







1、概率密度函数
在分类器设计过程中(尤其是贝叶斯分类器),需要在类的先验概率和类条件概率密度均已知的情况下,按照一定的决策规则确定判别函数和决策面。但是,在实际应用中,类条件概率密度通常是未知的。那么,当先验概率和类条件概率密度都未知或者其中之一未知的情况下,该如何来进行类别判断呢?其实,只要我们能收集到一定数量的样本,根据统计学的知识,可以从样本集来推断总体概率分布。这种估计方法,通常称之为概率密度估计。它是机器学习的基本问题之一,其目的是根据训练样本来确定x(随机变量总体)的概率分布。密度估计分为参数估计和非参数估计两种。
2、参数估计
参数估计:根据对问题的一般性认识,假设随机变量服从某种分布(例如,正态分布),分布函数的参数可以通过训练数据来估计。参数估计可以分为监督参数估计和非监督参数估计两种。参数估计当中最常用的两种方法是最大似然估计法和贝叶斯估计法。
监督参数估计:样本所属类别及条件总体概率密度的形式已知,表征概率密度的某些参数是未知的。
非监督参数估计:已知样本所属的类别,但未知总体概率密度函数的形式,要求推断出概率密度本身。
3、非参数估计
非参数估计:已知样本所属的类别,但未知总体概率密度函数的形式,要求我们直接推断概率密度函数本身。即,不用模型,只利用训练数据本身来对概率密度做估计。
非参数估计常用的有直方图法和核方法两种;其中,核方法又分为Pazen窗法和KN近领法两种。
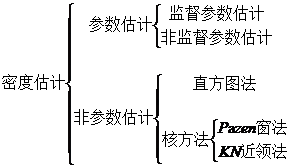
在数学上一个连续概率密度函数p(x)的需满足以下的条件:
1、x在a和b之间的概率为:

2、对所有的x,p(x)非负
3、p(x)的积分值为1

最经常使用的概率密度函数就是高斯函数(正态分布)


将一维的情况扩展到多维,现在的 x就是一个向量,p( x)也需要满足下列条件:
1、在一个区域
R内
x的概率为

2、概率密度函数的积分值为1


密度估计
给点n个数据样本x1,x2,....,xn,我们可以估计概率密度函数p(x),对于新的样本x就可以计算出相应的p(x).这个过程就是密度估计。
给点n个数据样本x1,x2,....,xn,我们可以估计概率密度函数p(x),对于新的样本x就可以计算出相应的p(x).这个过程就是密度估计。
密度估计的基础是:一个向量x落入到区域R的概率为

假设R非常小,所以p(x)的变化也很小,上面的公式就改写为:

其中V是R的“体积”
另一方面,假设x1,...,xn是根据密度函数p(x)独立取的n个样本点,其中有k个样本点落入到区域R中,关于R的概率就为:

这样就可以得到一个p(x)的估计函数:

Parzen window密度估计
假设R是以x为中心的超立方体,h为这个超立方体的边长,在2-D的方形中有V=h*h,3-D的立方体中有V=h^3。


给定上面的公式,表示的是Xi是否落在方形中。
Parzen概率密度估计公式的表示如下:

其中
 被称作窗口函数(window function)。
被称作窗口函数(window function)。
被称作窗口函数(window function)。
同时可以对窗口函数做一定的泛化,就有其他的Parzen window密度估计方法。
例如在1-D的情况下使用Gaussian函数:

这种方法就相当于将n个点为中心的高斯函数计算平均。其中标准差
 需要预先设定。
需要预先设定。
需要预先设定。
例子:
给定五个点:x1=2, x2=2.5, x3=3, x4=1, x5=6, 计算x=3位置的Parzen概率密度函数,采用
 的高斯函数作为window function。
的高斯函数作为window function。
的高斯函数作为window function。
计算过程如下:



采用图形的方式进行显示,并假设上面的5个点对整个密度函数做出相等的贡献:

采用Parzen Window对这个五个点估计得到的概率密度函数为:
















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









