



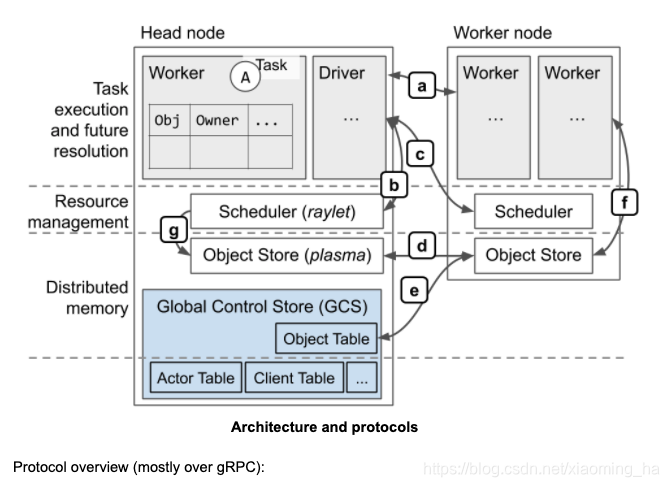
框架概览
概念
- Task: 函数调用,运行在和调用程序不同的进程中。
- Object:调用task同步返回的类
- Actor: 一个有状态的worker进程。 必须由handle提交
- driver:运行主代码的进程
Task生命周期
ownership
在ray中,大多数系统metadate都是由一个叫做ownership的去中心化概念来管理。每个worker进程都管理和拥有(owner)他提交的tasks和由这些任务所返回的ObjectRefs。拥有者(Owner)来负责确保任务的执行和返回的objectRef被解析为其真正的值。相似的,一个worker拥有其通过 r a y . p u t ray.put ray.put来创建的objects。
拥有者(owner)来负责确保被提交任务被执行和返回的ObjectRef被解析为其真正的值。
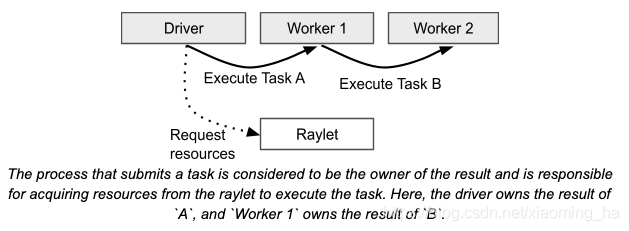
提交任务的进程被认为是结果的拥有者(owner),负责从raylet获取资源以执行任务。在这个图中,Driver拥有Task A的结果,Worker1拥有Task B的结果。
当任务被提交之后,拥有者(owner)来等待任务的所有依赖变得可用,例如ObjectRef作为task的参数依赖时,注意到依赖并不是一定要在本地,可在集群中的任何一个节点。一旦集群中任何位置的依赖都变得可用时,拥有者(Ower)就会就会认为这些依赖已经ready。当task所有依赖ready时,拥有者(Owner)会向分布式调度请求资源以执行任务。一旦资源可用,调度就会批准请求并且返回一个worker的地址,这个worker用来真正的执行这个task,文档中描述此worker为出租给owner的一个worker。
拥有者(Owner)通过gRPC发送task specification调度任务给worker。worker执行task完成之后必须存储任务结果。如果任务结果比较小,worker直接将值返回给owner,owner再将结果复制到进程内部object store;如果返回值比较大,worker将objects存储到本地的共享内存存储中,并且回应owner告诉其object现在在分布式内存中。这样拥有者(owner)即使不获取objects到本地也可以引用obejcts。
当被提交的任务使用ObjectRef作为参数时,worker执行任务前obejct value必须被解析。如果value很小,直接从owner的进程内部对象存储复制到task description,这样执行任务的worker便可以引用value;如果value非常大,则obejct需要从分布式内存中获取,目的为执行任务的worker可以复制object到它本地的共享内存存储中。调度来寻找obejct的地址且向一个不同的node请求副本来协调这个object的传输。
tasks可以以错误来结束。ray会区分两种类型的错误:
- 应用级别:worker进程是活着,但是任务以错误结束了。例如python的
- 系统级别:worker进程死了。例如进程吐核或者本地raylet死了。
由于发生应用级别错误而失败的task不会重试,由于发生系统级别错误而失败的task会重试,重试次数可以指定。
Object生命周期
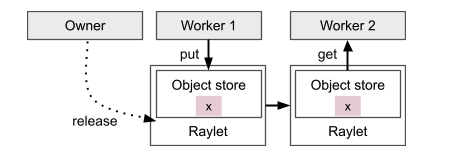
workers可以创建和获取obejct,Owner用来负责何时可以安全的释放object。
Object的Owner拥有者是如下worker进程:创建initial ObjectRef、提交创建task或者调用ray.put。Owner来管理Object的生命周期。Ray可以保证只要Owner是活着的,Object会最终解析为他的值(或者为worker失败导致的错误)。如果owner死了,获取obejct值的尝试不会终止,但可能会跑出一个异常。Object能够存储在Owner的进程内部内存存储中或者分布式的obejct存储。这是为了减少内存占用和解析时间。
当没有失败的时候,从Object解析为value最终会保证成功(可能会报应用级别错误)。如果发生失败,解析可能会报系统级别的错误,但不会被挂起。如果object存储在分布式内存中且所有object的副本都由于raylet的失败而丢失,则Object会失败,ray提供了一个选项reconstruction来自动恢复这类丢失。object也会因为owner死了而失败。
Actor生命周期
Actor的生命周期和元数据都由GCS service来管理。actor的每个client在本地缓存元数据,使用这些元数据通过gRPC发送task给actor。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TdFvkXqC-1618808519082)(evernotecid://FCDDB9A1-4E91-4D08-8E8A-A216162B2A21/appyinxiangcom/28667685/ENResource/p73)]](https://i-blog.csdnimg.cn/blog_migrate/f7fd58a8fb3747082487e7c94304dfd1.png)
task的提交是完全去中心化的,并且由task的拥有者(Owner)所管理。actor则完全不同,actor的生命周期由中心化的GCS service管理。
当在Python中创建一个actor, 创建actor的worker进程会同步注册actor到GCS,这是为了确保在actor被创建之前如果创建actor的worker进程失败时保证正确性。当GCS回应之后,创建actor的worke进程的剩余工作就是异步的了。创建actor的worker进程会在本地排队一个特殊的task,一个创建actor的task。这个task和平常的task相似,除了指定的资源被获取,这些资源用来维持actor的生命周期。creator会异步的解析创建actor的task所需的依赖,然后将其发送到GCS service等待被调度。同时Python调用创建actor会立刻返回一个actor的handler,即使创建actor的任务还没有被调度,此handler句柄也可以被使用。
actor的task执行和普通的task是相似的:调用actor的task时会返回一个future,任务会通过gRPC直接提交给actor进程,当所有的ObjectRef依赖被解析之后,被提交的任务才开始执行。不同主要有如下两点:
- 执行一个actor task不需要向调度申请资源。因为当创建actor的任务被调度时,actor就被赋予了自己生命周期所需的资源。
- 每一次调用actor,tasks都会按照被提交的顺序执行。
当创建actor的进程退出,或者不再有带执行的任务,或者actor的引用计数为0时,一个actor将会被清理。
Ray也支持异步actors(async actors),异步actors使用异步事件循环来同时运行tasks。从调用者的角度提交tasks给异步actors和提交任务给常规actor是相同的。唯一的不同点是当task运行在actor中时,task会被发送到后台线程或者线程池中的异步事件循环中,来代替直接运行在主线程中。
故障
系统故障
Ray worker node被设计为是同类别的(这里用到了homogeneous,相似的),如果一个worker node丢失了不会影响整体的集群。目前有一个特殊的是head node,他是依托GCS来管理的。ray团队正在优化这个模块,让GCS运行在多个node上来增加可用性。
所有节点分配一个唯一的identifier,节点之间通过心跳进行交流。GCS来负责确定集群中每个成员,例如那些节点目前是活着的。GCS会销毁超时的节点id,当一个新的raylet启动时会使用一个不同的ID作为节点标识,目的为重新使用物理资源。如果心跳超时一个活着的raylet会退出。目前节点失败检测无法处理网络偏离丢失( Failure detection of a node currently does not handle network partitions):如果一个节点从GCS丢失了(partitioned),节点会超时且被标记为死亡。
如果本地的worker 进程死亡,则raylet会报告给ccs,GCS会广播这些失败的事件且使用它们来处理actor死亡。
raylet负责当个别worker进程失败之后预防集群资源和系统状态的泄漏。当本地或者远程的某个worker进程失败之后,每一个raylet会负责:
- 释放任务执行所需的集群资源,例如cpu。假设workerA调用了task,task在workerB中执行,则如果workerB失败了,则由workerA来释放集群资源。失败的worker未完成的资源申请也会被取消。
- 释放失败worker所拥有的object所使用的分布式对象存储内存。在GCS中存储的object字典信息中的对应信息也会被清理。
应用故障
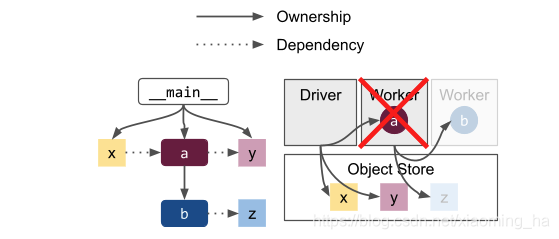
系统级别的故障意味着在ray graph里的task和object与他们的拥有者共存亡。例如,如果运行着taska的worker失败将回收在其子树中创建的所有tasks和objects,例如图中的task b和object z。如果b是在a的子树中被创建的actor也是同样适用的。不过会涉及以下几点:
* 任何健康的进程如果想要得到这样的object(也就是actor对应的object)会收到一个应用级别的异常。例如上图中object z对应的future objectRef返回给driver,driver调用`ray.get(z)`则会收到一个错误。
* 修改程序将不同的tasks放到不同的子树subtrees中,这样失败可以与其他任务隔离,例如嵌套调用。
* application会与driver共存亡,因为driver是root of tree。
使用detached actor可以让主程序避免共存亡,detached actor 会超过driver的生命周期,仅仅使用来自程序制定的调用才会被摧毁。detached actor自己可以拥有任何的其他tasks和objects,这些都会与actor共存亡。
Object Management

一般情况下,比较小的objects存储在他们的owner的进程内存储中,而大的objects会被存储在分布式对象存储中。这么做是为了减少内存占用和解析时间。对于后一种情况,当被存储在分布式内存中,一个object占位符也会存储在进程内存储中,来表明这个object已经存储在了分布式共享内存中。
在进程内存储的objects直接使用内存复制可以很快被解析,但是当被很多进程所引用时会产生很多额外副本进而导致更高的内存占用。worker进程内存储容量会被机器的内存容量所限定、从而限制了任意时间能够被引用的objects的数量。对于被引用多次的objects,吞吐量会被owner进程单位时间处理的次数所限制。
相反,解析分布式对象存储中一个对象至少需要一个从当前worker到worker本地共享内存存储中的IPC。如果worker的本地共享内存中不存在此object的副本,那么还需要一个RPCs,另一方面,因为分布式共享内存存储是用共享内存来实现的,相同节点的多个worker进程可以引用同一个object的副本。当一个object可以用零个副本来反序列化,这样可以整体减少内存占用。分布式内存也允许一个进程引用不再本地node存储的object,意味着一个进程可以引用objects,且obejcts的总大小可以超过此节点机器的内存容量。最终,吞吐量会随着分布式对象存储中节点数量而扩展,因为一个object的多个副本会存储在不同的节点中。
object解析
object的值可以使用objectRef来解析。ObjectRef由以下两个字段组成:
* 一个20-byte的唯一标识符。标识符由产生object的task的id和到目前为止task所产生的objects数量连接而成。
* object的owner的地址,也就是一个worker进程的地址。这个地址由如下四部分组成:worker进程的唯一ID,IP地址和端口号,以及本地的raylet唯一ID组成。
小的objects通过直接从owner的内部进程存储中复制而被解析。例如,如果owner调用了`ray.get`则系统会从本地内部进程存储寻找且反序列化值。如果owner提交的任务有ObjectRef作为参数,则会直接复制object的value到task描述信息中。注意这里的objects都是owner进程的本地对象。如果其他进程尝试解析这个value,object会提升到共享内存中,然后通过分布式对象解析的协议来获取。
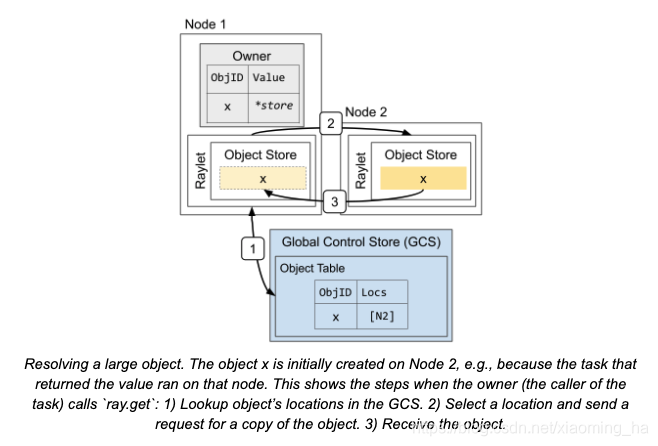
图为解析一个大的object。object x在节点2被初始化创建,例如task返回的value在此节点上。当调用task的拥有者owner调用ray.get时,会发生下面的事情:1)从GCS中寻找object的位置2)选择一个位置并且发送复制这个object的请求3)收到object。
大的objects被存储在分布式对象存储中并且使用分布式协议来解析。如果obejct已经存储在了引用此object的进程的本地共享内存中,也就是位于同一个节点,引用object的进程可以通过IPC来获取object。这会返回一个指向共享内存的指针,且这个指针可能会同时被同节点的其他worker所引用。
如果object不在本地共享内存中,引用object的调用者会通知本地的raylet,然后尝试从远程raylet获取一个副本。这个raylet会从object directory中寻找位置然后向拥有object的raylet中选一个发送传输请求。
内存管理
对于远程task而言,执行task的worker会计算object的value。如果value是小的,worker会直接返回value给owner,owner复制value到自己的进程内存储。如果value是大的,执行任务的worker会将值存储在他的本地共享内存中,共享内存对象的初始化副本为第一个副本,叫primary copy。
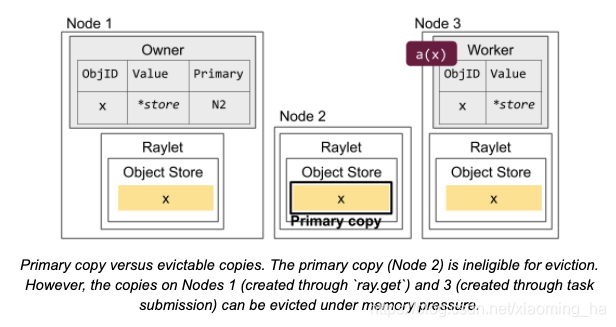
primary copy vs evictable copyies(第一个副本与可驱逐的副本)。prinamry copy,也即是第一个创建的副本,例如途中节点2,是不能够被驱逐的。然而节点1中的副本为通过ray.get创建的,及节点3中的副本是通过任务参数而传进去的,这两种类型的副本在共享内存对象中是可以被驱逐的。
只要owner所拥有的object对应的的ref count数量大于0,primary copy就是唯一的,且不会被驱逐。这与这个object的其他副本是不相同的,它们可能由于本地的内存压力而被LRU而驱逐。因此会有一个问题,当一个object存储包含的都是primary copy副本并且达到了内存的容量,那应用如果在想要存储其他的object时将会收到一个OOM(OutOfMemoryError)异常。
在大多数情况下,primary copy是第一个被创建的object。如果初始化的副本因为失败而丢失,Owner拥有者会尝试从可用的object地址中制定一个副本作为新的primary copy。
如果object的ref count数量降为0,object的副本最终会被自动垃圾回收。小的object会立刻被owner从自己的进程内部存储中被清除。大的object会被raylet异步的从分布式对象存储中清除。
raylet也管理分布式object的传输,会根据目前需要的object地址而创建object的额外副本,例如依赖object的一个task被调度到一个remote节点。
reference counting引用计数
每个worker针对每个它拥有的objecgt会存储一个ref count,owner的本地ref count包括了本地python引用的数量和由owner提交依赖此object的pending tasks的数量。对于前者当python的objectRef被释放时ref count会递减,对于后者当依赖此object的一个task成功完成时,refcount会被递减。
ObjectRef通过存储他们到另一个对象里进而能够被复制到另一个进程内。接收这个objectRef副本的进程被叫做borrower。例如:

在上面的代码中,objectRef被放进对象列表里,然后将列表作为task或Actor task的参数,间接的将objectRef传入到了其他的进程中,其他的进程也被叫作borrows,这个情况,即使ObjectRef对应的value还没有ready,但是borrows进程已经开始运行。
这些引用(references)通过一个分布式引用计数协议distributed reference counting protocl而被跟踪。简单来说,只要一个reference引用离开了本地,owner就会在本地增加object对应的ref count。例如在上面的代码中,当调用borrower.remote和b.borrower.remote时,owner对于x_ref objectref增加pending task数量的ref count。一旦task完成了,borrower进程会返回objectRef的一个列表给owner,这个列表存储着仍在被借borrow的引用。例如在上面的代码中,temp_borrow的worker回应说他不再借x_ref, 而Borroweractor会回应说它还要继续借x_ref。
如果worker仍要borrow借用一个引用,引用的owner将会增加一个worker的ID到本地的borrower列表中。Borrower也会在本地保存一份与owner相似的ref count,一旦borrower的本地引用计数(ref count)数量减为0,owner要求borrower做出回应。在上述的例子中,’Borrower‘ actor将会永久性的借用reference,直到‘Borrower’actor生命周期结束或者死了,owner才会释放这个object。
如果borrower自己传递‘ObjectRef’给其他的进程,Borrowerss会被递归的添加到owner的列表。在这种情况下,当borrower回应owner自己的本地ref count数量为0时,并且borrower创建了一些新的borrower,那么owner就会继续与新的租客borrower使用相同的协议进行交互。
一个相似的协议用来跟踪owner创建的objectRef,例如:


当child函数返回返回时,x_ref的owner,也就是worker2,会标记x_ref包含在y_ref中。Owner会增加parent worker1到借用了x_ref的借用者列表中。在这里,owner,也就是worker2,发送信息给worker1,要求borrower一旦他的y_ref和x_ref都使用结束,则做出回应给owner。
| Reference type | Description | when is it updated |
|---|---|---|
| Local python ref count | 本地ObjectRef实例数量,等于 worker 本地进程 python 引用计数 | 当 Python ObjectRef分配或者释放的时候递增或者递减 |
| submitted task count | 依赖这个 Object 的提交的还未执行完的任务数量 | |
| Borrowers | 进程 id集合,这些进程正在借用ObjectRef。borrower 是除了owner以外的任务一个worker且这些worker在本地拥有借用的ObjectRef的实例。非owner的workers也会保存一个集合,当worker将ObjectRef借给另一个borrower时,便将另一个borrower存入集合中。 | 当worker发现ObjectRef被另一个worker借走时, worker会增加另一个worker id到自己保存的集合当中。例如当一个actor task保存ObjectRef到本地的状态中,ObjectRef的caller,也就是被借走的worker,会增加此actor的worker ID作为owner,Owner发送一个长连接的异步RPC到每个borrower worker,borrower 对ObjectRef的引用计数一旦为0,则立刻回应owner,owenr收到后会移除worker。作为borrower,worker等待来自owenr的RPC。一旦worker的引用计数(包括本地python count和被提交任务数量)为0,worker会pop移除其本地的borrower集合,并且将这些其余的borrower回应给owner。通过这种方式,owner可以学习且跟踪递归产生的其他的borrowers。 |
Actor handles
相同的引用计数协议也用来跟踪actor的生命周期。一个假的obejct用来表示actor。obect的ID是根据actor创建的task的id来计算的。actor的创建者拥有这个假的object。
当python的actor handle被释放时,会减少本地假object的ref count。当一个task由actor handle提交,接收进程会以假object的借用者的身份被计数。一旦引用计数为0,owner会通知GCS服务actor可以被安全的摧毁收回。
Object Loss
小的object: 存储在晋城内对象存储的小object与他的owner共享生命周期。如果被借的objects被提升到了共享内存,接了这个object的borrowers都会检测到失败。
当分布式内存中的objects丢失: 如果是object的Non-primary副本,也就是非第一个创建的副本,丢失不会造成任何的影响。如果primary copy,也就是一个类的第一个副本丢失的话,owner会尝试在object字典存储中寻找新的副本作为新的第一个副本(primary copy),如果object副本记录中没有其他的副本,owner会存储一个系统级别的错误,这个错误将会在object 解析期间被抛出。
Ray也支持object的重新构建,或者是通过重新执行创建object的task来恢复丢失的object。当这个功能被触发时,owner会缓存object的谱系:也就是需要重新创建内存中object的任务的描述信息。然后如果object的副本由于失败而丢失,owner会重新提交返回丢失object的task。这样每一个task所依赖的object会递归的被重建。
object的重新构建不支持由ray.put创建的objects:此类object的primary copy(第一个副本)一直在woner的本地共享内存中。因此,此类的primary副本不会独立于owner的进程而丢失。
如果存储在分布式内存中的eobject的owner丢失了:在object被一个worker解析期间,对应的raylet会尝试定位object的副本。同时,raylei会间接的联系owner来检查owner是否还活着。如果owner死了,raylet会存储一个系统级别的错误,这个错误将在object解析期间抛出给引用持有者。
资源管理和调度
在ray中的一个资源对应着一个键值对:“key” -> 浮点数。为了方便起见,Ray调度支持本地cpu、gpu和内存资源类型,也就是ray会自动检测每一个节点上这些可用的物理资源。然而用户也可以使用任何有效的字符串定义自定义资源需求(custom resource requirments)。例如:{“something”: 1}。
分布式调度的目的是从集群里可用的资源中匹配来自owner的资源请求。资源请求是硬性的调度约束,例如,{“CPU”: 1.0, “GPU”: 1.0}代表着一个请求一个cpu和1个gpu。这个task仅仅能够被调度到拥有cpu和gpu的个数都大于等于1的节点上去。ray.remote方法会请求一个cpu来执行{“CPU”: 1},一个actor,例如ray.remoteclass 默认会请求{“CPU”: 0}。
有一些特殊处理的资源:
- cpu、gpu和内存的数量在ray startup期间会自动被检测
- 分配gpu资源到一个任务将自动设置worker内部CUDA_VISIBLE_DEVICES环境变量的值,以限制worker自定的gpu ids。
注意到资源限制不会被ray所强制(除了actor内存:如果指定了内存请求数量,一个actor的内存限制在每个task之行结束时会被检查)。用户可以指定精确的资源请求数量,例如指定"num_cpus=n",此一个任务将会拥有n个线程。ray的资源请求的主要目的是准入控制和自动伸缩。
任务调度(owner-raylet protocal)
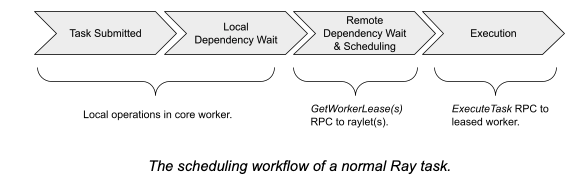
Dependency resolution(依赖解析)
调用任务的进程在从分布式调度请求资源之前会等待所有的task 参数都被创建。在大多数情况下,一个任务的调用者也是任务参数的拥有者。例如,像’foo.remote(bar.remote())'的程序,调用者同时拥有两个task,直到bar被执行完成才会调度foo。调度的执行在本地节点便可完成,因为调用者会存储bar的结果在自己的进程内存储中。
task的调用者也可能会从其他进程借一个task参数,例如,调用者从owner那里收到一个参数的ObjectRef的返回序列化副本。在这种情况下,task的调用者需要与参数的owner执行协议沟通确定参数何时被创建。在objectRef被序列化之后,借用object的borrower进程会联系owner,owner在object被创建之后立即作出回应,borrower收到回应用后会标记object已经就绪。如果owner失败了,borrower也会标记object为就绪状态,因为object和他们的owner是有共同生命周期的。
Tasks有三种类型的参数:普通值,inlined object和non-inlined object。
* Plain values(普通值):f.remote(2)
* Inlined object: f.remote(small_obj_id)
* Non-inlined object: f.remote(large_or_pending_object_id)
普通的值不需要依赖解析。
Inlined object是足够小且可以存储在进程内部存储的对象。(默认的分界大小为100KB)。Owner可以直接复制对象到task 描述信息中。
Non-inlined object 被存储在分布式对象存储中,其包括两类:大的object和被除owner以外的其他进程借的objects。在这种情况下,owner会要求本地节点的raylet再调度决定之前寻找task的依赖。raylet等待这些依赖对象都存储在本地节点之后再去授予一个worker权限来借这个task。这确保了执行task的进程worker不会因为接受任务时等待依赖对象变成本地对象而发生阻塞。
Resource fulfillment
owner首先发送资源请求给本地的raylet来调度任务。本地raylet将资源请求放入队列中,如果raylet选择分配资源,会回应owner租给owner的本地worker地址。只要owner和被租的worker都是健康的,此租约会一直生效,并且raylet会确保不再有其他的客户端来使用租约正在进行中的worker。为了公平起见,如果没有任务或者足够的时间过去了,owner便会返回worker。
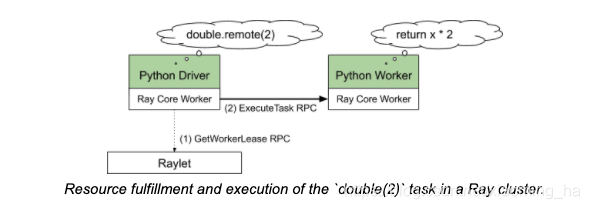
只要多个task所请求的资源是兼容的,owner可以调度任意数量的task到被租的worker。因此,租约可以被认为是一种优化,避免为了相似的调度请求与调度器进行多次的沟通。
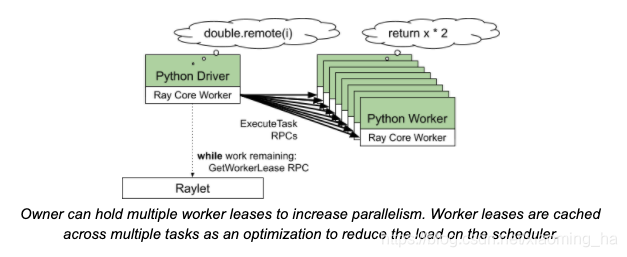
Owner可以拥有多个worker租约来增加并行性(也就是申请多个worker执行多个task)。当有多个task时worker租约也会被缓存起来作为优化,以减少调度负载。
如果raylet不选择分配本地资源(本地资源不满足时),raylet会回应owner一个远程的raylet地址,owenr重新向新的raylet请求资源。这被称为spillback scheduling(溢出调度)。Spillback scheduling 调度会迭代遍历:此调度不会直接转发资源请求给其他raylet,每个raylet都会回应owner下一个请求的raylet地址。这样做确保了owner用来记录task位置的元数据metadata始终都是一致不变的。
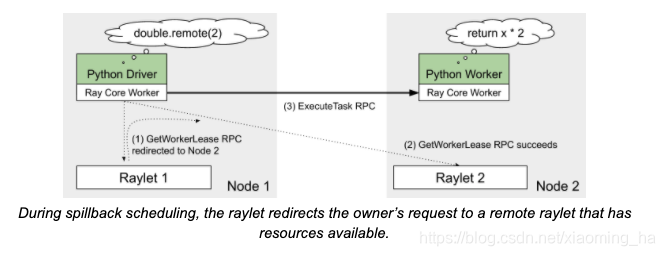
Distributed sheduler(raylet-raylet 协议)
Resource accounting(资源占用)
每一个raylet会跟踪本地节点的资源。当一个资源请求被分配时,raylet会减少相应的本地可用资源。一旦资源被返回(或者请求资源的worker死了),raylet相应的增加本地可用资源。因此,raylet总是可以保持本地可用资源的一致性。
每个raylet也会从GCS那里收到集群中其他节点的可用资源,以实现分布式调度,例如保持集群节点之间的负载均衡。为了减少收集和广播的开销,这个信息只有在最终保持一致性,也就是说raylet获得的其他raylet资源可能不是最新的。这个信息是通过间接的广播发送的。每次心跳间隔默认是100ms,每个raylet发送他的本地可用资源到GCS service,GCS 将这些心跳合并然后广播给其他的raylet。
Scheduling policy(调度策略)
raylet首先尝试使用本地资源满足收到的资源请求。当本地资源不可用时,有三个其他的可能:
- 根据由GCS发布的可用信息(这个信息可能是旧的),其他节点有足够的资源。raylet会(spillback)转移这个请求给其他的raylet。
- 目前没有节点有足够的资源。task在本地会排队,直到本地资源或者远程资源变成可用。
- 在集群中没有节点拥有请求的资源。例如在只有cpu资源的集群中申请{“GPU”: 1}。任务被认为是不能够被执行的(infeasible)。raylet会发出警告信息给相应的driver。raylet排队此任务,知道资源变的可用,例如增加拥有一个gpu的节点到集群中。
在将来raylet可能会在本地做调度决定。例如分配task到本地拥有task的一个参数的node。这个功能目前没有被实现。
自动伸缩
ray的自动伸缩主要负责启动一组初始的集群节点,以reousrce demands(资源需求)为基础依据需求增加额外的节点。
在Ray 1.1+版本中,控制循环根据如下实现:
1. 为了满足当前pending的task、actor和placement group申请的资源,计算需要的节点数量。
2. 启动新的节点
a. 如果请求的节点总数量 / 当前节点的数量 > 1 + upscaling_speed,此时要启动的节点数量会被该阈值限制。
b. 当节点是通过request_resources()被启动时,upcaling_speed限制会被忽略。
3. 如果一个节点空闲时间超过了预定值,默认为5分钟,节点将会被从集群中移除。
1.1版本最新算法的优势在于可以扩展精确的节点数量以满足resource demands。而之前的版本只能根据大致利用率来进行扩展,不能够精确的计算具体需要多少个节点。
ray也支持多个集群节点类型。一个集群节点类型的概念即包含了物理资源类型(例如AWS p3.8xl GPU nodes vs m4.16xl CPU nodes)也包括其他的属性。可以为每种节点类型指定自定义资源,这样ray在一在应用层可以知道特定节点类型的需求。(例如一个task通过自定义资源请求被分配到拥有一个特殊角色或者机器镜像的机器上)
自定义资源
除了本地系统资源,例如CPU、GPU和内存, Ray支持自定义资源的定义和使用。自定义资源通常在节点启动时被添加,例如一个节点通过自定义资源{“HasHardwareFeature”: 1, “HasDatasetA”: 1}被通知其拥有一个特殊的硬件特征和数据集。task和actor能够请求这个资源的一定数量,从而被调度到指定节点,有效的控制他们运行在特殊的节点上。自定义资源也能够通过task动态增加到一个节点。
Placement Groups
在Ray 1.0版本,ray支持placement groups。Placement groups允许用户在多个节点间自动保留一组资源。任务能够申请这些保留的资源,并且调度上支持特殊的策略,比如多个task使用PACK策略请求组成一组资源的资源束,则task会被集中的打包尽可能的分配到同一个节点去;使用SPREAD策略可以将多个task尽可能分散的分配到多个节点中,且这些节点拥有申请的placement groups相应的资源束。Groups也可以被摧毁来释放和groups相关的所有资源。Ray Autoscaler会检测placement groups,并且自动伸缩集群的规模来确保排队的请求的groups可以按需要在集群中被保留。
Multi-tenancy
在Ray 1.0版本,ray支持Multi-tenancy,Multi-tenancy的基本功能是对于执行不同jobs的workers可以设置不同的环境变量。这允许在一个ray集群中存在多种软间隔(soft-isolated)环境(e.g., different PYTHONPATH, Java CLASSPATH)。为了确保隔离,当Multi-tenancy被启用时,worker进程在不同的job间不会重复使用。
Actor management
actor 创建
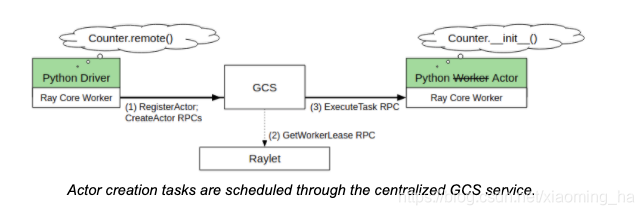
在python中当一个actor被创建时,正在创建actor的worker首先会同步的注册actor到GCS。在这种情况下确保了actor被创建之前创建actor的进程死了,其他的任何引用此actor的worker能够发现这个失败。
创建actor的行为也会被作为一个特殊task来处理。一旦创建actor的task的所有依赖都解析完成,创建actor的进程会发送task specification给GCS service。GCS service然后会使用与普通task相同的分布式调度协议调度创建actor的task,即便GCS是创建actor的task的owner这类情况。因为GCS service会将所有的信息持久化存储到后端存储中,一旦task specification成功发送到GCS service,actor最终将会被创建。
最开始创建actor的创建者,也是上面特殊task的owner,可以使用actor handle开始提交tasks,甚者在GCS调度actor之前actor的创建者将actor handler 传递给其他的tasks/actors。一旦actor被创建了,GCS通过pub-sub的模式通知拥有actor handle的任何一个worker。每个handle用来缓存最新的创建的actor 运行时元数据(例如RPC地址和所在的节点)。使用actor handle提交的所有tasks会被发送到actor来执行。
Actor 任务执行
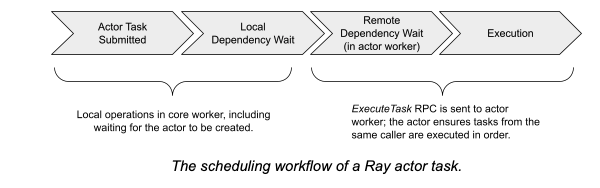
每个actor不会限制调用者的数量。一个actor handle代表着一个简单的调用者:handle包含了其引用的actor的RPC地址。调用actor task的worker会连接这个地址并提交task。
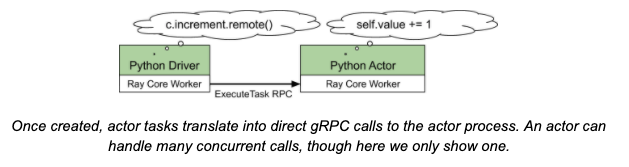
每一个被提交的任务在调用方会被分配有序的序号,这个序号被接受task的actor使用以确保来自每个调用者的任务可以按照他们被提交的顺序依次执行,即使task信息在传输过程中被重新排序。但是在调用者间是不能保证task执行顺序的。例如在两个调用者之间任务的执行顺序会依赖信息延迟和任务的依赖变成可用的顺序。
Actor 生命周期
Actor可以是detached 或者non-detached(此处两者的区别没有弄清楚,还不能直接翻译)。non-detached actors是默认的并且被推荐存储临时状态,当actor的父进程或者job退出时actor的物理资源应该自动收回。
对于non-detached actor,当所有pending排队的actor tasks被完成且actor的所有handles的引用计数都为0,actor的原始创建者会通知GCS service,GCS service然后会提交一个特殊的任务__ray_terminate__给actor,来通知actor要优雅的退出自己的进程。如果GCS检测到了actor的创建者退出了,GCS也终止actor。所有pending排队以及后续被提交到actor的任务都将会得到RayActorError的失败。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zye7XVFS-1618808519092)(evernotecid://FCDDB9A1-4E91-4D08-8E8A-A216162B2A21/appyinxiangcom/28667685/ENResource/p89)]](https://i-blog.csdnimg.cn/blog_migrate/58165373b37ccc9c3fc3051208363358.png)
actor也可能在自己运行期间crash死掉了(例如吐核或者系统退出)。默认其况下所有被提交给死亡的actor的task都将会收到RayActorError失败,即使actor正常退出的情况也是一样的。
Ray也会提供一个选项来自动重启actors。并且会尝试指定的数量。如果这个选项被开启,GCS service会通过创建actor的特殊任务尝试重新启动一个死亡的actor。所有拥有handle的客户端会缓存提交给actor的pending task,直到actor被重新启动成功。如果actor没有被重新启动或者到达了重新启动次数的最大值,客户端都将会认为所有的pending task失败。
GCS(全局状态存储)
The global control store 拥有关键的但是很少被访问的集群元数据,例如连接到客户端或者节点的地址。在更早的ray版本,GCS也拥有小的objects的系谱和元数据,意味着对于大多数操作都会经过GCS,例如任务的调度。在最新的ray版本中,对象的系谱和元数据大部分都被移到了worker进程内部,这样在大多数操作过程中都不会走到GCS。这样整体上提高了执行效率,减少了GCS存储需求。
存储
GCS目前时使用redis实现的,我们通过pub-sub模式依赖redis。但是目前团队正在做这方面的努力来移除对于redis的依赖,支持插件模式的持久化存储(例如mysql)。
Actor Table
用来存储actor和actor状态的列表。这个表被用来在失败时重新创建actor,也用来管理actor的生命周期。
Heartbeat Table
用来存储连接到ray的client、workers和节点的列表
每个ralet会间接的发送心跳给GCS来表明节点是活着的,并且向GCS报告其调度线程目前的资源使用情况和负载。GCS间接的整合所有的来自raylet的心跳,这是为了减少网络宽带的使用,整合之后将整合的信息广播回所有的节点。这用来确定集群的成员关系和分布式调度。广播的信息也被用来使用于自动伸缩。
如果GCS在之前配置好的心跳间隔次数之内没有收到来自raylet的心跳,GCS会标记raylet死亡,然后广播信息给所有的节点。如果raylet收到了自己被标记为死亡,它的物理资源会被重新用来创建新的raylet,新的raylet被分配一个不同的唯一ID。
Job Table
用来存储正在集群中运行的job表。当一个job停止时,ray会取消正在运行的用Job创建的asks和actor以避免资源泄露。
Object Table
用来存储大的共享内存对象的节点位置。当raylets要获得的object变成可用时,Raylets使用Rdis pub-sub机制来得到可用的通知,并且选择一个节点来下载object数据。当一个共享内存中的object在本地被创建或者删除时,raylets会自己更新这个table表。
注意:这一点正在努力从GCS移除object表到owenrship表中,以便提高可扩缩性和分布式object的传输效率。
Persistence
GCS目前不支持持久性存储,目前正在目录通过SQL数据库来使数据持久化。Ray会为Redis设置最大值,如果不够使用会移除不重要的数据。但是在0.8版本之后,很少情况会超过这个最大值,因为大多数大的object和任务元数据都不在存储在GCS中。
附录
下面是详细图图解和系统实现的例子。
结构图
我们通过执行下面的ray程序来查看ray的执行过程:

在这个例子中,task A提交了task B和C,C依赖B的输出。为了图的展示,我们假设B返回了大的对象X,C返回了小的对象Y,以此展示在进程内部和分布式内存对象存储中的区别。我们展示了如果taskA、B、C都执行在不同的节点以此展示分布式调度。
分布式调度
我们假设worker1来执行A,任务B、C已经被提交给worker1.因此,worker 1的ownership表已经包括X和Y,我们展示调度B来执行的例子。
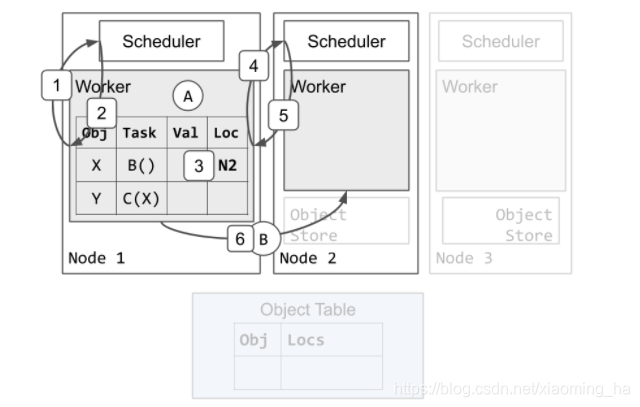
我们使用worker 1来代表节点1上的worker,使用worker 2表示节点2上的worker,调度同理。
- worker 1向本地的调度请求资源来执行B。
- sheduler 1回应worker1尝试向node2发起调度请求。
- worker1更新本地的ownership 表来记录task B将会被发送到node节点2.
- worker1向节点2的调度请求资源来执行B
- 调度2将资源分配给worker1并且回应worker2的地址给worker1.shedular2确保当worker1仍然持有资源时不再有task被分配到worker2。
- worker1发送任务B到wroker2来执行。
任务执行
接下来展示worker执行一个task并且将返回值存储在分布式对象存储中的例子。
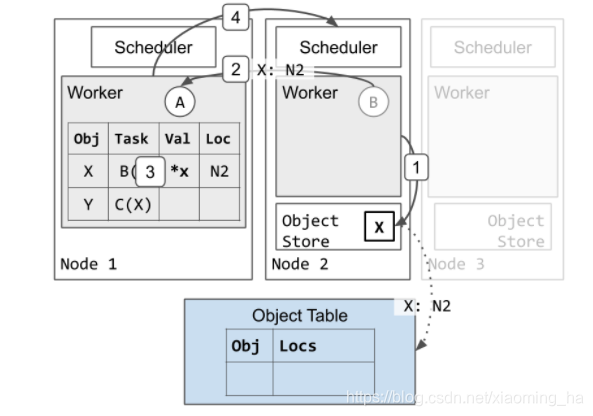
- worker2执行B完成之后会存储返回值X在自己的本地对象存储中。
a. 节点2异步的更新object table表,表明值X现在是在节点2上。
b. 因为X是被创建的第一个副本,在worker1通知节点2可以释放object之前节点2会一直固定保存副本(在图中没有展示),这样是为了确保object被引用期间其值存在。 - worker2回应worker1其任务B已经执行完成。
- worker1更新自己的ownership table来表明X被存储在分布式内存中,此处存储的是指向X value的指针。
- worker1返回资源给调度2.worker2之后会被重新使用来执行其他的tasks。
分布式任务调度和参数解析
目前B已经执行完成,任务C可以开始执行。worker1调度C时会使用和调度任务B相同的协议。
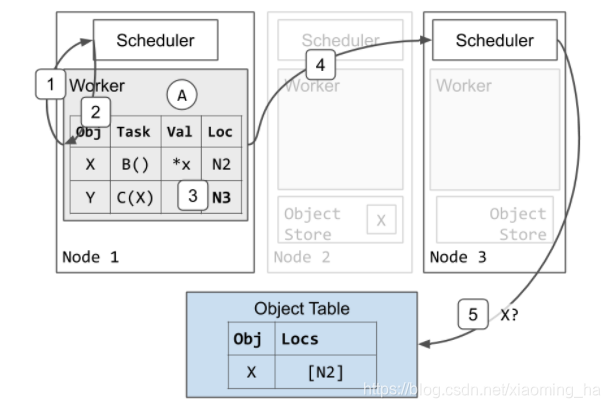
-
worker1向本地调度sheduler请求资源来执行C。
-
Scheduler 1回应,告诉worker1尝试向节点3来调度请求。
-
worker1更新本地的ownership表来表明taskC会发送到node3
-
worker1向节点3的调度发送资源请求以执行任务C。
-
调度3发现任务C依赖X,但是节点3本地对象存储中不存在X的副本。调度3将任务C排队,访问object table来查询X的位置。
任务C需要在本地拥有X的副本才能够开始执行,所以节点3会获取X的副本:
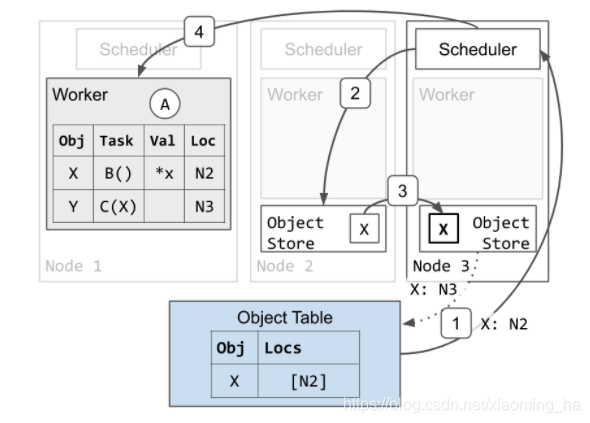
-
Object table回应调度3表明X目前在节点2拥有副本。
-
调度请求节点2的object store发送X的副本
-
X的副本从节点2被复制到节点3:
a.节点3会异步的更新object table表明X目前也在节点3上
b.节点3上X的副本被缓存但不会被固定。当一个本地worker正在使用它时,object不会被移除。然而不想节点2上的X的副本,当节点3的object store3存在内存压力时,节点3的副本可能会根据LRU而被移除。如果移除发生了节点3之后需要更新object,可以重新从节点2获取,或者使用相同的协议获取不同的副本。 -
因为节点3目前拥有了X的副本,调度3将会给worker1赋予资源请求并且回应worker3的地址。
任务执行和object内部存储
任务C继续执行,返回一个足够小可以被存储到进程内部内存存储的对象:
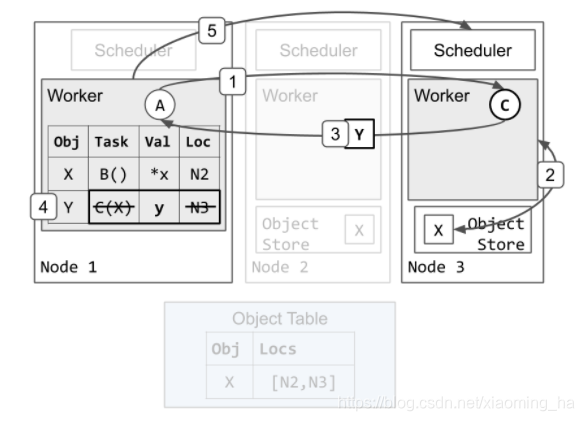
- worker1发送任务C给worker3来执行
- worker3从本地的对象存储中拿到X的值然后运行C(X)
- worker3执行完成C返回Y的值给worker1,这次不会再存储在本地分布式对象存储。
- worker1收到后存储Y到自己的进程内部内存存储中。worker1会在owership中去除任务C的描述信息和位置,因为任务C已经完成了执行。在任务A中调用的
ray.get将会从worker1自己的进程内部内存存储中找到并且返回y的值。 - worker1返回资源给调度3.worker3后续会被重新使用来执行其他的tasks。这一步可能在第四步前就做了。
垃圾回收
最终来展示worker回首自己的内存:
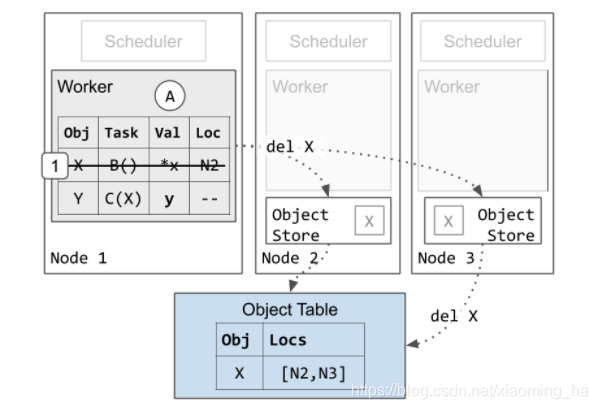
worker1会清楚对象X的所有的信息。这样做是安全的,因为pending的task C仅仅引用了X并且C已经执行完成了。worker1会继续保存Y的信息,因为应用仍在引用y的objectIP。最终X的所有副本都会被从集群中删除。在1执行完成之后可能会在任何时刻发生。正如上面提到的,如果节点3存在内存压力,节点3上X的副本在执行步骤1之前就可能会被删除。

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









