







TensorFlow高级API(tf.contrib.learn)及可视化工具TensorBoard的使用
一.TensorFlow高层次机器学习API (tf.contrib.learn)
1.tf.contrib.learn.datasets.base.load_csv_with_header 加载csv格式数据
2.tf.contrib.learn.DNNClassifier 建立DNN模型(classifier)
3.classifer.fit 训练模型
4.classifier.evaluate 评价模型
5.classifier.predict 预测新样本
完整代码:

1 from __future__ import absolute_import 2 from __future__ import division 3 from __future__ import print_function 4 5 import tensorflow as tf 6 import numpy as np 7 8 # Data sets 9 IRIS_TRAINING = "iris_training.csv" 10 IRIS_TEST = "iris_test.csv" 11 12 # Load datasets. 13 training_set = tf.contrib.learn.datasets.base.load_csv_with_header( 14 filename=IRIS_TRAINING, 15 target_dtype=np.int, 16 features_dtype=np.float32) 17 test_set = tf.contrib.learn.datasets.base.load_csv_with_header( 18 filename=IRIS_TEST, 19 target_dtype=np.int, 20 features_dtype=np.float32) 21 22 # Specify that all features have real-value data 23 feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)] 24 25 # Build 3 layer DNN with 10, 20, 10 units respectively. 26 classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns, 27 hidden_units=[10, 20, 10], 28 n_classes=3, 29 model_dir="/tmp/iris_model") 30 31 # Fit model. 32 classifier.fit(x=training_set.data, 33 y=training_set.target, 34 steps=2000) 35 36 # Evaluate accuracy. 37 accuracy_score = classifier.evaluate(x=test_set.data, 38 y=test_set.target)["accuracy"] 39 print('Accuracy: {0:f}'.format(accuracy_score)) 40 41 # Classify two new flower samples. 42 new_samples = np.array( 43 [[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float) 44 y = list(classifier.predict(new_samples, as_iterable=True)) 45 print('Predictions: {}'.format(str(y)))
结果:
Accuracy:0.966667
二.在tf.contrib.learn中创建input函数(输入预处理函数)
格式:
def my_input_fn():
# Preprocess your data here...
# ...then return 1) a mapping of feature columns to Tensors with
# the corresponding feature data, and 2) a Tensor containing labels
return feature_cols, labels
其中,frature_cols是一个字典,包含键值对可以将特征中的列名集Tensor s中包含的特征数据对应起来。
而labels 则是一个包含你的标签值的张量。
那么如何将你的特征数据转换成张量?
如果你的特征、标签数据保存in pandas dataframes or numpy arrays, 保存你需要转换它们到张量s中before returning it form your input_fn.
对于连续的数据,你可以用tf.constant新建并填充张量;而对于稀疏、分类数据(数值多数是0),你可能需要用一个稀疏张量SparseTensor,它带有三个参数:【张量的形状,指明包含非零值的元素的位置,指明非零元素的值】
下面是一个对波士顿房屋价格的神经网络完整代码。在本教程的其余部分,你将预处理从UCI的波士顿房价数据集的子集,并将其输入到一个神经网络回归进行预测房价中间值功能
完整代码:

1 # Copyright 2016 The TensorFlow Authors. All Rights Reserved. 2 # 3 # Licensed under the Apache License, Version 2.0 (the "License"); 4 # you may not use this file except in compliance with the License. 5 # You may obtain a copy of the License at 6 # 7 # http://www.apache.org/licenses/LICENSE-2.0 8 # 9 # Unless required by applicable law or agreed to in writing, software 10 # distributed under the License is distributed on an "AS IS" BASIS, 11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 # See the License for the specific language governing permissions and 13 # limitations under the License. 14 """DNNRegressor with custom input_fn for Housing dataset.""" 15 16 from __future__ import absolute_import 17 from __future__ import division 18 from __future__ import print_function 19 20 import itertools 21 22 import pandas as pd 23 import tensorflow as tf 24 # set logging verbosity to INFO 25 tf.logging.set_verbosity(tf.logging.INFO) 26 #Define the column names for the data set in COLUMNS.To distinguish features from the label,also define FEATURES and LABEL. # Then read the three CSVs into pandas DataFrame s:
27 COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age", 28 "dis", "tax", "ptratio", "medv"] 29 FEATURES = ["crim", "zn", "indus", "nox", "rm", 30 "age", "dis", "tax", "ptratio"] 31 LABEL = "medv" 32 33 34 def input_fn(data_set): 35 feature_cols = {k: tf.constant(data_set[k].values) for k in FEATURES} 36 labels = tf.constant(data_set[LABEL].values) 37 return feature_cols, labels 38 39 40 def main(unused_argv): 41 # Load datasets 42 training_set = pd.read_csv("boston_train.csv", skipinitialspace=True, 43 skiprows=1, names=COLUMNS) 44 test_set = pd.read_csv("boston_test.csv", skipinitialspace=True, 45 skiprows=1, names=COLUMNS) 46 47 # Set of 6 examples for which to predict median house values 48 prediction_set = pd.read_csv("boston_predict.csv", skipinitialspace=True, 49 skiprows=1, names=COLUMNS) 50 51 # Feature cols 52 feature_cols = [tf.contrib.layers.real_valued_column(k) 53 for k in FEATURES] 54 55 # Build 2 layer fully connected DNN with 10, 10 units respectively. 56 regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols, 57 hidden_units=[10, 10], 58 model_dir="/tmp/boston_model") 59 60 # Fit 61 regressor.fit(input_fn=lambda: input_fn(training_set), steps=5000) 62 63 # Score accuracy 64 ev = regressor.evaluate(input_fn=lambda: input_fn(test_set), steps=1) 65 loss_score = ev["loss"] 66 print("Loss: {0:f}".format(loss_score)) 67 68 # Print out predictions 69 y = regressor.predict(input_fn=lambda: input_fn(prediction_set)) 70 # .predict() returns an iterator; convert to a list and print predictions 71 predictions = list(itertools.islice(y, 6)) 72 print("Predictions: {}".format(str(predictions))) 73 74 if __name__ == "__main__": 75 tf.app.run()
在学习深度网络框架的过程中,我们发现一个问题,就是如何输出各层网络参数,用于更好地理解,调试和优化网络?针对这个问题,TensorFlow开发了一个特别有用的可视化工具包:TensorBoard,既可以显示网络结构,又可以显示训练和测试过程中各层参数的变化情况。本博文分为四个部分,第一部分介绍相关函数,第二部分是代码测试,第三部分是运行结果,第四部分介绍相关参考资料。
一. 相关函数
TensorBoard的输入是tensorflow保存summary data的日志文件。日志文件名的形式如:events.out.tfevents.1467809796.lei-All-Series 或 events.out.tfevents.1467809800.lei-All-Series。TensorBoard可读的summary data有scalar,images,audio,histogram和graph。那么怎么把这些summary data保存在日志文件中呢?
数值如学习率,损失函数用scalar_summary函数。tf.scalar_summary(节点名称,获取的数据)
各层网络权重,偏置的分布,用histogram_summary函数
其他几种summary data也是同样的方式获取,只是对应的获取函数名称换一下。这些获取summary data函数节点和graph是独立的,调用的时候也需要运行session。当需要获取的数据较多的时候,我们一个一个去保存获取到的数据,以及一个一个去运行会显得比较麻烦。tensorflow提供了一个简单的方法,就是合并所有的summary data的获取函数,保存和运行只对一个对象进行操作。比如,写入默认路径中,比如/tmp/mnist_logs (by default)
SummaryWriter从tensorflow获取summary data,然后保存到指定路径的日志文件中。以上是在建立graph的过程中,接下来执行,每隔一定step,写入网络参数到默认路径中,形成最开始的文件:events.out.tfevents.1467809796.lei-All-Series 或 events.out.tfevents.1467809800.lei-All-Series。
二. 代码测试
三. 运行结果
代码运行
生成文件
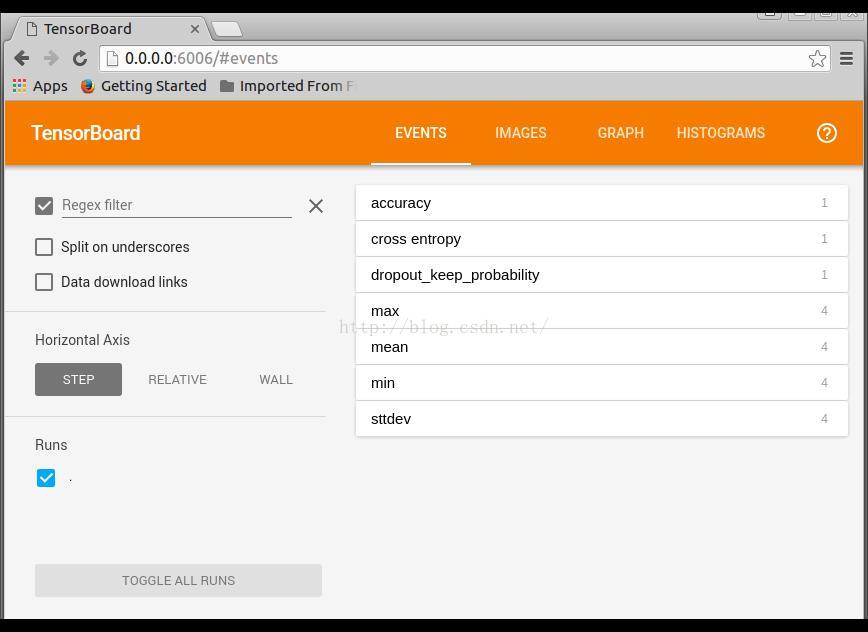
调用TensorBoard可视化运行结果

打开链接 http://0.0.0.0:6006
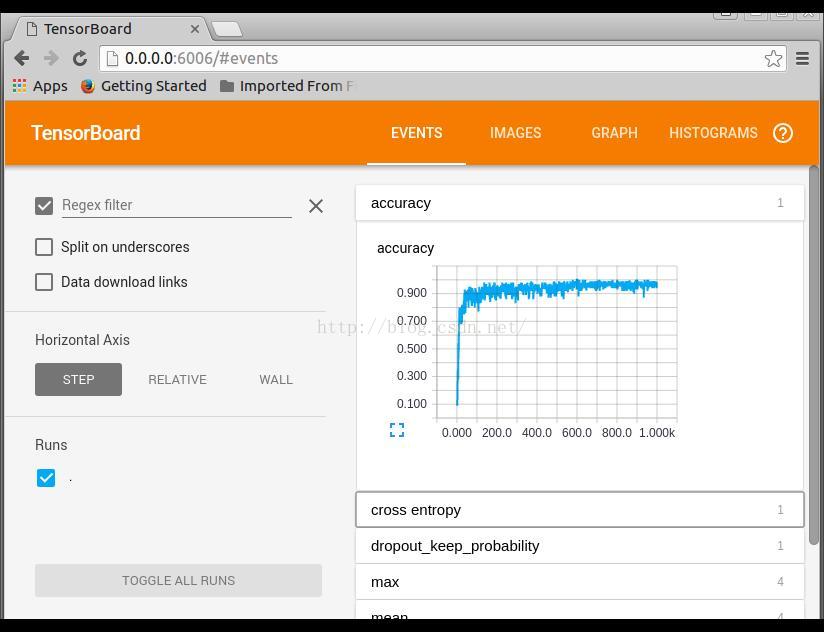
EVENTS是训练参数统计显示,可以看到整个训练过程中,各个参数的变换情况
IMAGES输入和输出标签,省略
GRAPH网络结构显示
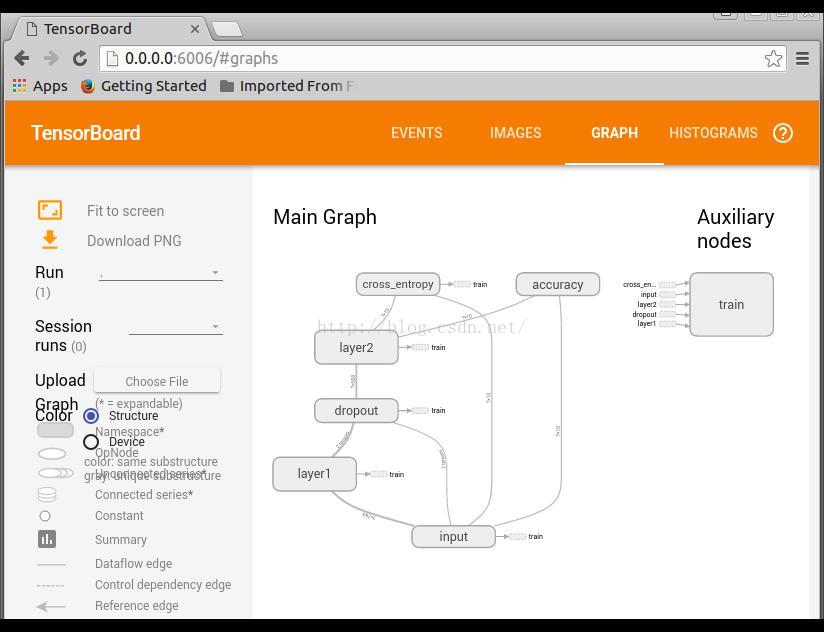
双击进去,可以显示更多的细节,包括右边的列表显示
HISTOGRAM训练过程参数分布情况显示
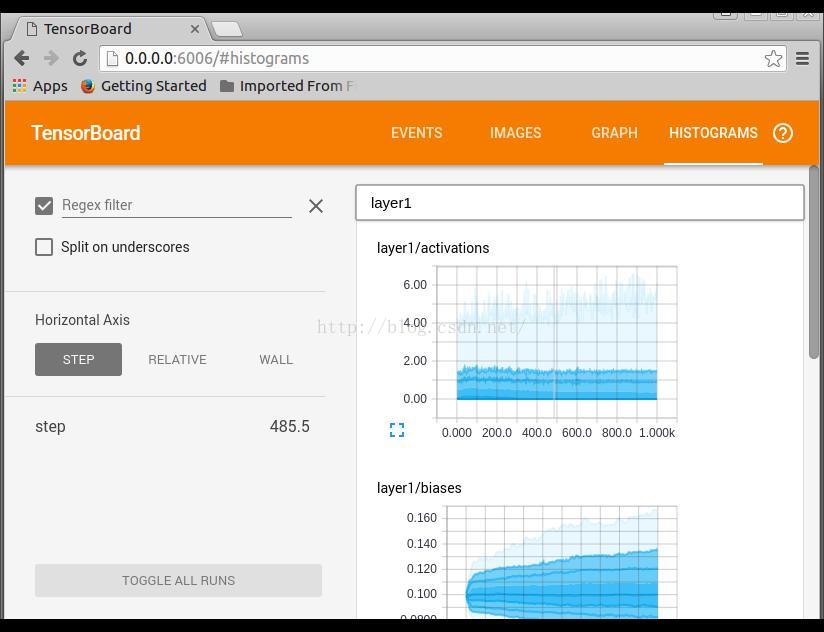
四. 参考资料
如果你想了解更多信息,可以参考一下资料:
https://www.tensorflow.org/versions/r0.9/how_tos/summaries_and_tensorboard/index.html
https://github.com/tensorflow/tensorflow/blob/r0.9/tensorflow/tensorboard/README.md
https://www.tensorflow.org/versions/r0.9/how_tos/graph_viz/index.html















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









