







摘要
我们提出了DGI,一种以无监督的方式学习图结构数据中的节点表示的一般方法。DGI依赖于最大限度地扩大图增强表示和目前提取到的图信息之间的互信息——两者都是使用已建立的图卷积网络架构推导出来的。对于图增强表示,是根据目标节点所生成的子图,因此可以在下游的节点级学习任务中重用。与之前大多数使用GCNs的无监督学习方法相比,DGI不依赖于随机行走目标,并且很容易适用于直推式学习和归纳式学习。我们在各种节点分类基准上演示了竞争性能,这有时甚至超过了监督学习的性能。
1 Introduction
大多数成功的方法使用监督学习,这通常是不可能的,因为野外的大多数图形数据是未标记的。此外,我们通常希望从大规模图中发现新颖或有趣的结构,因此,无监督图学习对于许多重要的任务都是必不可少的。
目前,利用图结构数据进行无监督表示学习的主要算法依赖于基于随机行走的目标,有时进一步简化以重建邻接信息。基本的直觉是训练编码器网络,使输入图中的“接近”节点在表示空间中也“接近”。
随机游走目标缺点:以牺牲结构信息为代价过度强调接近信息,而性能高度依赖于超参数选择。目前尚不清楚随机行走目标是否真的提供任何有用的信号,因为这些编码器已经执行感应偏差,相邻节点有类似的表示。
提出了一个基于互信息而不是随机游走的无监督图学习的替代目标。
DIM在图像数据中严重依赖于卷积神经网络结构,据我们所知,目前还没有任何工作将互信息最大化应用于图结构的输入。我们将来自DIM的思想调整到图域,这可以被认为具有比卷积神经网络捕获的更一般的结构类型。
2 Related Work
对比方法
DGI在这方面也是相反的,因为我们的目标是基于局部-全局对和负采样对的分类。
抽样策略
从语言建模的角度来看,正样本通常对应于在图中短时间的随机游走中一起出现的节点对,有效地将节点视为单词,将随机游走视为句子。最近有的方法提出使用节点锚定采样作为替代。这些方法的负采样主要是基于随机对的抽样。
预测编码
与我们的方法不同的是,CPC和上面的图方法都是预测的:对比目标有效地训练了输入的结构指定部分之间(例如,相邻节点对之间或节点与其邻居之间)的预测器。我们的方法的不同之处在于,我们同时对比了一个图的全局/局部部分,其中全局变量是由所有的局部变量计算出来的。
3 DGI Methodology
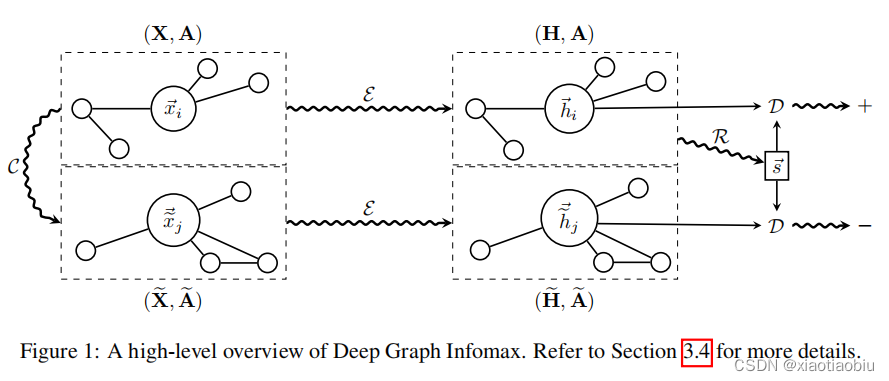
在本节中,我们将以自上而下的方式介绍DGI方法:首先是对我们特定的无监督学习设置的抽象概述,然后是对我们的方法优化的目标函数的阐述,最后是在单图设置中枚举我们过程的所有步骤。
基于图的无监督学习

局部-全局互信息最大化


DGI概述

4 Classification Performance
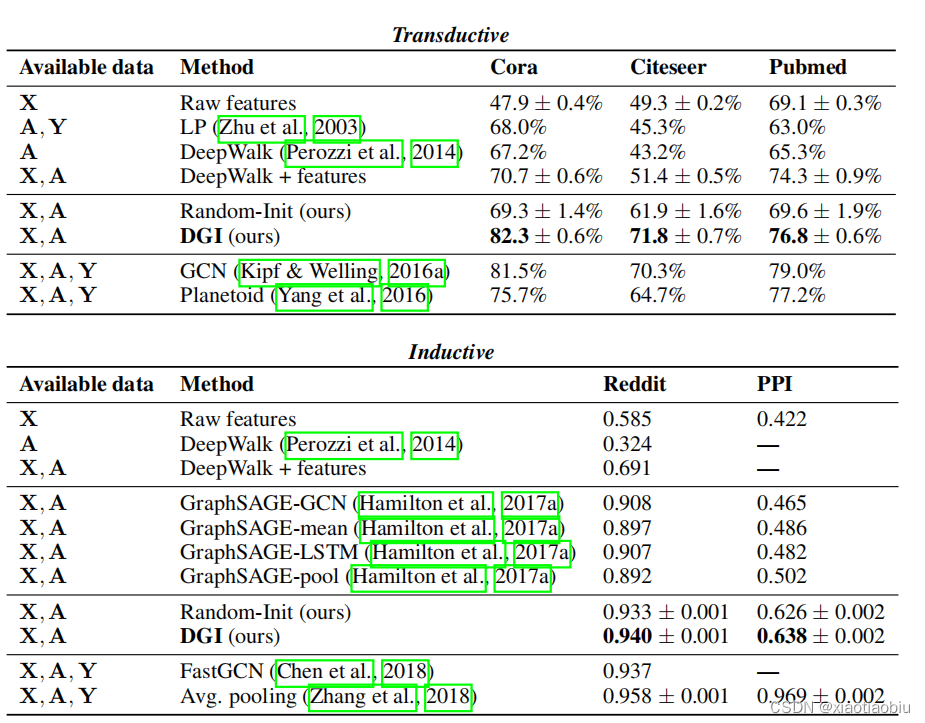
我们评估了DGI编码器在各种节点分类任务(直推式学习和归纳式学习)上学习的表示的好处,获得了有竞争力的结果。在每种情况下,DGI都被用来以完全无监督的方式学习patch representations,然后评估这些表示的节点级分类效用。这是通过直接使用这些表示来训练和测试一个简单的线性(逻辑回归)分类器来实现的。
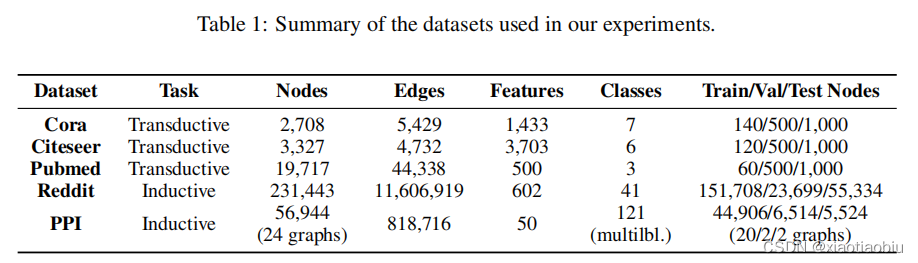
(1)在Cora、Citeseer和Pubmed引文网络上对研究论文进行主题分类。
(2)以Reddit帖子为模型预测社交网络的社区结构。
(3)对蛋白质-蛋白质相互作用(PPI)网络中的蛋白质作用进行分类,需要对未见网络进行归纳。
对于三个实验设置(直推式学习、大图上的归纳式学习和多图上的归纳式学习)中的每一个,我们使用了与该设置相适应的不同编码器和corruption function。
- 直推式学习
编码器是一层图卷积网络(GCN)模型,具有以下传播规则:
5 Qualitative Analysis
揭示了对DGI的学习机制的见解,隔离了有偏见的嵌入维度来降低负面例子的分数,并使用剩下的部分来编码关于正面例子的有用信息。我们利用这些见解来保持对有监督的GCN的竞争性能,即使从编码器提供的补丁表示中删除了一半的维度。

2. 大图上的归纳式学习
对于归纳学习,不再在编码器中使用GCN更新规则(因为学习的滤波器依赖于固定的和已知的邻接矩阵);相反,我们应用平均池( mean-pooling)传播规则,GraphSAGE-GCN:



在这个多图设置中,DGI 选择使用随机抽样的训练图作为负样本(即,DGI 的破坏函数只是从训练集中抽样一个不同的图)。作者发现该方法是最稳定的,因为该数据集中超过40%的节点具有全零特征。为了进一步扩大负样本池,作者还将dropout应用于采样图的输入特征。作者发现,在将学习到的嵌入信息提供给逻辑回归模型之前,将其标准化是有益的。

结果
6 Conclusions
我们提出了DGI,一种学习图结构数据上的无监督表示的新方法。通过利用通过强大的图卷积架构获得的图的增强表示中的局部互信息最大化,我们能够获得考虑到图的全局结构特性的节点嵌入。这使得在各种直推式学习和归纳式学习中都具有竞争性的性能,有时甚至优于相关的监督架构。














 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









