






通过这个案例来了解堆积面积图。
首先我们把数据先进行读取,注意数据的路径,有两种路径绝对路径和相对路径,个人根据自己的代码路径进行选择,一般的报错就是路径的问题。
import pandas as pd
data_mpv_sale = pd.read_excel('MPV销量数据2012-2021(1).xlsx')
data_mpv_sale
由于数据比较多,我们需要进行数据去重,数据去重这一步是不可省略的,后面如果有报错的话可能就是数据没有去重,"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。这一步是大多数人都要去做的,代码如下:
data_mpv_sale2 = data_mpv_sale.drop_duplicates(subset=['采集时间','排名'],keep='last')
data_mpv_sale2 = data_mpv_sale2.sort_values(by=['采集时间','排名'])
data_mpv_sale2数据去重后对数据进行加工,加工的目的是为了后面能够更加方便的使用代码,代码如下:
data_mpv_sale3 = data_mpv_sale2[data_mpv_sale2['采集时间']>'2017']
data_mpv_sale3['车型']
data_mpv_sale3['车型_厂商'] = data_mpv_sale3['车型'] + '_' + data_mpv_sale3['厂商']
data_mpv_sale3先复制一个表格对象,再进行时间数据加工,代码如下:
data_mpv_sale4 = data_mpv_sale3.copy() # 复制一个表格对象
data_mpv_sale4['年份'] = data_mpv_sale4['采集时间'].agg(lambda x:int(x[:4]))
data_mpv_sale4['月份'] = data_mpv_sale4['采集时间'].agg(lambda x:int(x[-2:]))
def jidu(month):
if month<=3:
return 1
elif month<=6:
return 2
elif month<=9:
return 3
else:
return 4
data_mpv_sale4['季度'] = data_mpv_sale4.loc[:,'月份'].agg(jidu)
data_mpv_sale4['年份_季度'] = data_mpv_sale4['年份'].agg(lambda x:str(x)+'年') + data_mpv_sale4['季度'].agg(lambda x:str(x)+'季度')
data_mpv_sale4得到的结果如下,如果报错就根据报错的信息进行仔细观察自己的代码是否有误。
重新聚合车辆季度销量,把前面的厂商、季度和销量进行聚合,这样就能够
sale_season = data_mpv_sale4.groupby(by=['车型_厂商','年份_季度'])['销量'].sum()
sale_season定位销量头部车型:
sale_total20 = data_mpv_sale4.groupby(by=['车型_厂商'])['销量'].sum().sort_values(ascending=False)[:10].index.values
sale_total20最后重组数据结构,这里先用for循环对时间进行定义,再把车辆的季度销量信息存储下来,最后就是堆积面积图的相关代码,设计面积图的大小后把前面的数据给输入进来就可以得到最终的结果了,要注意函数的格式不能随便的进行空格和缩进,如果有报错就检查一下看看格式有没有问题:
# 定义时间列表
year = [2017,2018,2019,2020,2021]
season = [1,2,3,4]
list_time = []
for y in year:
for s in season:
if y==2021 and s>=3:
break
else:
list_time.append(f'{y}年{s}季度')
list_time# 定义字典存储20辆车的季度销量信息
sale_dict = {}
for c in sale_total20:
sale_dict.setdefault(c,[]) # 创建键:c,值:[]
for t in list_time:
if t in sale_season[c].index:
sale_dict[c].append(int(sale_season[c][t]))
else:
sale_dict[c].append(0) # 没有销量记录的季度需要手动填入0
sale_dictimport pyecharts.options as opts
from pyecharts.charts import Line
c = (
Line(init_opts=opts.InitOpts(width='800px',height='400px'))
.add_xaxis(xaxis_data=list_time)
.set_global_opts(
# title_opts=opts.TitleOpts(title="2017-2021年MPV销量前10名车型走势"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), # 配置提示框
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
datazoom_opts=opts.DataZoomOpts(), # 配置滑动条
)
)
for name,sale_list in sale_dict.items():
c.add_yaxis(
series_name=name, # 序列名称,由车型名称定义
stack="总量", # 设置堆积图
y_axis=sale_list, # 销量数据
areastyle_opts=opts.AreaStyleOpts(opacity=0.5), # 设置面积图
label_opts=opts.LabelOpts(is_show=False),
is_smooth = True, # 显示平滑曲线
)
c.render_notebook()
# c.render('2017-2021年MPV销量前10名车型走势.html')最后结果如下: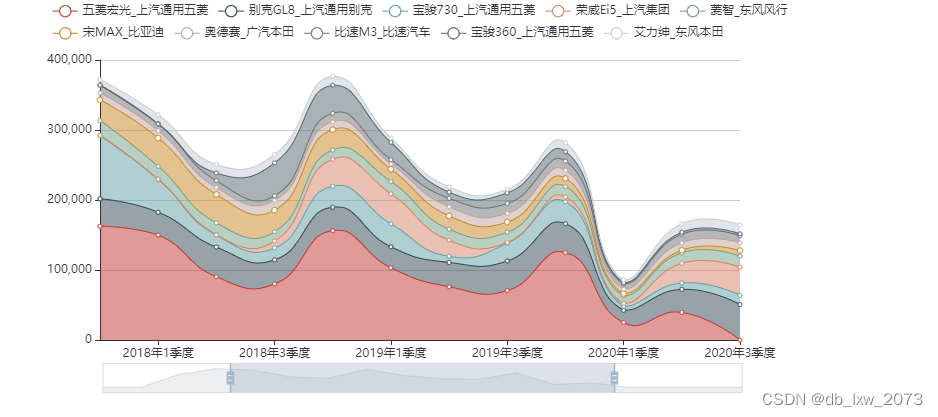
通过这个案例我了解到堆积面积图的优点和如何去使用堆积面积图,堆积面积图可以直观地展示多个变量之间的比例和趋势;可以同时展示多个变量的总和和每个变量的贡献程度。















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









