







目录
引入
Hive是互联数据仓库中使用最频繁的工具,做为仓库的技术人员,有很大必要去深入了解它,并以认真的态度去对待工作中遇到的每个问题,每个知识点,由点及面,让我们的技术更扎实,也让我们更有底气~~
Hive版本:hive-1.2.1
该bug对应的jira:
https://issues.apache.org/jira/browse/HIVE-10996
具体原因:hive-1.2.1 逻辑执行计划优化过程中优化掉了一个SelectOperator操作符,导致数据错位
在一次为业务方取数的时候,发现查出的数据与自己想象中的不一致,经过各种检查发现sql的逻辑并没有问题,查看执行计划,也没发现明显的问题。以自己对数据的了解,再加上对数据反复的考究,发现用这样的一个正确的sql,出的结果确实是不正确的……
当时业务紧急,改用了其它方式出数,后来,同事也遇到同样的问题,细细思考,打算一探究竟
1、场景复现
当时取数的逻辑过于复杂,我们用一些简单的测试数据来复现问题
1.1、测试数据准备
测试数据准备

为了更清晰的看明白结果,我们建立的tmp_test_a和tmp_test_b这两张表的数据是完全一样的,并且都只有一条数据
1.2、测试sql
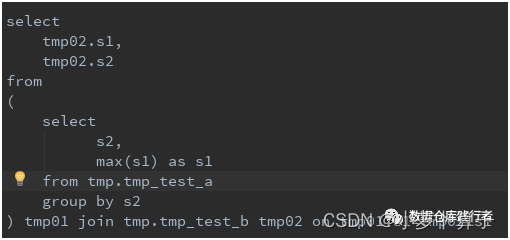
所以期待的结果:

然而hive给我们的结果:
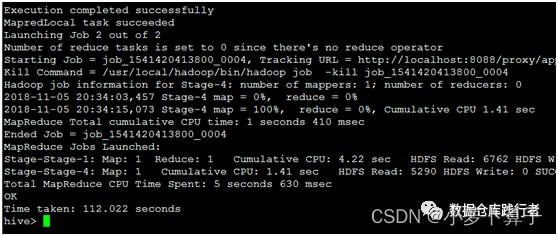
为毛?Why?这是个很简单的关联,我们很明显能看到结果不正确。但如果在一个非常复杂的并且我们又对数据不是很了解的业务环境下,又写了一个非常复杂的sql,正好用到了类似这样的逻辑,出的数据岂不是误导了大家?
2、追踪原因
这一块想要完全理解弄明白,必须要对hive的编译模块以及hive的serde模块有了解。经过一段时间的研究,我对hive的编译过程有了一些自己的见解,在探索的过程中也写了挺多的案例来验证里面的每一步过程,后面会坚持写hive编译模块及serde模块系列的文章,把自己学习到的东西分享出来。但这次文章中只会详细描述该bug作案的整个过程。
2.1脑补一下hive sql基本编译流程
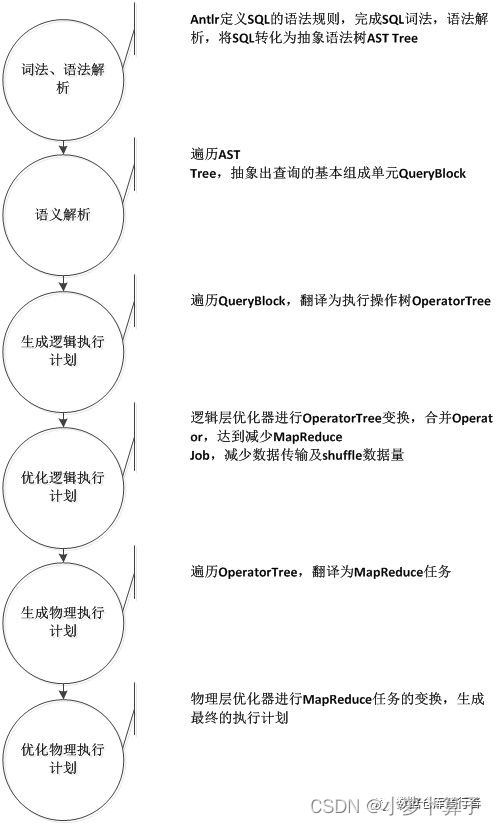
我们写的每一个sql,都会经过以上层层变换,最后变成mapreduce可以读懂的执行计划,执行计算返回结果。最后的结果是否正确就跟上面每一步都息息相关。
2.2追踪sql的逻辑执行计划
这次的问题就产生在第4步【优化逻辑执行计划】,【优化逻辑执行计划】是基于已经生成的【逻辑执行计划】来进行的。【生成逻辑执行计划】就是【生成逻辑操作树OperatorTree】
下面我画出了这次测试sql生成的OperatorTree,以及OperatorTree与sql中子查询的对应关系
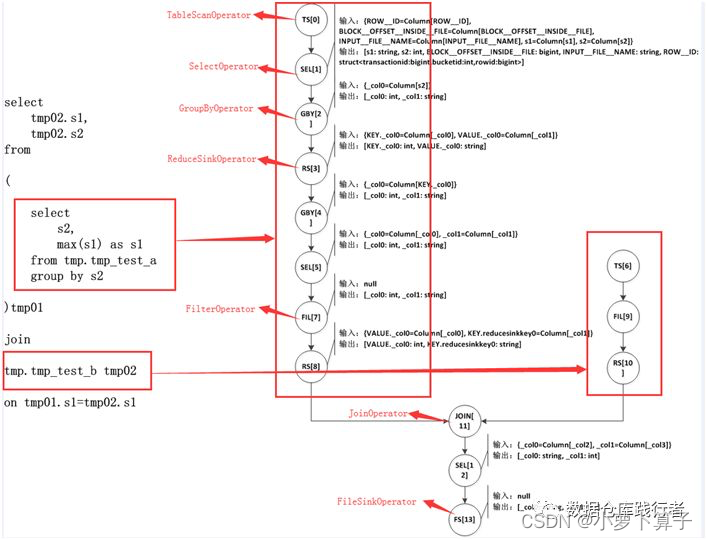
我们知道OperatorTree是由一系列逻辑操作符Operator构成的。可以把OperatorTree比做一棵树,那么Operator就是树的叶子。
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。而Operator,会在Map阶段或者Reduce阶段完成单一特定的操作。
上图整个右侧就是一棵OperatorTree,这个OperatorTree中有TS[0],SEL[1],GBY[2]等Operator按照先后顺序组成。
在图中:
- TS-> TableScanOperator:从MapReduce框架的Map接口原始输入表的数据,控制扫描表的数据行数,标记是从原表中取数据;
- SEL->SelectOperator:完成选择字段(列裁剪)的操作;
- JOIN->JoinOperator:完成Join操;
- FIL->FilterOperator:完成过滤操作;
- RS->ReduceSinkOperator:将Map端的字段组合序列化为ReduceKey/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束;
- GBY->GroupByOperator:完成groupby操作;
- FS->FileSinkOperator:将最终的结果数据写入文件;
Operator在Map Reduce阶段之间的数据传递是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。比如:TS[0]处理完会传给SEL[1],SEL[1]之后,再将数据传递给GBY[2]…
上图是该sql生成的最原始的OperatorTree,为了提高效率,hive会对该OperatorTree进行一系列的优化
2.3 逻辑执行计划优化
Optimizer.java是hive逻辑执行计划优化的主类
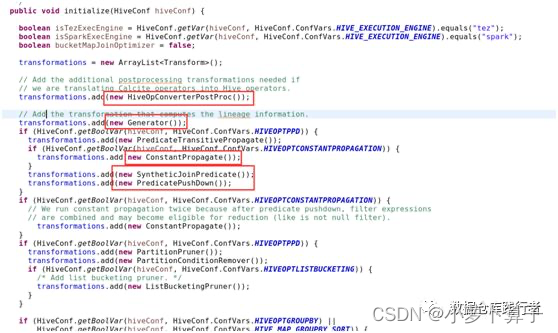
从Optimizer.java的initialize()方法中,我们可以看到,该初始化方法已经提前放入了各种优化器。
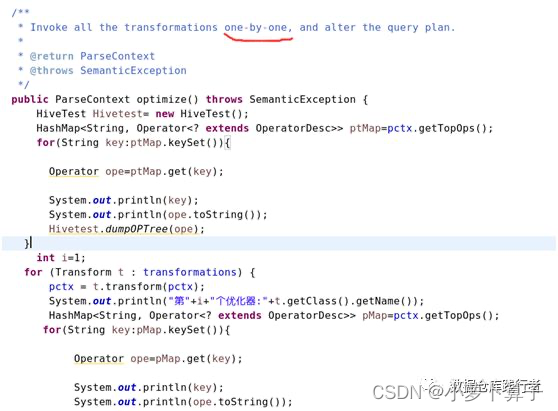
Optimizer.java的optimize()方法是执行优化的过程,能够看到优化的方案,就是一个一个优化器挨着调用一遍(当然,如果提前设参数,要求不走某个优化器,就会直接跳过),判断是不是符合优化条件,如果符合,就进行优化。
用最笨的方法打印了一下所有优化的器:
- 第1个优化器:
org.apache.hadoop.hive.ql.optimizer.calcite.translator.HiveOpConverterPostProc - 第2个优化器:
org.apache.hadoop.hive.ql.optimizer.lineage.Generator - 第3个优化器:
org.apache.hadoop.hive.ql.ppd.PredicateTransitivePropagate - 第4个优化器:
org.apache.hadoop.hive.ql.optimizer.ConstantPropagate - 第5个优化器:
org.apache.hadoop.hive.ql.ppd.SyntheticJoinPredicate - 第6个优化器:
org.apache.hadoop.hive.ql.ppd.PredicatePushDown - 第7个优化器:
org.apache.hadoop.hive.ql.optimizer.ConstantPropagate - 第8个优化器:
org.apache.hadoop.hive.ql.optimizer.ppr.PartitionPruner - 第9个优化器:
org.apache.hadoop.hive.ql.optimizer.pcr.PartitionConditionRemover - 第10个优化器:
org.apache.hadoop.hive.ql.optimizer.GroupByOptimizer - 第11个优化器:
org.apache.hadoop.hive.ql.optimizer.ColumnPruner - 第12个优化器:
org.apache.hadoop.hive.ql.optimizer.SamplePruner - 第13个优化器:
org.apache.hadoop.hive.ql.optimizer.MapJoinProcessor - 第14个优化器:
org.apache.hadoop.hive.ql.optimizer.BucketingSortingReduceSinkOptimizer - 第15个优化器:
org.apache.hadoop.hive.ql.optimizer.unionproc.UnionProcessor - 第16个优化器:
org.apache.hadoop.hive.ql.optimizer.JoinReorder - 第17个优化器:
org.apache.hadoop.hive.ql.optimizer.correlation.ReduceSinkDeDuplication - 第18个优化器:
org.apache.hadoop.hive.ql.optimizer.NonBlockingOpDeDupProc - 第19个优化器:
org.apache.hadoop.hive.ql.optimizer.IdentityProjectRemover - 第20个优化器:
org.apache.hadoop.hive.ql.optimizer.SimpleFetchOptimizer
总共有20个优化器,但这次的sql中,只用到了三个,分别是:
第6个优化器:PredicatePushDown 谓词前置
第11个优化器:ColumnPruner 字段剪枝
第19个优化器:IdentityProjectRemover 相同属性移除(我也不知道该怎么翻译了)
下面画出了OperatorTree的优化过程:
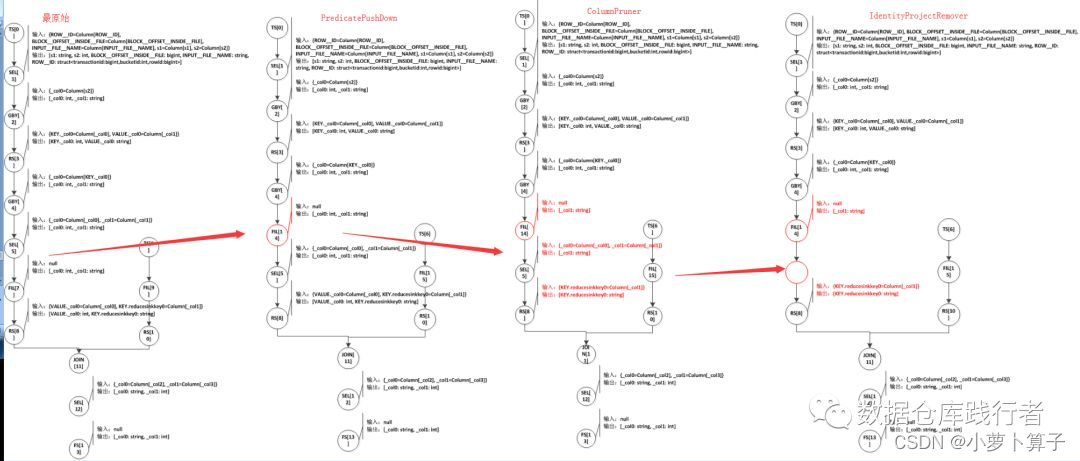
- PredicatePushDown:把FIL[7]提到SEL[5]之前,可以提前过滤不需要的数据,减少数据传输
- ColumnPruner:把FIL[14]和SEL[5]输出的字段从两个减为一个,即:输出[_col0:int,col1:string]–>输出[_col1:string] 这一块是因为我们整体的sql最后要取的字段并未用到 tmp_test_a.s2字段,优化器判断后,会认为这个是多余,给自动去掉,最终目的也是为了减少数据传输
- IdentityProjectRemover:去掉了SEL[5]这个操作符。为什么会去掉呢?因为这个优化通过比较前后Operator的输出字段,如果输出完全一样(字段及字段的类型)的话,它就会认为没必要再进行数据传输,而FIL[14]和SEL[5]完全一样,就把SEL[5]给去掉了
经过以上的优化,生成了最终的OperatorTree,从整体流程来看,这样的优化完全没问题,并且都做了减少数据传输的目的。
具体原因到底是什么呢?
我来看FilterOperator的代码实现:
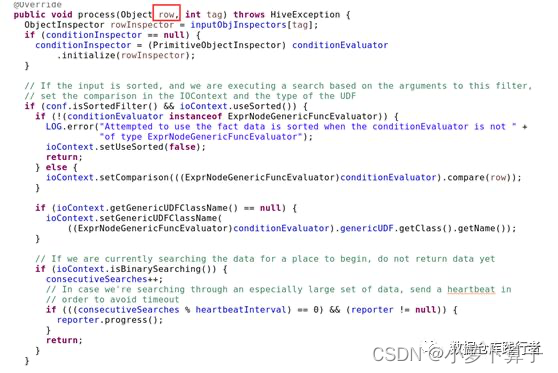
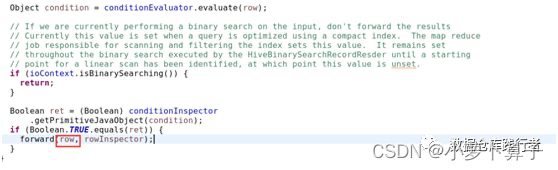
FilterOperator通过process()方法来处理上一个Operator传输过来的数据,这里的row即为真实数据,forward负责将处理好的数据传递给子Operator处理,从代码中我们看到FilterOperator在向下一个Operator传递数据的时候,只是过滤掉了不符合要求的数据,并没有对数据本身做列裁剪。而FilterOperator的RowSchema却进行了列裁剪,即由之前的[_col0:int,col1:string]变为[_col1:string]
也就是说,真正的数据是[1,‘a’] 而对应schema数据描述为[_col1:string],会不会奇怪这样的情况,在执行过程中到底是怎么处理的?
我们来做个实验:
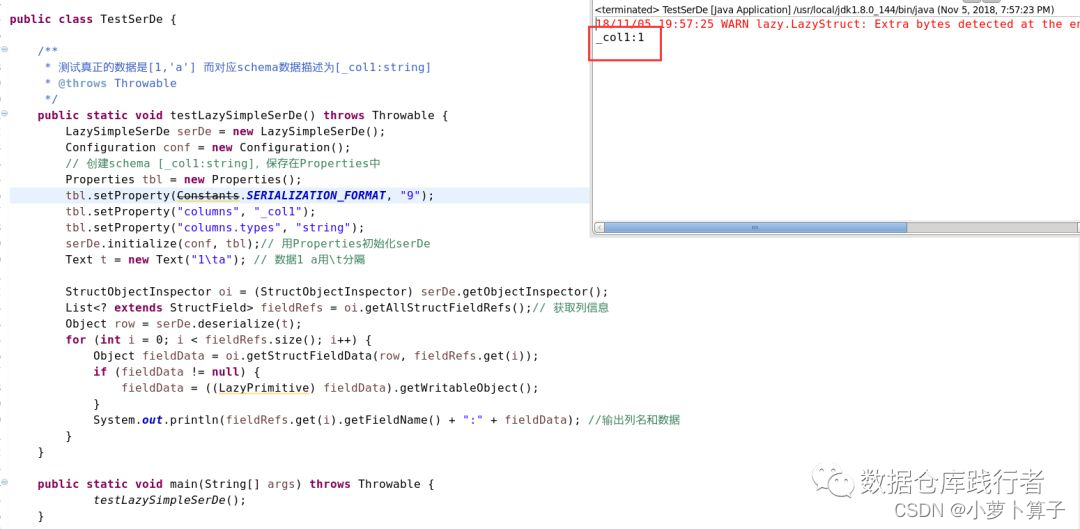
测试hive serde之后,发现这种情况下,会舍弃掉’a’,直接取了处在第一个位置的数据1。这一块,在看了serde源码后,就能很容易理解了。
在这种情况下,来看一下,数据在最终的OperatorTree上是怎么传输的

以上就是关联不出数据的原因了
3、解决方案
解决方案有以下几种:
- 写sql要严谨,没有使用到的字段不要写。
如果把sql调整为:
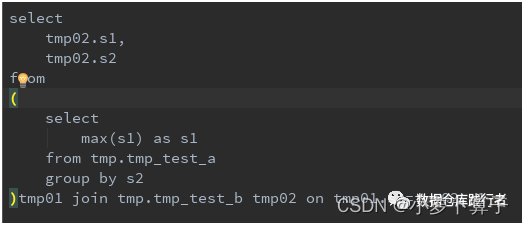
就能正常出结果,大家可以自己想一下原因哦 - set hive.optimize.remove.identity.project=false 关闭IdentityProjectRemover优化器
- 升级hive版本
为hive1.2.1打补丁
4、思考
如果这个补丁让自己来实现,该怎么设计?
推荐阅读:
从一个sql引发的hive谓词下推的全面复盘及源码分析(上)
从一个sql引发的hive谓词下推的全面复盘及源码分析(下)















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











