







Graph Contrastive Learning with Adaptive Augmentation
摘要
数据增强方案应该保留图的内在结构和属性,这将迫使模型学习对不重要的节点和边缘的扰动不敏感的表示。
提出了一种新的具有自适应增强的图对比表示学习方法,该方法包含了图的拓扑和语义方面的各种先验。
具体来说,在拓扑层面上,设计了基于节点中心性度量的增强方案来突出重要的连接结构。
在节点属性级别上,通过向不重要的节点特征添加更多的噪声来破坏节点特征,以强制模型识别底层的语义信息。
引言
图表示学习主要用于分析图结构的数据。通常利用图神经网络(Graph Neural Networks,GNN)进行图表示学习,其目的是将节点转换为低维密集嵌入,以保留图的属性和结构特征。现有GNN模型多以监督的方式建立,需要大量的标记节点进行训练。对比学习是通过对比正样本对和负样本对,寻求最大化输入(即图像)与其表示(即图像嵌入)之间的相互信息(Mutual Information,MI)。
CL中的一个关键组成部分是图增强方法。现有的图增强方法有两个缺点:
1.在结构域或属性域中进行简单的数据增强不足以生成不同的邻域(上下文),特别是当节点特征稀疏时,导致难以优化对比目标。
2.以往的工作忽略了在进行数据扩充时节点和边缘影响的差异。例如,如果我们通过均匀地删除边来构造图视图,去除一些有影响的边会降低嵌入质量。
由于对比目标学习到的表示对数据增强方案引起的破坏往往是不变的,因此数据增强策略应该自适应输入图,以反映其内在模式。
通过对输入执行随机破坏来生成两个相关的图视图。然后,我们使用对比损失来训练模型,以最大化这两个视图中节点嵌入之间的一致性。具体地说,我们提出了一种在拓扑和节点属性级别上的联合自适应数据增强方案,即去除边缘和掩蔽特征,为不同视图中的节点提供不同的上下文,从而促进对比目标的优化。此外,我们通过中心性度量来识别重要的边缘和特征维度.在拓扑层次上,我们通过给不重要的边自适应的去除概率,以突出重要的连接结构。在节点属性级别上,我们通过向不重要的特征维度添加更多的噪声来破坏属性,以强制模型识别底层的语义信息。
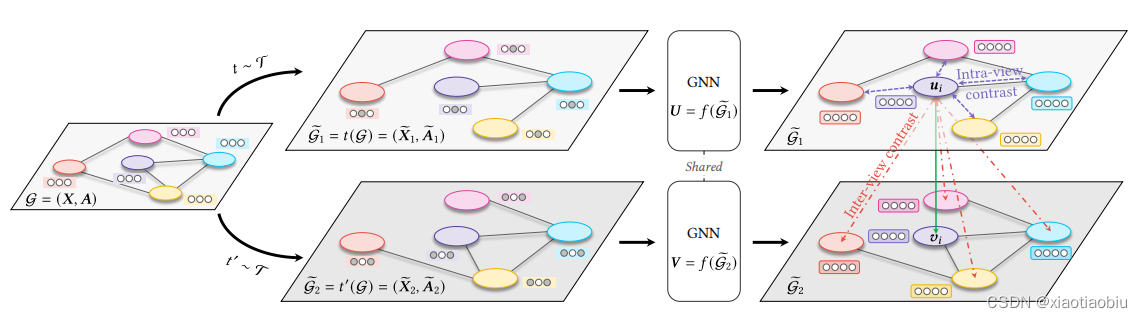 图1:我们提出的深度图对比表示学习与自适应增强(GCA)模型。我们首先通过自适应图的结构和属性的随机增强来生成两个图的视图。然后,将这两个图输入一个共享的图神经网络(GNN)来学习表示。我们用一个对比目标来训练模型,它将一个节点的表示拉在一起,同时将节点表示与两个视图中的其他节点表示推开。注意,我们将负样本定义为两个视图中的所有其他节点。因此,阴性样本来自两个来源,即视图内节点(紫色)和视图间节点(红色)。
图1:我们提出的深度图对比表示学习与自适应增强(GCA)模型。我们首先通过自适应图的结构和属性的随机增强来生成两个图的视图。然后,将这两个图输入一个共享的图神经网络(GNN)来学习表示。我们用一个对比目标来训练模型,它将一个节点的表示拉在一起,同时将节点表示与两个视图中的其他节点表示推开。注意,我们将负样本定义为两个视图中的所有其他节点。因此,阴性样本来自两个来源,即视图内节点(紫色)和视图间节点(红色)。
核心贡献
1.提出了一个通用的对比框架的无监督图表示学习与强,自适应的数据增强。所提出的GCA框架在自适应图结构和属性的拓扑结构和属性级别上共同执行数据增强,这鼓励了模型从这两个方面学习重要的特征。
2.利用常用的线性基准数据集对节点分类进行全面的实证研究。GCA始终优于现有的方法,我们的无监督方法甚至在几个转换任务上优于有监督的方法。
相关工作
DGI GMI MVGRL
方法
1.准备工作

2.对比学习框架
模型寻求最大限度地提高不同视图之间的表示一致性。
①首先通过对输入执行随机图增强来生成两个图视图。
②采用了一个对比目标,强制每个节点在两个不同视图中的编码嵌入彼此一致,并可以与其他节点的嵌入区分开来。
方法:对于任意节点𝑣𝑖,其在一个视图𝒖𝑖中生成的嵌入都被视为锚点(命名标记),其在另一个视图𝒗𝑖中生成的嵌入形成正样本,而两个视图中的其他嵌入自然被视为负样本。
将每个正样本对(𝒖𝑖,𝒗𝑖)的目标函数定义为:

公式说明:给定一个正样本对,我们自然地将负样本定义为两个视图中的所有其他节点。因此,负样本来自两个来源,即视图间节点和视图内节点,分别对应于等式中分母中的第二项和第三项。由于两个视图是对称的,因此另一个视图的损失同样被定义为ℓ(𝒗𝑖,𝒖𝑖)。
总体目标函数定义为所有正样本对的平均值,即:
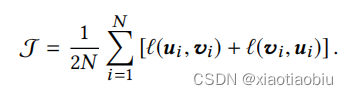
GCA训练算法如下:

算法说明:第1步,第2步对两个随机增广函数t ~ t和t’ ~ t进行抽样;通过对G执行破坏,生成两个图视图S1 = t(G)和G2 = t’(G);利用编码器f获得G1的节点嵌入量U;利用编码器f获得g2的节点嵌入量V;利用Eq.(2)计算对比目标J;采用随机梯度上升方法更新参数,使J最大化
3.自适应图增强
想法:在GCA模型中,我们建议设计增强方案,以倾向于保持重要的结构和属性不变,同时干扰可能不重要的链接和特征。
具体做法:通过随机移除边和掩蔽节点来破坏输入图中的特征,以及去除或掩盖的概率对于不重要的边或特征较高,对于重要的边或特征较低。
目的:更强调重要的结构和属性,而不是随机损坏的视图,这将指导模型保持基本的拓扑和语义图模式。
3.1 拓扑级别的增强

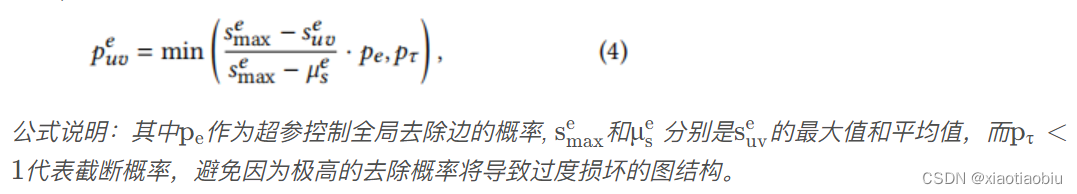
对于节点中心度函数的选择,本文使用中心度、特征向量中心度和PageRank中心度这三个度量方法。
中心度。节点度本身可以是一个中心度量。在有向网络上使用入度,因为有向图中的一个节点的影响主要是由指向的节点所赋予的。优点:最简单、有效。缺点:所有相邻节点对该节点的重要性相同。
例如,在引文网络中,节点代表论文,边缘代表引文关系,度最高的节点很可能对应于有影响力的论文。
特征向量中心度。一个节点的特征向量中心度计算为其对应邻接矩阵的最大特征值的特征向量。优点:连接到多个相邻节点或连接到有影响的节点的节点将具有较高的特征向量中心度。
PageRank中心度。PageRank中心度定义为由PageRank算法计算的PageRank权重。优点:该算法沿有向边传播影响,将受影响量最大的节点视为重要节点。
三种方法的边中心度可视化:
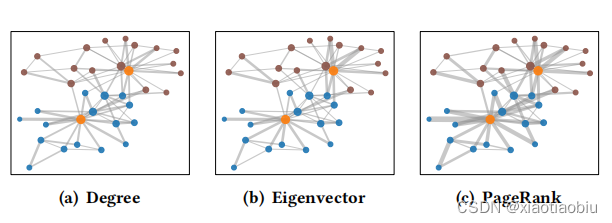
数据集:空手道俱乐部数据集,分别包含由两名教练领导的两组学生。
虽然三种方案表现出细微的差异,但所有的增强方案都倾向于强调连接两组内两个教练(橙色)的边缘,而较少关注组间外围节点之间的连接。这验证了所提出的基于节点中心性的自适应拓扑增强方案可以识别图的基本结构。
3.2 节点属性级增强


实验
通过三个问题评估模型
• RQ1.我们提出的GCA在节点分类方面是否优于现有的基线方法?
• RQ2.所有提出的自适应图增强方案都有利于模型的学习?每个图的增强方案是如何影响模型的性能?
• RQ3.所提出的模型对超参数敏感吗?关键超参数如何影响模型的性能?
数据集
Wiki-CS1、 Amazon-Computers2、Amazon-Photo3、Coauthor-CS4、 Coauthor-Physics5
baseline
基线我们考虑代表性基线方法属于以下两类: (1)传统方法包括noee2vec[11]和(2)深度学习方法包括图自动编码器(GAE,VGAE)[22],深度图Infomax(DGI)[45],图形互信息最大化(GMI)[32],和多视图图表示学习(MVGRL)[16].此外,我们报告了使用逻辑回归分类器对原始节点特征和深度行走与嵌入连接到输入节点特征所获得的性能。为了直接比较我们提出的方法与有监督的方法,我们还报告了两个代表性模型图卷积网络(GCN)[23]和图注意网络(GAT)[44]的性能,其中它们以端到端方式进行训练。对于所有的基线,我们将根据它们的官方实现来报告它们的性能。
实施细节
由于其简单性,我们使用了一个两层的GCN [23]作为所有深度学习基线的编码器。
RQ1:
在两种转换任务中,GCA的表现始终优于无监督基线。其强大的性能验证了所提出的对比学习框架的优越性。在两个合著者数据集上,我们注意到现有的基线已经获得了足够高的性能;我们的方法GCA仍然推动边界。
在学习嵌入时能够合并节点特征。
提出的方法在构建负样本时具有较强的自适应数据增强,从而获得更好的性能。
GCA的优越性能验证了我们提出的自适应数据增强方案能够通过在扰动时保留重要的模式来帮助提高嵌入质量。
所有具有不同节点中心性度量的三个变量在所有数据集上都优于现有的对比基线。
我们的模型并不局限于中心性措施的具体选择,并验证了我们所提出的框架的有效性和通用性。
与现有的先进方法相比,GCA的优越性能验证了我们提出的GCA框架的有效性,该框架执行自适应图结构和属性的数据增强。
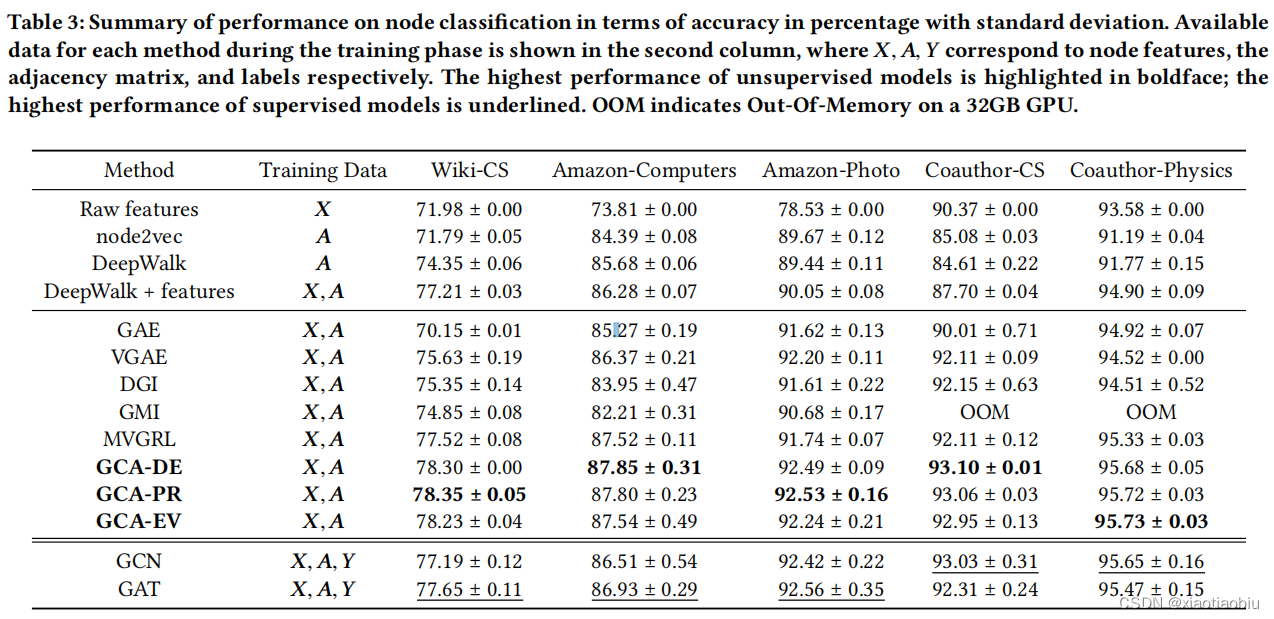
性能总结如表3所示。其中𝑿、𝑨、𝒀分别对应于节点特征、邻接矩阵和标签;无监督模型的最高性能以黑体突出显示;OOM表示在一个32GB的GPU上的内存不足。
总结:
(1)我们提出的模型在所有五个数据集上都显示出了强大的性能,始终优于无监督基线,验证了所提出的对比学习框架的优越性。
(2)在某些数据集(Wiki-CS)上,GAE 的性能比 DeepWalk+feature 更差,这归因于它们选择负样本的简单方法,即简单地基于边缘选择对比对。这一事实进一步证明了基于增强图视图在对比表示学习选择负样本的重要作用。
(3)MVGRL使用扩散来将全局信息合并到增强的视图中,但它仍然没有自适应地考虑不同的边对输入图的影响。实验结果验证了我们提出的自适应数据增强方案能够通过在扰动时保留重要的信息来提高嵌入质量。
RQ2:
结果验证了我们的自适应增强方案在拓扑结构和节点属性层次上的有效性。
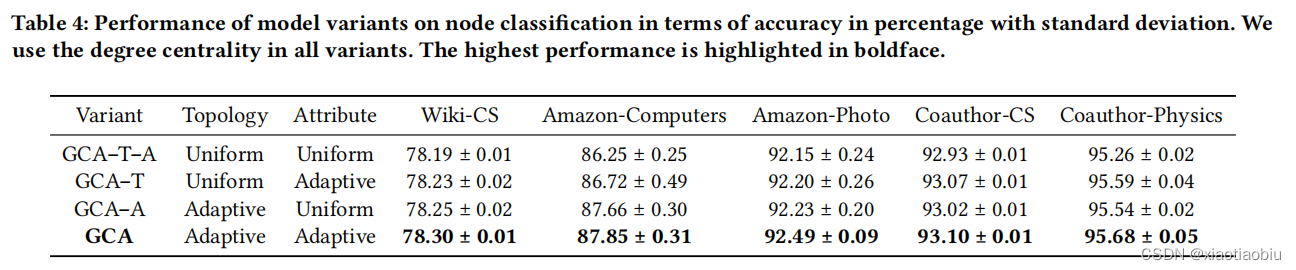
GCA-T-A 表示具有统一拓扑和节点属性增强方案的模型,其中所有节点的丢弃边和掩蔽特征的概率被重置为相同的。变种 GCA-T 和 GCA-A 的定义类似,所有的变种都使用了中心度方法。
结论:拓扑级和节点属性级自适应增强方案在所有数据集上都一致地提高了模型性能。
RQ3:
当参数不太大时,节点分类的精度性能相对稳定
我们的模型对这些概率不敏感,证明了对超参数扰动的鲁棒性。
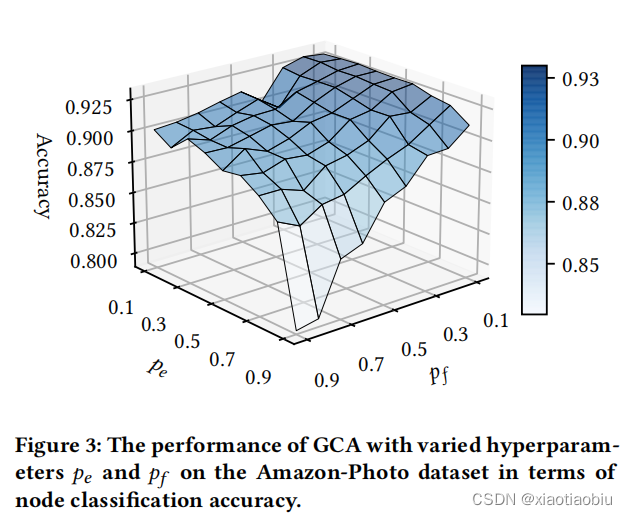
不同超参数pe和pf的GCA在Amazon-Photo数据集上节点分类精度的性能
结论:从图中可以看出,当参数不太大时,节点分类的精度性能相对稳定,如图中的平台所示。因此,我们得出结论,总的来说,我们的模型对这些概率不敏感,证明了对超参数扰动的鲁棒性。如果概率设置得太大(例如,>0.5),原始图将被严重破坏。例如,当𝑝𝑒=0.9时,几乎所有现有的边都已被删除,从而导致生成的图视图中出现孤立的节点。在这种情况下,GNN很难从节点邻域学习有用的信息。因此,学习到的两个图视图中的节点嵌入不够独特,这将导致优化对比目标的困难。
结论
在本文中,我们开发了一种新的具有自适应增强的图对比表示学习框架。我们的模型通过最大化由自适应图增强生成的视图之间的节点嵌入的一致性来学习表示。所提出的自适应增强方案首先通过网络中心性度量来识别重要的边缘和特征维度。然后,在拓扑层次上,我们通过在不重要的边缘上分配较大的概率来随机去除边缘,以强制模型识别网络连接模式。在节点属性级别上,我们通过向不重要的特征维度添加更多的噪声来破坏属性,以强调底层的语义信息。我们已经使用各种真实世界的数据集进行了全面的实验。实验结果表明,我们提出的GCA方法始终优于现有的最先进的方法,甚至超过了一些有监督的方法。















 2408
2408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









