










代码链接:https://github.com/CRIPAC-DIG/GCA
摘要
近年来,对比学习(CL)已成为一种成功的无监督图表示学习方法。大多数图CL方法首先对输入图进行随机增强,以获得两个图视图,并最大限度地提高两个视图的表示一致性。尽管图CL方法的蓬勃发展,但图增强方案的设计——CL中的一个关键组成部分——仍然很少被探索。
我们认为,数据增强方案应该保留图的内在结构和属性,使模型学习对不重要节点和边缘的扰动不敏感的表示。然而,现有的方法大多采用统一的数据增强方案,如均匀的丢弃边和统一的清洗特征,导致性能次优。
在本文中,我们提出了一种新的具有自适应增强的图对比表示学习方法,该方法包含了图的拓扑和语义方面的各种先验。
具体来说,在拓扑层面上,我们设计了基于节点中心性度量的增强方案来突出重要的连接结构。在节点属性层面上,我们通过向不重要的节点特征添加更多的噪声来破坏节点特征,以强制模型识别底层语义信息。
我们在各种真实世界的数据集上进行了广泛的节点分类实验。实验结果表明,我们提出的方法始终优于现有的最先进的基线,甚至超过了一些有监督的基线,这验证了自适应增强对比框架的有效性。
1 引言
DGI、GMI、MVGRL等数据增强方法的缺点:
- 结构域或属性域中的简单数据增强,如DGI中的特征转换,都不足以为节点生成不同的邻域(即上下文),特别是当节点特征稀疏时,导致难以优化对比目标。
- 以前的工作忽略了在执行数据增强时节点和边缘影响的差异。例如,如果我们通过均匀地掉边来构造视图,去除一些有影响的边会降低嵌入质量。
由于对比目标学习到的表示往往对数据增强方案引起的corruption是不变的,数据增强策略应该自适应【学习重要性】输入图,以反映其内在模式。
本文提出的GCA框架如图1所示:
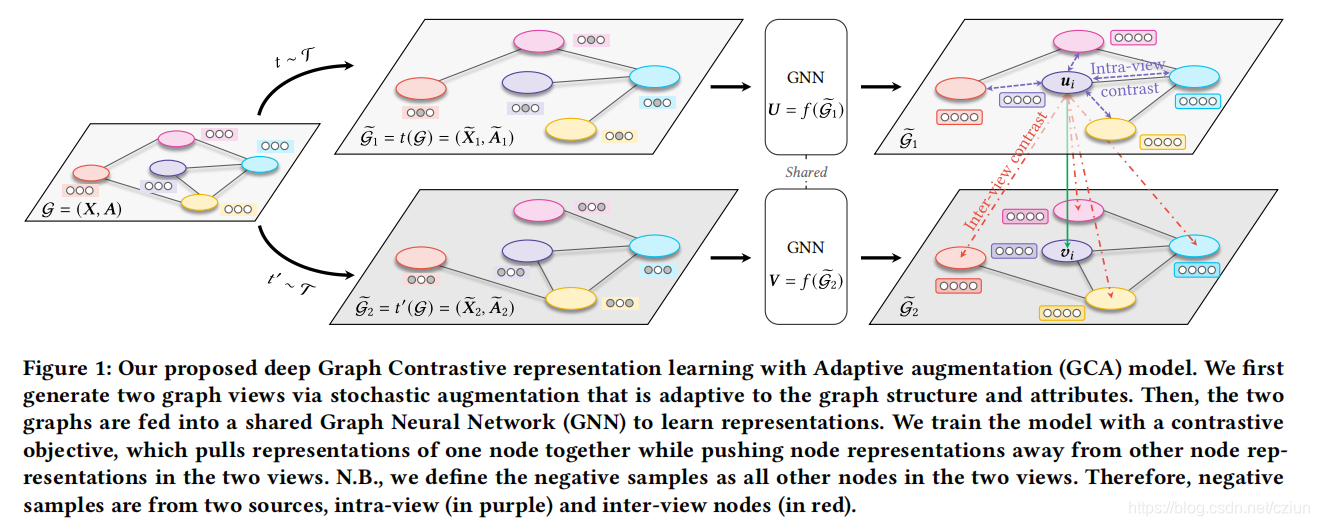
整体过程和之前的GRACE等一样,不同之处在于数据增强以产生两个视图的方法。
具体来说,我们在拓扑和节点属性级别上提出了一种联合的自适应数据增强方案,即去除边缘和掩蔽特征,为不同视图中的节点提供不同的上下文,以促进对比目标的优化。
此外,我们通过中心性度量来识别重要的边缘和特征维度。
然后,在拓扑层面上,我们通过给不重要的边很大的去除概率来自适应地掉边,以突出重要的连接结构。在节点属性层面上,我们通过向不重要的特征维度添加更多的噪声来破坏属性,以强制模型识别底层的语义信息。
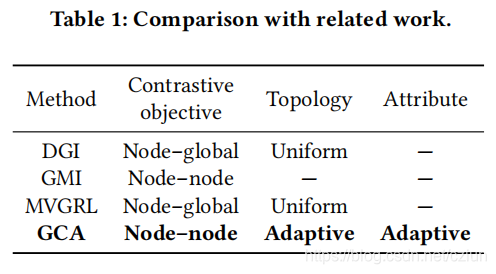
2 相关工作
3 方法
3.1 准备工作
G = { V , E } \mathcal{G}=\{\mathcal{V},\mathcal{E}\} G={V,E}, V = { v 1 , v 2 , . . . , v N } \mathcal{V}=\{v_1,v_2,...,v_N\} V={v1,v2,...,vN}, E ⊆ V × V \mathcal{E}⊆\mathcal{V}×\mathcal{V} E⊆V×V。
特征矩阵: X ∈ R N × F \pmb{X}∈\mathbb{R}^{N×F} XXX∈RN×F,其中 x i ∈ R F \pmb{x}_i∈\mathbb{R}^F xxxi∈RF是节点 v i v_i vi的特征。
邻接矩阵: A ∈ { 0 , 1 } N × N \pmb{A}∈\{0,1\}^{N×N} AAA∈{0,1}N×N,当 ( v i , v j ) ∈ E (v_i,v_j)∈\mathcal{E} (vi,vj)∈E时, A i j = 1 \pmb{A}_{ij}=1 AAAij=1。
在无监督设置下进行训练时, G \mathcal{G} G中没有给定节点的类别信息。
目标是学习一个GNN编码器 f ( X , A ) ∈ R N × F ′ f(\pmb{X},\pmb{A})∈\mathbb{R}^{N×F'} f(XXX,AAA)∈RN×F′,输入图的特征和结构,输出低维节点嵌入,即 F ′ < < F F'<<F F′<<F。
将 H = f ( X , A ) \pmb{H}=f(\pmb{X},\pmb{A}) HHH=f(XXX,AAA)作为节点学习到的表示,其中 h i \pmb{h}_i hhhi是节点 v i v_i vi的嵌入。这些表示可以用于下游任务中,如节点分类和社区检测。
3.2 对比学习框架
将每个正对
(
u
i
,
v
i
)
(\pmb{u}_i,\pmb{v}_i)
(uuui,vvvi)的成对目标定义为:
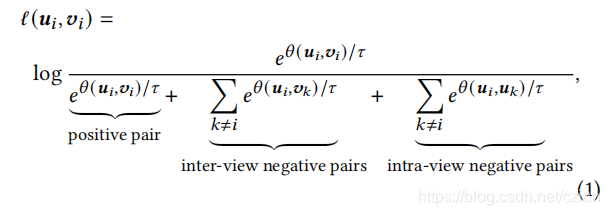
其中,
θ
(
u
,
v
)
=
s
(
g
(
u
)
,
g
(
v
)
)
\theta(\pmb{u},\pmb{v})=s(g(\pmb{u}),g(\pmb{v}))
θ(uuu,vvv)=s(g(uuu),g(vvv)),
s
s
s为余弦相似度,
g
g
g是一个非线性映射——两层的MLP,以增强表达能力。
总体目标:
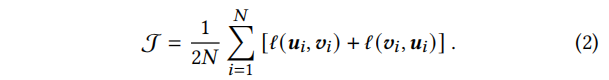
学习算法总结如下(整体同GRACE):

3.3 自适应图增强
在GCA模型中,我们提出设计增强方案,以保持重要的结构和属性不变,同时干扰可能不重要的连接和特征。
具体来说,我们通过随机删除边和屏蔽节点特征来破坏输入图,并且不重要的边或特征的去除或掩蔽概率是倾斜的,即不重要的边或特征的概率较高,重要的边或特征的概率较低。
3.3.1 拓扑级增强
对于拓扑级增强,我们考虑了一种破坏输入图的直接方法,即随机删除图中的边。在形式上,我们从原来的
E
\mathcal{E}
E中以下面的概率抽样一个修改后的子集
E
~
\widetilde{\mathcal{E}}
E
:
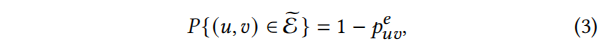
然后将
E
~
\widetilde{\mathcal{E}}
E
作为生成的视图中的边集。
p
u
v
e
p^e_{uv}
puve应该反映边
(
u
,
v
)
(u,v)
(u,v)的重要性,这样增强函数更有可能损坏不重要的边,同时在增强视图中保持重要的连接结构的完整。
在网络科学中,节点中心性是一种广泛使用的量化图中节点影响的方法。我们为边缘 ( u , v ) (u,v) (u,v)定义了边缘中心性 w u v e w^e_{uv} wuve,以基于两个连接节点的中心性来度量其影响。给定一个节点中心性度量 φ c ( ⋅ ) : V → R + \varphi _c(·):\mathcal{V}→\mathbb{R}^+ φc(⋅):V→R+,我们将边缘中心性定义为两个相邻节点的中心性得分的平均值,即 w u v e = ( φ c ( u ) + φ c ( v ) ) / 2 w^e_{uv}=(\varphi _c(u)+\varphi _c(v))/2 wuve=(φc(u)+φc(v))/2,并且在有向图上,我们简单地使用尾节点的中心性,即 w u v e = φ c ( v ) w^e_{uv}=\varphi _c(v) wuve=φc(v),由于边的重要性通常以它们所指向的节点为特征。
接下来,我们根据每条边缘的中心性值来计算它的概率。由于节点中心性值(如度)可能因不同的数量级而变化,因此我们首先设置
s
u
v
e
=
l
o
g
w
u
v
e
s^e_{uv}=log w^e_{uv}
suve=logwuve以减轻具有高密度连接的节点的影响。然后,可以在将节点中心性值转换为概率的归一化步骤后得到概率,定义如下:
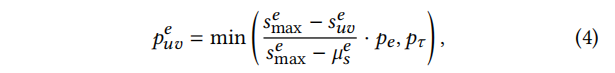
其中,
p
e
p_e
pe是一个控制边去除的总体概率的超参数,
s
m
a
x
e
s^e_{max}
smaxe和
μ
s
e
\mu^e_s
μse是
s
u
v
e
s^e_{uv}
suve的最大值和平均值。
p
τ
<
1
p_{\tau}<1
pτ<1是一个截止概率,用于截断概率,因为极高的去除概率将导致过度损坏的图结构。
对于节点中心性函数的选择,我们使用了以下三个中心性度量,包括度中心性、特征向量中心性和PageRank中心性。
(1)Degree centrality
节点度本身可以是一个中心性度量。在有向网络上,我们使用入度,因为有向图中节点的影响大多是由指向它的节点赋予的。尽管节点度是最简单的中心性度量之一,但它是相当有效和具有启发性的。例如,在引文网络中,节点代表论文,边缘代表引文关系,度最高的节点很可能对应于有影响力的论文。
(2)Eigenvector centrality
将节点的特征向量中心性计算为其对应于邻接矩阵最大特征值的特征向量。不像度中心性假设所有邻居对节点的重要性贡献相同那样,特征向量中心性考虑了相邻节点的重要性。根据定义,每个节点的特征向量中心性与其邻居的中心性之和成正比,连接到多个邻居或连接到有影响节点的节点将具有较高的特征向量中心性值。在有向图上,我们使用右边的特征向量来计算中心性,它对应于输入的边。请注意,由于只需要前导特征向量,因此计算特征向量中心性的计算负担可以忽略不计。
(3)PageRank centrality
PageRank中心性定义为由PageRank算法计算的PageRank权重。该算法沿着有向边传播影响,收集了最大的影响的节点被视为重要节点。在形式上,中心性值计算如下:
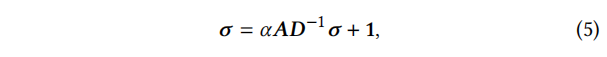
其中,
σ
∈
R
N
\sigma∈\mathbb{R}^N
σ∈RN是每个节点的PageRank中心性得分的向量。
α
α
α是一个阻尼因子,它可以防止图中的sinks从连接到它们的节点中吸收所有ranks。我们按照Page等人的建议设置了
α
=
0.85
α=0.85
α=0.85。对于无向图,我们对转换后的有向图执行PageRank,其中每条无向边都被转换为两条有向边。
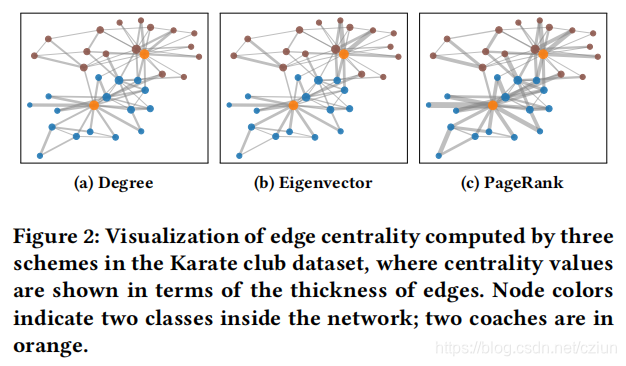
为了直观地了解这些提出的自适应结构增强方案,我们计算了著名的 Karate club 数据集的边缘中心性得分,其中包含两组分别由两个教练领导的两组学生。由不同方案计算出的边缘中心性值如图2所示。从图中可以看出,虽然三种方案表现出细微的差异,但所有的增强方案都倾向于强调连接两组内两个教练(橙色)的边缘,而较少关注组间外围节点之间的连接。这验证了所提出的基于节点中心性的自适应拓扑增强方案可以识别图的基本结构。
3.3.2 节点属性级增强
在节点属性层面上,我们通过在节点特征中使用零随机遮蔽部分维度来向节点属性添加噪声。
形式上,我们首先采样一个随机向量
m
~
∈
{
0
,
1
}
F
\widetilde{\pmb{m}}∈\{0,1\}^F
mmm
∈{0,1}F,它的每个维度都独立地从伯努利分布中提取,即
m
~
i
∼
B
e
r
n
(
1
−
p
i
f
)
,
∀
i
\widetilde{m}_i\sim Bern(1-p^f_i),\forall i
m
i∼Bern(1−pif),∀i。然后,生成的节点特征
X
~
\widetilde{\pmb{X}}
XXX
为:
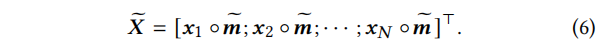
其中,
[
⋅
;
⋅
]
[ ·; ·]
[⋅;⋅]是连接操作,
◦
◦
◦是element-wise乘法。
与拓扑级增强类似,概率 p i f p^f_i pif应该反映节点特征的第 i i i维的重要性。我们假设经常出现在有影响的节点中的特征维度是重要的,并定义特征维度的权重如下。
对于稀疏one-hot节点的特征,即
x
u
i
∈
{
0
,
1
}
x_{ui}∈\{0,1\}
xui∈{0,1}对于任何节点
u
u
u和特征维度
i
i
i,我们计算维度
i
i
i的权重为:
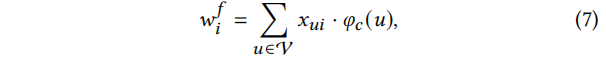
第一项
x
u
i
∈
{
0
,
1
}
x_{ui}∈\{0,1\}
xui∈{0,1}表示节点
u
u
u中维度
i
i
i的出现,第二项
φ
c
(
u
)
\varphi _c(u)
φc(u)衡量每次出现的节点的重要性。
举例来说,有一个引文网络,其中每个特征维度对应于一个关键字。那么,经常出现在一篇非常有影响力的论文中的关键字应该被认为是信息丰富和重要的。
对于节点
u
u
u的密集、连续的节点特征
x
u
\pmb{x}_u
xxxu,其中
x
u
i
x_{ui}
xui表示维度
i
i
i处的节点特征的值,我们不能直接计算每个one-hot编码值的出现情况。我们用绝对值
∣
x
u
i
∣
|x_{ui}|
∣xui∣来测量节点
u
u
u的
i
i
i维的特征值的大小:
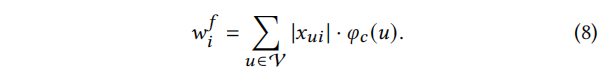
与拓扑增强类似,我们对权值进行归一化,以获得代表特征某一维度重要性的概率:
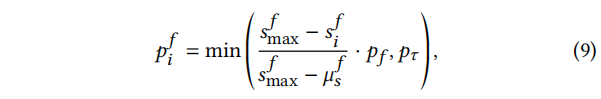
其中,
s
i
f
=
l
o
g
w
i
f
s^f_i=log w^f_i
sif=logwif。
最后,我们通过联合执行拓扑级和节点属性级的增强,生成两个损坏的图视图 G ~ 1 \widetilde{\mathcal{G}}_1 G 1、 G ~ 2 \widetilde{\mathcal{G}}_2 G 2。在GCA中,生成这两个视图的概率 p e p_e pe和 p f p_f pf是不同的,其中第一个和第二个视图的概率分别用 p e , 1 p_{e,1} pe,1、 p f , 1 p_{f,1} pf,1和 p e , 2 p_{e,2} pe,2、 p f , 2 p_{f,2} pf,2表示。
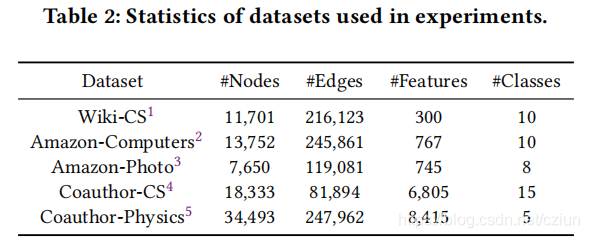
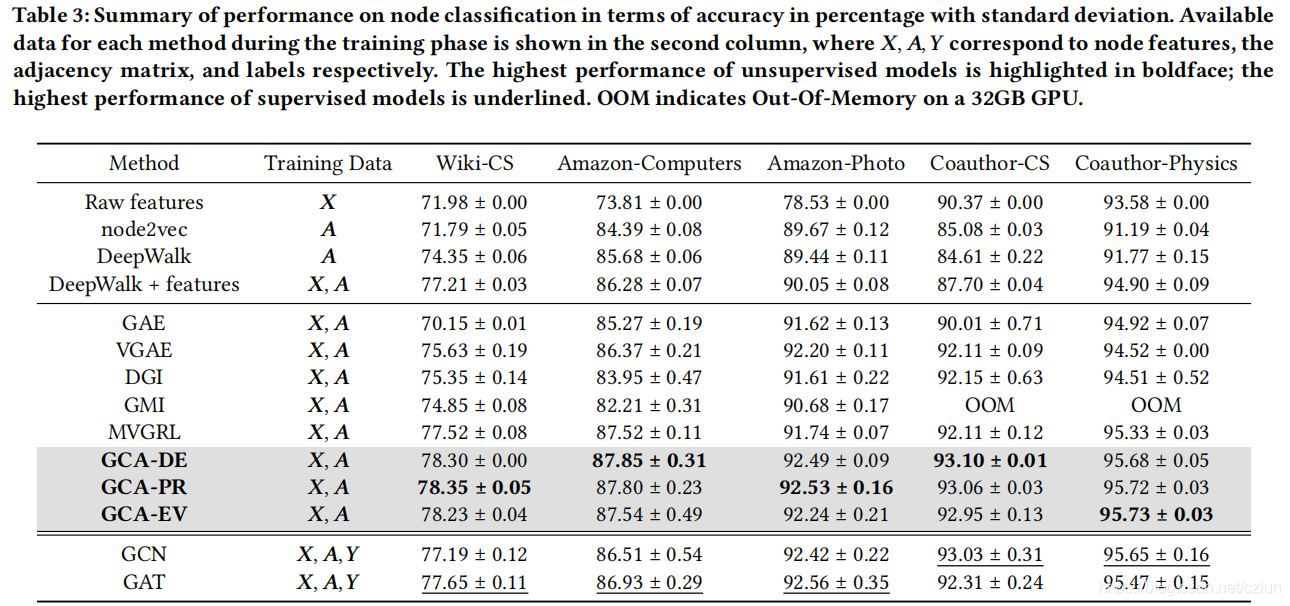
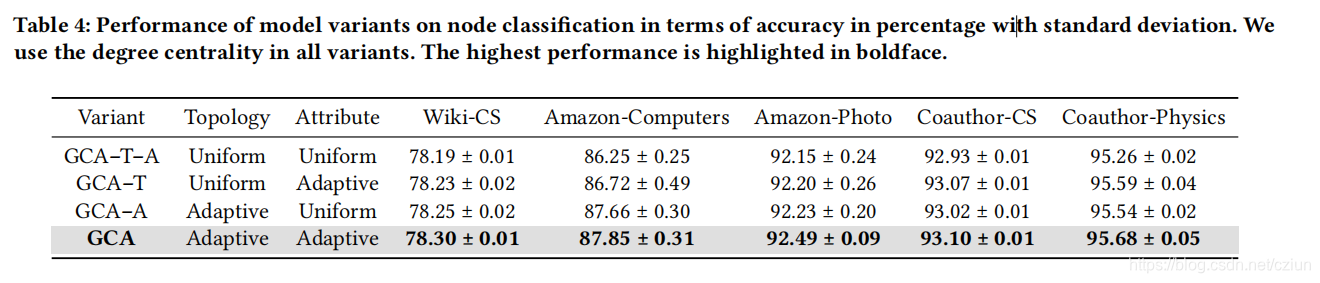
4 实验

















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









