的副本
- I:这行数据无效
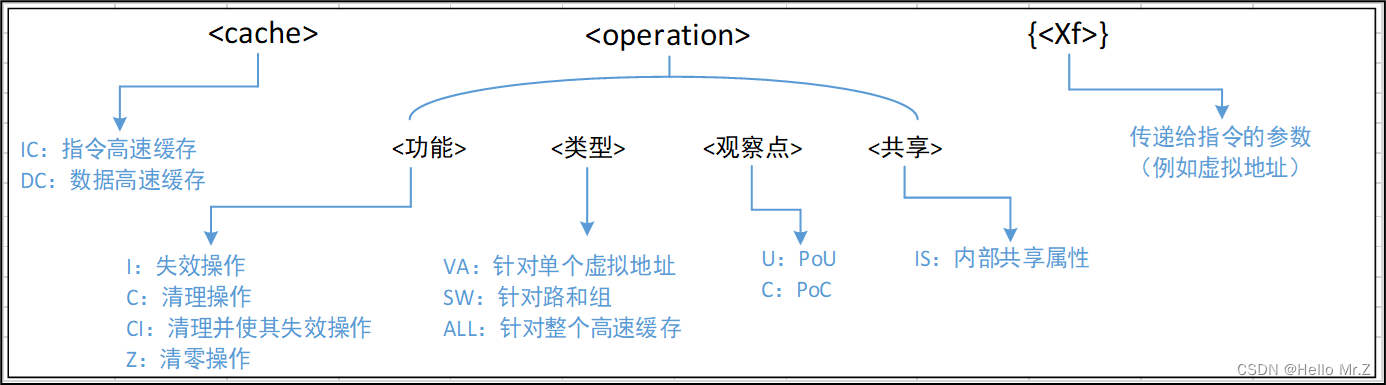
7、Cache操作指令
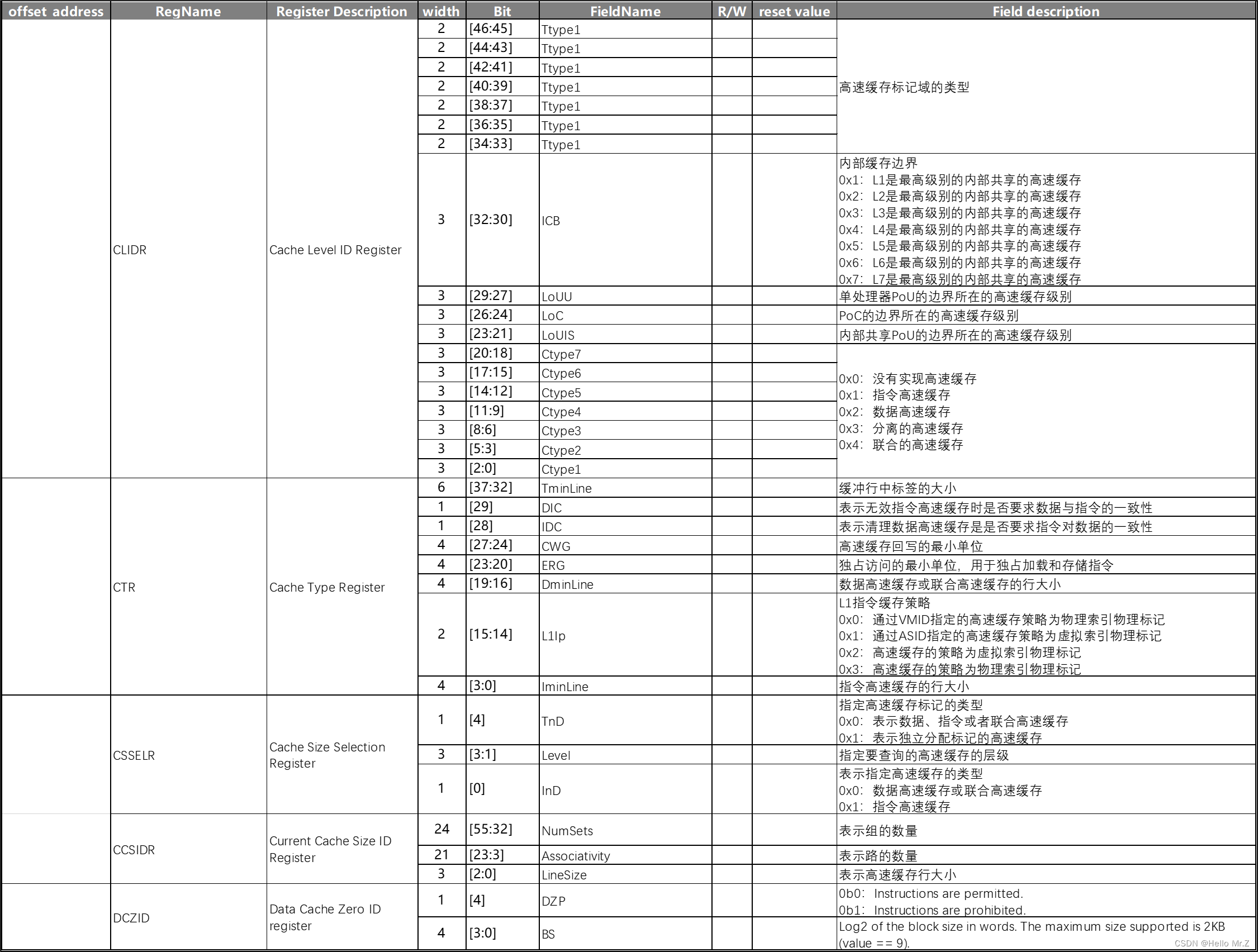
8、Cache寄存器
9、Cache-Tag格式及获取
可以向Data Cache Tag Read Operation Register写入way、set,然后读取Data Register 1和Data Register 0寄存器得到Cache Tag信息
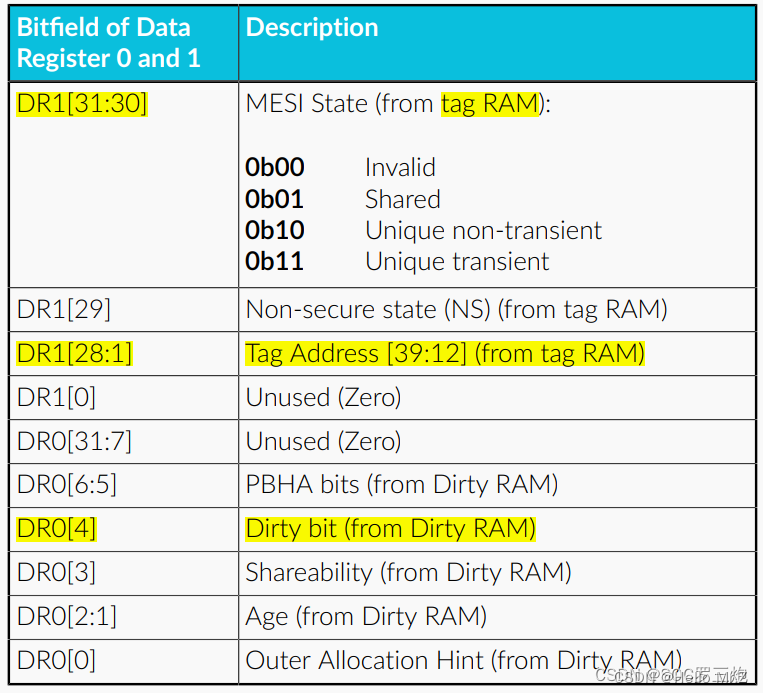
cache-tag格式
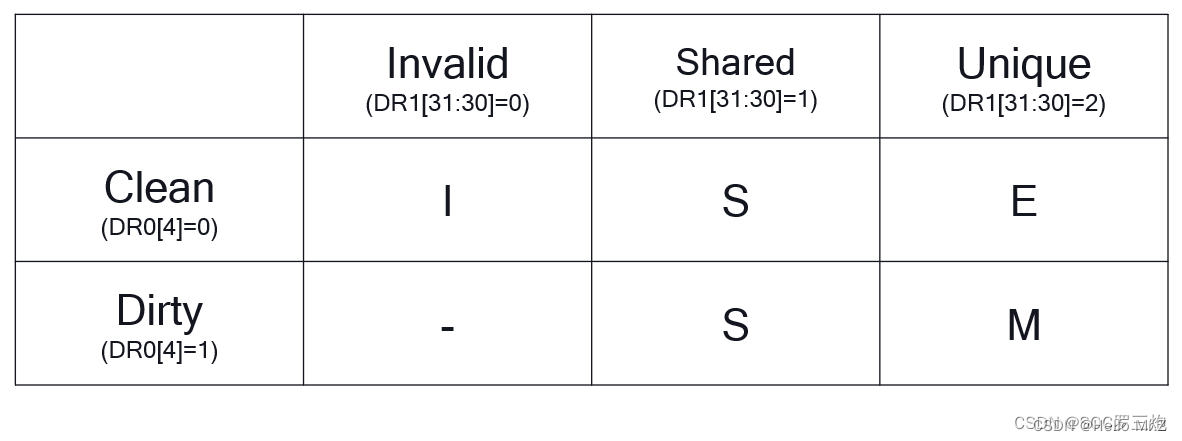
DR0[4]和DR1[31:30]解析出MESI
10、提高Cache命中率
- 优化数据访问模式,是得数据的访问更加局部化、减少Cache Miss的次数;
- 合理配置Cache的大小和映射方式,以满足特定应用程序的需求;
- 使用高效的替换算法,如LRU(Least Resently Used),以最大程度地保留对最近访问数据的缓存;
- 避免频繁的写入操作,尽可能地延迟写操作以提高写入命中率。
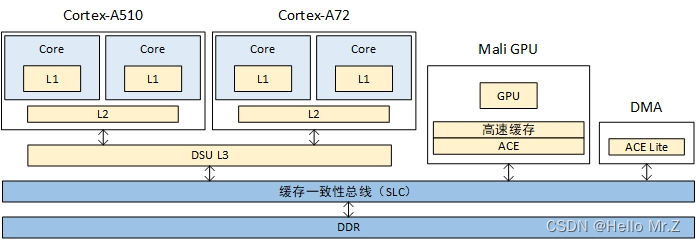
11、PoU/PoC与Inner/Outer Shareable
PoU/PoC:PoU/PoC定义了指令和命令的所能抵达的缓存或内存;
Inner/Outer Shareable:在到达了指定地点后,Inner/Outer Shareable定义了它们被广播的范围,属于MESI协议范畴。
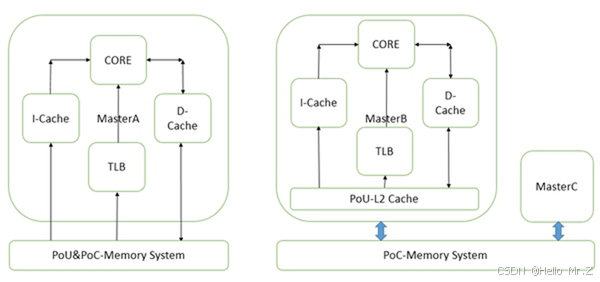
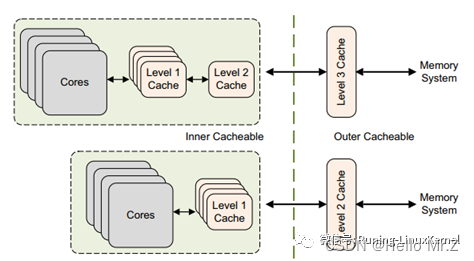
PoU是指,对于某一个核Master,附属于它的指令,数据缓存和TLB,如果在某一点上,它们能看到一致的内容,那么这个点就是PoU。如上图右侧,MasterB包含了指令,数据缓存和TLB,还有二级缓存。指令,数据缓存和TLB的数据交换都建立在二级缓存,此时二级缓存就成了PoU。而对于上图左侧的MasterA,由于没有二级缓存,指令,数据缓存和TLB的数据交换都建立在内存上,所以内存成了PoU。
PoC是指,对于系统中所有Master(注意是所有的,而不是某个核),如果存在某个点,它们的指令,数据缓存和TLB能看到同一个源,那么这个点就是PoC。如上图右侧,二级缓存此时不能作为PoC,因为MasterB在它的范围之外,直接访问内存。所以此时内存是PoC。在左图,由于只有一个Master,所以内存是PoC。
再进一步,如果我们把右图的内存换成三级缓存,把内存接在三级缓存后面,那PoC就变成了三级缓存。
有了这两个定义,我们就可以指定缓存操作和读写指令到底发到哪个范围。比如在下图的系统上,有两组A15,每组四个核,组内含二级缓存。系统的PoC在内存,而A15的PoU分别在它们自己组内的二级缓存上。在某个A15上执行Clean清指令缓存,范围指定PoU。显然,所有四个A15的一级指令缓存都会被清掉(Inner Shareable)。那么其他的各个Master是不是受影响?那就要用到Inner/Outer/Non Shareable。
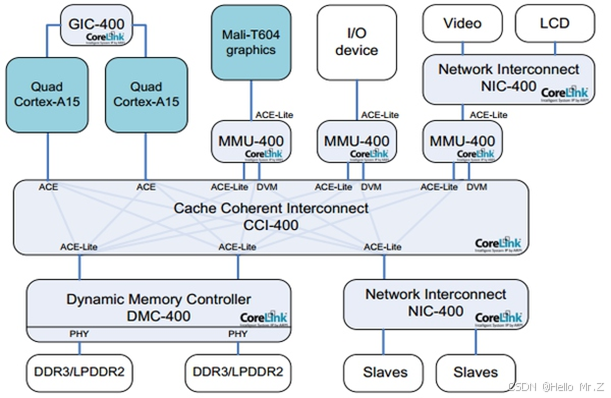
Shareable的很容易理解,就是某个地址的可能被别人使用。我们在定义某个页属性的时候会给出。Non-Shareable就是只有自己使用。当然,定义成Non-Shareable不表示别人不可以用。某个地址A如果在核1上映射成Shareable,核2映射成Non-Shareable,并且两个核通过CCI400相连。那么核1在访问A的时候,总线会去监听核2,而核2访问A的时候,总线直接访问内存,不监听核1。显然这种做法是错误的。
对于Inner和Outer Shareable,有个简单的的理解,就是认为他们都是一个东西。在最近的ARM A系列处理器上上,配置处理器RTL的时候,会选择是不是把inner的传输送到ACE口上。当存在多个处理器簇或者需要双向一致性的GPU时,就需要设成送到ACE端口。这样,内部的操作,无论inner shareable还是outershareable,都会经由CCI广播到别的ACE口上。
说了这么多概念,你可能会想这有什么用处?回到上文的Clean指令,PoU使得四个A7的指令缓存中对应的行都被清掉。由于是指令缓存操作,InnerShareable属性使得这个操作被扩散到总线。而CCI400总线会把这个操作广播到所有可能接受的口上。ACE口首当其冲,所以四个A15也会清它们对应的指令缓存行。对于Mali和DMA控制器,他们是ACE-Lite,本不必清。但是请注意它们还连了DVM接口,专门负责收发缓存维护指令,所以它们的对应指令缓存行也会被清。不过事实上,它们没有对应的指令缓存,所以只是接受请求,并没有任何动作。
你可能又会想,我们要这么复杂的定义有什么用?用处是,精确定义缓存维护和读写指令的范围。如果我们改变一下,总线不支持Inner/Outer Shareable的广播,那么就只有A7处理器组会清缓存行。显然这么做在逻辑上不对,因为A7/A15可能运行同一行代码。并且,我们之前提到过,如果把读写属性设成Non-Shareable,那么总线就不会去监听其他主,减少访问延迟,这样可以非常灵活的提高性能。
再回到前面的问题,刷某行缓存的时候,怎么知道数据是否最终写到了内存中?对不起,非常抱歉,还是没法知道。你只能做到把范围设成PoC。如果PoC是三级缓存,那么最终刷到三级缓存,如果是内存,那就刷到内存。不过这在逻辑上没有错,按照定义,所有Master如果都在三级缓存统一数据的话,那就不必刷到内存了。
再来看看Inner/Outer Cacheable,这个就简单了,仅仅是一个缓存的前后界定。一级缓存一定是InnerCacheable的,而最外层的缓存,比如三级,可能是Outer Cacheable,也可能是Inner Cacheable。他们的用处在于,在定义内存页属性的时候,可以在不同层的缓存上有不同的处理策略。
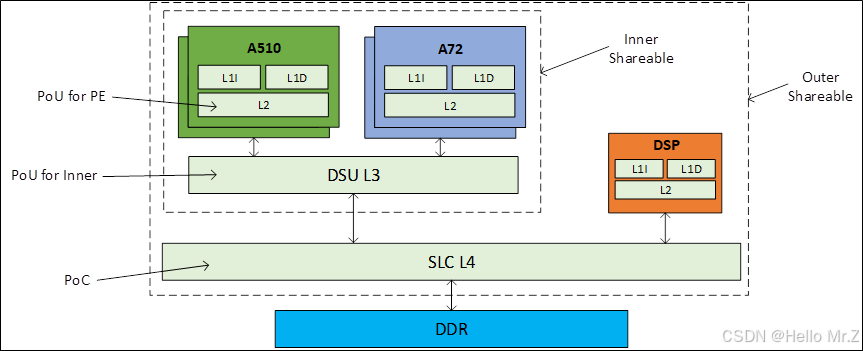
如果内存为Inner Shareable,A510或A72访问地址,硬件会实现L3及以上L1/L2(包括A510和A72)的cache一致性,访问的数据会更新到L3,不会更新到L4;
如果内存为Outer Shareable,A510或A72访问地址,硬件会实现L4及以上L1/L2/L3(包括A510、A72和DSP)的cache一致性,访问的数据会更新到L4;
PoU for Inner角度去clean缓存,数据会更新到L4;
PoC角度去clean缓存,数据会更新到DDR。
12、疑问
1、Cache的内部组织架构是怎么样的?能否画出一个cache的layout图?什么是set,way?
2、直接映射,全关联和组相联之间有什么区别?优缺点是啥?
3、重名问题是怎么发生的?
4、同名问题是怎么发生的?
5、VIPT会不会发生重名问题?
6、什么是inner shareability 和outer shareability?怎么区分?
只有normal memory的内存才能设置inner 和outer shareability,device memory不能设置shareability,不同的SOC设计有不同的区分方法,如下图所示
7、什么是PoU?什么是PoC?
PoU确保PE(执行cache指令的master)的I-cache、D-cache以及MMU(TLB)能够看到相同的副本,即cluster内所有cache同步;
PoC确保所有可以访问内存的观察者(gpu、dma等)都能看到相同的副本,即系统所有cache同步。
8、什么是cache一致性?业界解决cache一致性都有哪些方法?
9、MESI状态转换图,我看不懂。
10、什么cache伪共享?怎么发生的,如何避免?
11、DMA和cache为啥会有cache一致性问题?
12、网卡通过DMA收数据和发数据,应该怎么操作cache?
13、对于self-modifying code,怎么保证data cache和指令cache的一致性问题?
Cache知识记录
Arm64 Cache
Linux内存管理:ARM64体系结构与编程之cache(3):cache一致性协议(MESI、MOESI)、cache伪共享
ARM64体系结构与编程之cache必修课
AArch64指令 -- cache维护指令
ARM SoC漫谈
armv8 cacheable/shareable
Cache的相关知识(二)
Neoverse N2和CMN-700系统的PoC点在哪里?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









