







grep
grep 是linux 中最常用的“文本处理工具之一” 与sed awk 合称为linux中的三剑客!
grep 就像你在windows中打开txt文件,使用快捷键“Ctrl+F” 在文本中查找某个字符串一样,可以把grep 理解为字符查找工具
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。Grep是表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。功能主要就是:用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
grep 的全程为Global search Regular Expression and Print out the line 为全局搜索的意思
命令参数:
w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker,即只显示符合全字的列。
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-I:不区分大 小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。也即只打印没有匹配的,而匹配的反而不打印。
-e : 文件中符合条件的字符 ;找当前目录下所有文件中包含字符串”Linux”的文件,会将含有Linux字符串的所有文件匹配出来。
-o :只显示被模式匹配到的字符串。
-V : --version #显示版本信息。
-x : --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
-E : 将样式为延伸的普通表示法来使用。
规则表达式:
grep的正则表达式:
\ 忽略正则表达式中特殊字符的原有含义
^ 匹配正则表达式的开始行
$ 匹配正则表达式的结束行
< 从匹配正则表达式的行开始
> 到匹配正则表达式的行结束
[ ] 单个字符;如[A] 即A符合要求
[ - ] 范围 ;如[A-Z]即A,B,C一直到Z都符合要求
. 所有的单个字符
- 所有字符,长度可以为0
{m,n} :匹配其前面出现的字符至少m次,至多n次。
? :匹配其前面出现的内容0次或1次,等价于{0,1}。 - :匹配其前面出现的内容任意次,等价于{0,},所以 “.*” 表述任意字符任意次,即无论什么内容全部匹配。
\b或<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b或>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
\B :与\b作用相反。
实例
-i:在搜索的时候忽略大小写
[root@localhost ~]# cat /etc/passwd|grep -i "SSH"
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
-n: 显示结果所在行号
[root@localhost ~]# cat /etc/passwd|grep -ni "SSH"
17:sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
-c:统计匹配到的行数
[root@localhost ~]# cat /etc/passwd|grep "root"
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# cat /etc/passwd|grep -c "root"
2
-w:匹配单个单词,如果字符串中包含这个单词,则不匹配
[root@localhost ~]# cat /etc/passwd.bak|grep -w "root"
root:x:0:0:root:/root:/bin/bash
rootroo:x:0:0:root:/root:/bin/bash #不会显示rootroo的
-e:实现多个选项的匹配。逻辑或or的关系
==egrep
==grep -E
[root@localhost ~]# cat /etc/passwd.bak|egrep -w "root|sshd"
root:x:0:0:root:/root:/bin/bash
rootroo:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
-q: 静默模式,不输出任何信息 判断:echo $?
[root@localhost ~]# cat /etc/passwd.bak|grep -q "root"
-v:输出不带关键字的行(反向查询,反向匹配)
[root@localhost ~]# cat /etc/passwd.bak|grep -v "root"
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
(x)是冒号x冒号
查找指定进程
命令:
#ps -ef|grep svn
输出:
#ps -ef|grep svn
root 4943 1 0 Dec05 ? 00:00:00 svnserve -d -r /opt/svndata/grape/
root 16867 16838 0 19:53 pts/0 00:00:00 grep svn
说明:
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
查找指定进程个数
命令:
# ps -ef|grep mysqld -c
# ps -ef|grep -c mysqld
输出:

日志文件过大,不好查看,我们要从中查看自己想要的内容,或者得到同一类数据,比如说没有404日志信息的
命令:
# grep '.' access1.log|grep -Ev '404' > access2.log
# grep '.' access1.log|grep -Ev '(404|/photo/|/css/)' > access2.log
# grep '.' access1.log|grep -E '404' > access2.log
输出:
# grep “.”access1.log|grep -Ev “404” > access2.log
说明:上面3句命令前面两句是在当前目录下对access1.log文件进行查找,找到那些不包含404的行,把它们放到access2.log中,后面去掉’v’,即是把有404的行放入access2.log
显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
命令:
grep '[a-z]\{7\}' *.txt
输出:
# grep '[a-z]\{7\}' *.txt
test.txt:hnlinux
test.txt:peida.cnblogs.com
test.txt:linuxmint
显示包含ed或者at字符的内容行
命令:
# cat test.txt |grep -E "ed|at"
输出:
# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
# cat test.txt |grep -E "ed|at"
redhat
Redhat
输出ip地址
命令:
# ifconfig eth0 | grep -E "([0-9]{1,3}\.){3}[0-9]"
输出:

输出以sum结尾的行内容
命令:
# cat for1.sh | grep sum$
输出:

从文件中读取关键词进行搜索
命令:
# cat for1.sh | grep -f for2.sh
输出:(下个图片)
说明:输出for1.sh文件中含有从for2.sh文件中读取出的关键词的内容行


sed
流编辑器,主要用来过滤和替换文本内容
工作原理:
- sed是流编辑器,不允许用户与它进行交互操作.sed是以行为单位处理文本内容的.每一次读取一行到内存中,即称之为模式空间(pattern space)
- 默认不修改原文件,如果需要修改需加-i参数
- sed有模式空间及保持空间(hold sapce),默认打印模式空间中的内容到标准输出
- sed读取每行的时候会将内容保存至内存中
- 支持正则和扩展正则表达式,除-y选项
用法:
sed是一个“非交互式的”面向字符流的编辑器。能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到模式的内容输入到屏幕上。还可以对原文件改动,但是不会再屏幕上返回结果。
命令格式:
#sed [options] ‘sed command’ filename(s)
#sed [options] -f ‘sed scriptfile’ filename(s)
参数:文件指定待处理的文本文件列表。
sed [选项] ‘地址定界 动作’ file_name
选项:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。
但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。一般跟(p参数结合使用)
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
动作/命令:
a :新增行, a 的后面可以是字串,而这些字串会在新的一行出现(匹配行的下一行)
c :替换行,将匹配的行替换为指定字符“test”
d :删除行,因为是删除,所以 d 后面通常不接任何参数,直接删除地址表示的行;
i :插入行, i 的后面可以接字串,而这些字串会在新的一行出现(匹配行的上一行);
p :打印,即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :替换,可以直接进行替换的工作,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 一般是替换符合条件的字符串而不是整行
w :将模式空间匹配到的行,写入指定文件中
r :将PATH中指定的文件写入匹配到的行下方,多用于文件合并。
=:显示行号
! : 条件取反,一般用于模式之后,命令之前

示例:
地址定界常规方法:
1:空地址。即对全文就行处理 g是全局替换
[root@master ~]# sed ‘s/root/ROOT/g’ /etc/passwd
从第三次开始替换
[root@master ~]# echo “sksksksksksk” | sed ‘s/sk/SK/3g’
skskSKSKSKSK
所有已mysql开头的都被替换为mysql_wg007 (&符号表示匹配字符)
[root@master ~]# sed ‘s/^mysql/&_wg007/’ /tmp/passwd
2:单地址
[root@master ~]# sed -n ‘2p’ /etc/passwd
bin❌1:1:bin:/bin:/sbin/nologin
打印以#号开头的行
[root@master ~]# sed -n ‘/^#/p’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
3:地址范围
显示1-3行的内容
[root@master ~]# sed -n ‘1,3p’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
daemon❌2:2:daemon:/sbin:/sbin/nologin
显示:从第三行开始,往下再来3行
[root@master ~]# sed -n ‘3,+3p’ /tmp/passwd
daemon❌2:2:daemon:/sbin:/sbin/nologin
adm❌3:4:adm:/var/adm:/sbin/nologin
lp❌4:7:lp:/var/spool/lpd:/sbin/nologin
sync❌5:0:sync:/sbin:/bin/sync
4:步进地址表示法
打印奇数行
[root@master ~]# sed -n ‘1~2p’ /tmp/passwd
打印偶数行
[root@master ~]# sed -n ‘2~2p’ /tmp/passwd
d:删除模式空间的内容
删除第一行的内容
[root@master ~]# sed ‘1d’ /tmp/passwd
删除1-3行的内容
[root@master ~]# sed ‘1,3d’ /tmp/passwd
删除空行
sed ‘/^$/d’ /tmp/passwd
a:追加**
在以#号开头的行号后面新增一行字符“123”**
[root@master ~]# sed ‘/^#/a “123”’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
“123”
在第一行后面新增字符“huazai007”
[root@master ~]# sed ‘1a"huazai007"’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
“huazai007”
i:插入
在第三行的前面插入字符“huazai007”
[root@master ~]# sed ‘3i"huazai007"’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
“huazai007”
daemon❌2:2:daemon:/sbin:/sbin/nologin
在以lp开头的行前插入一行
[root@master ~]# sed ‘/^lp/i"huazai007"’ /tmp/passwd
#root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
daemon❌2:2:daemon:/sbin:/sbin/nologin
adm❌3:4:adm:/var/adm:/sbin/nologin
“huazai007”
lp❌4:7:lp:/var/spool/lpd:/sbin/nologin
在以nologin结尾的行前插入一行
smmsp❌51:51::/var/spool/mqueue:/sbin/nologin
“huazai007”
mysql❌27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
[root@master ~]# sed ‘/nologin$/i"huazai007"’ /tmp/passwd
c:替换
当前行只要包含“”root“” 这个字符串,整行会被替换为“huazai007”
[root@master ~]# sed ‘/root/c"huazai007"’ /tmp/passwd
“huazai007”
将以#号开头的替换为“”huazai007“”
[root@master ~]# sed ‘/^#/c"huazai007"’ /tmp/passwd
“huazai007”
w : 将模式空间匹配到的行,写入指定文件中
将以#号开头的行写入到result.txt文件
[root@master ~]# sed ‘/^#/w result.txt’ /tmp/passwd
[root@master ~]# cat result.txt
#root❌0:0:root:/root:/bin/bash
将1-3行写入到result文件
[root@master ~]# sed ‘1,3w result.txt’ /tmp/passwd
r /PATH : 将PATH中指定的文件写入匹配到的行下方,多用于文件合并。
将result.txt 的内容写入到 以mysql开头并且以nologin结尾的行后面
mysql❌27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
#root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
daemon❌2:2:daemon:/sbin:/sbin/nologin
[root@master ~]# sed ‘/^mysql.*nologin$/r result.txt’ /tmp/passwd
=:显示行号
显示最后一行的行号
24
mysql❌27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
[root@master ~]# sed ‘KaTeX parse error: Expected 'EOF', got '#' at position 59: …[root@master ~]#̲ sed '/^ftp.*n…/=’ /tmp/passwd
12
ftp❌14:50:FTP User:/var/ftp:/sbin/nologin
nobody❌99:99:Nobody:/:/sbin/nologin
! : 条件取反,一般用于模式之后,命令之前
除了#号开头的都打印出来
sed -n ‘/^#/!p’ /tmp/passwd
sed高级用法:模式空间与保持空间
模式空间:sed处理文本内容行的一个临时缓冲区,模式空间中的内容会主动打印到标准输出,并自动清空模式空间
保持空间:sed处理文本内容行的另一个临时缓冲区,不同的是保持空间内容不会主动清空,也不会主动打印到标准输出,而是需要sed命令来进行处理
模式空间与保持空间的关系
模式空间:相当于流水线,文本行在模式空间中进行处理;
保持空间:相当于仓库,在模式空间对数据进行处理时,可以把数据临时存储到保持空间;作为模式空间的一个辅助临时缓冲区,但又是相互独立,可以进行交互,命令可以寻址模式空间但是不能寻址保持空间。可以使用高级命令h,H,g,G与模式空间进行交互。
hold:(H|h)(追加|覆盖)到保持空间
get:(G|g)(追加|覆盖)到模式空间
exchange:(x)空间互换
h : 把模式空间中的内容覆盖至保持空间中
H : 把模式空间中的内容追加至保持空间中
g : 把保持空间中的内容覆盖至模式空间中
G : 把保持空间中的内容追加至模式空间中
x : 把模式空间中的内容到保持空间中的内容互换,初始保持空间中为空
n : 读取下一行覆盖模式空间中的行
seq 11 | sed ‘n;d’ : 显示结果为1、3、5、7、9、11 ,默认动作先输出模式空间中的行,再覆盖读取下一行,再执行d命令
seq 10 | sed ‘n;d’ : 显示结果为1、3、5、7、9
N : 读取下一行并追加到模式空间中的行后面,使用\n分隔
seq 11 | sed ‘N;d’ : 显示结果为11,默认动作先读取两行,然后执行d操作
seq 10 | sed ‘N;d’ :显示结果为空
D : 删除模式空间中的多行
seq 11 | sed ‘N;D’ : 显示结果为11
{} : 多命令同时执行时,需要使用{}括起来
sed -n ‘/^UUID/{N;p}’ fstab1 : 读取UUID开始的行,再读取下一行并打印模式空间的内容。
理解n与N
n : 读取下一行覆盖模式空间中的行
N : 读取下一行并追加到模式空间中的行后面,使用\n分隔

说明:pattern space先读入1,然后执行到n,把下一行2读入pattern space中并覆盖原本的1。然后pattern space中的内容(2)被删除(d操作),所以打印出1\n3

说明:pattern space先读入1,然后执行到N,把下一行添加到当前的pattern space中,pattern space内容为1\n2,然后执行d操作被删除。接下去读入3,执行N,pattern space 内容变为3\n4,然后再被删除,就剩下个5

以上两都不会输出输入,-n参数把模式空间中的内容关闭显示了
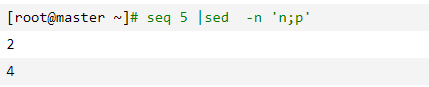
说明:-n参数不显示模式空间的内容,说明:模式空间中有1,然后n使用2覆盖1,再p打印,当执行到第5行时,发现没有下一行了,就不执行n了
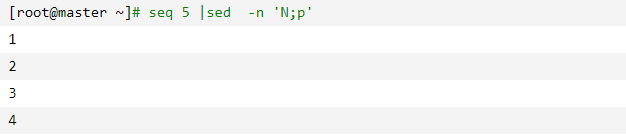
说明:n首先读取1\n2 -->打印模式空间 -->读取3\n4—>打印模式空间—>读取5行发现没有第6行—>失败
理解x:
把模式空间中的内容到保持空间中的内容互换,初始保持空间中为空

说明:当匹配到3的时候,执行交换,现在模式空间为空行,保持空间中为3,执行p命令显示模式空间中的空行,x再交换两这空间的内容,此是模式空间为3,默认模式空间的就会输出至标准屏幕,故3之前多了一个空行
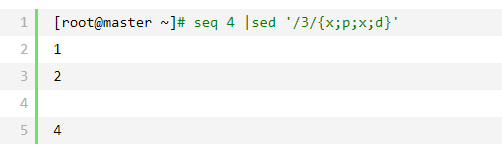
说明:当第二个x交换回来,直接交给d执行,故3就没有了,只多了一条空行
理解h和H

说明:把模式空间中的内容覆盖到保持空间,再交换,再打印至标准输出

说明:先把模式空间的与保持空间交换,现在模式空间为空行,保持空间为1,然后再把模式空间覆盖保持空间,再输出至标准输出,故都为空行

说明: 把模式空间中的内容(1)追加到保持空间(0+1),再交换,此时模式空间空间为(0+1),保持空间为(1)再打印至标准输出

说明: 将模式空间的(1)和保持空间的(0)互换,再将模式空间的(0)追加到保持空间的(1)下 。此时保持空间为(10),模式空间为(0)。再打印标准输出0,以此类推
理解g和G

说明:当匹配到3的时候,把保持空间的空行覆盖到模式空间,故就输出了空行
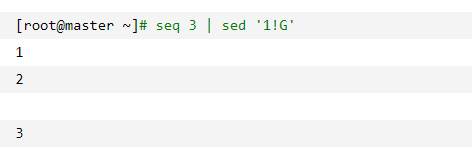
说明: 不是第1行就执行G操作,G是追加保持空间到模式空间,即为2+空行

awk
awk 是一个优良的文本处理工具。(其名称得自于它的创始人阿尔佛雷德·艾侯、彼得·温伯格和布莱恩·柯林汉姓氏的首个字母)
语法:awk ‘pattern {action}’ file_name
其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令
awk内置变量

root@localhost ~]# awk ‘{print $0}’ /etc/passwd
root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
daemon❌2:2:daemon:/sbin:/sbin/nologin
print 是打印命令 $0 是代表当前行
awk 会根据空格和制表符,将每一行分成若干字段,一次用$1,$2,$3代表第一个字段,第二个字段,第三个字段
-F 指定分隔符为冒号

awk 常用变量
NF:表示最后一个字段

$(NF-1):表示倒数第二个字段

NR:表示当前处理的是第几行
输出第二行

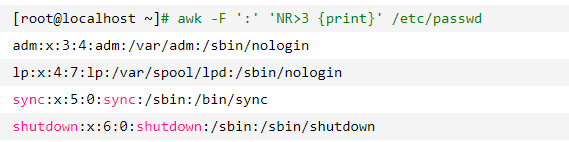
输出第三行以后的行
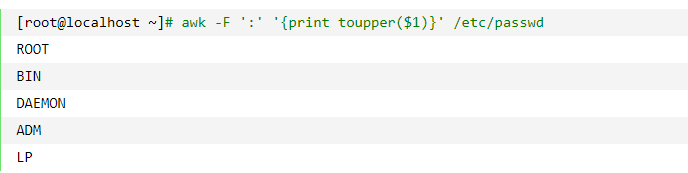
awk 内置函数
toupper()用于将字符转为大写【t^ber】
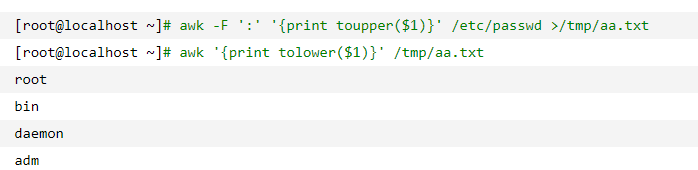
tolower()用于将字符串转为小写
awk 允许指定输出条件,只输出符合条件的行
打印包含root的行

输出第一个字段等于指定值的行

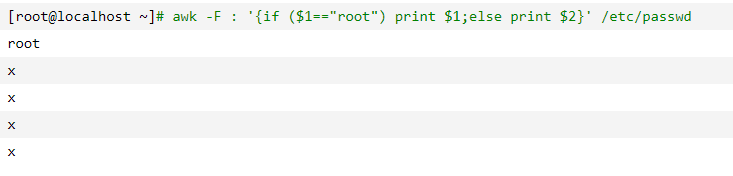
awk if else语句
假如$1==root 打印第一个字段,否则打印第二个字段
awk 高级用法BEGIN END
任何在BEGIN之后列出的操作(在{}内)将在Unix awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。
因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果
数字求和


AWK 数组
awk可以使用关联数组这种数据结构,索引可以是数字或字符串。
AWK关联数 组也不需要提前声明其大小,因为它在运行时可以自动的增大或减小。
定义数组,并且打印数组元素

统计访问网站的ip地址的个数
















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









