






代码地址
https://github.com/xiaoxu1025/r-fcn
对于看了论文一知半解的朋友可以看看我的RCNN系列的实现。
CSDN链接地址:
https://blog.csdn.net/xiaoxu1025/article/details/104134569 RCNN系列之-RCNN keras实现
https://blog.csdn.net/xiaoxu1025/article/details/104127684 RCNN系列之-Faster-RCNN keras实现
https://blog.csdn.net/xiaoxu1025/article/details/104101234 RCNN系列之-Fast-RCNN keras实现
github链接地址:
https://github.com/xiaoxu1025/rcnn-keras
https://github.com/xiaoxu1025/fast-rcnn-keras
https://github.com/xiaoxu1025/faster-rcnn-keras
实现很简单也很好理解,只是作为一个学习记录。有兴趣的朋友可用下载下来看看,比看网上各种文章好懂多了。rcnn系列keras实现基本上和源码实现方式差不多,也不会误导同学们。如果有帮助到你们,希望给我点个👍哦!!!
接下来 分析下 R-FCN 关于R-FCN的文章网上有很多,我这里只简单讲解下
R-FCN其实是为了给faster-rcnn加速的,因为faster-rcnn 在roi层后的全连接对所有proposal不共享,比如一张图片最后生成300个proposal 每个proposal都需要走一遍后面的全连接结构。这其实是很耗时的。所有R-FCN作者提出把roi后的操作提前。但是简单提前不行,所有作者弄出来了个 Position-sensitive score map
其中r-fcn难点在于roipooling 因为它和faster-rcnn的roipooling操作有点不同。
下面我就具体分析一下(这是我用keras实现的一个roipooling层):
import tensorflow as tf
from tensorflow.keras.layers import Layer
"""
该层是用来对r-fcn进行roipooling
和faster-rcnn roipooling实现不同
"""
class RRoiPooling(Layer):
def __init__(self, im_dims, last_dim, k=3, **kwargs):
# k 是超参数 对 position-sensitive score maps or position-sensitive regression
# 进行roi后feature maps大小
super(RRoiPooling, self).__init__(**kwargs)
self._im_dims = im_dims
self._k = k
# 因为cls 和 reg 都是用的这一层实现 所以这里将最后一维度穿进来
# cls: C + 1 reg : 4
self._last_dim = last_dim
def call(self, inputs, **kwargs):
"""
:param inputs: inputs shape (None, H, W, K * K * (C + 1)) or (None, H, W, K * K * 4)
第一个是 position-sensitive score maps 第二个是 position-sensitive regression maps
:param rois: (N, 5) (batch_id, x1, y1, x2, y2)
:param kwargs:
:return:
"""
feature_maps, rois = inputs[0], inputs[1]
# reshape 成rank: 2
rois = tf.reshape(rois, (-1, 5))
# 进行rois标准化
k = self._k
feature_split = tf.split(feature_maps, num_or_size_splits=k * k, axis=-1)
# y1, x1, y2, x2
boxes, batch_ids = self._normalize_boxes(rois)
# 将boxes分成k * k个bin 每个bin大小为bin_w * bin_h
bin_w = (boxes[..., 3] - boxes[..., 1]) / k
bin_h = boxes[..., 2] - boxes[..., 0] / k
sensitive_boxes = []
for ih in range(k):
for iw in range(k):
box_coordinates = [boxes[..., 0] + ih * bin_h,
boxes[..., 1] + iw * bin_w,
boxes[..., 0] + (ih + 1) * bin_h,
boxes[..., 1] + (iw + 1) * bin_h]
sensitive_boxes.append(tf.stack(box_coordinates, axis=-1))
features = []
for (feature, box) in zip(feature_split, sensitive_boxes):
# crop对于区域后resize 成 (2k, 2k) 这个大小可以调整 不要太离谱就行
pooled_features = tf.image.crop_and_resize(feature, box, tf.cast(batch_ids, dtype=tf.int32), [k * 2, k * 2])
features.append(pooled_features)
# [(N, 6, 6, self._last_dim), (N, 6, 6, self._last_dim), (N, 6, 6, self._last_dim), ...] 总共9个
# N 为 len(rois) == len(boxes)
# 然后对list中的tesor各个位置上的值相加并求平均
sensitive_features = tf.add_n(features) / len(features)
# (N, self._last_dim)
output = tf.reduce_mean(sensitive_features, axis=[1, 2])
output = tf.expand_dims(output, axis=0)
return output
def _normalize_boxes(self, rois):
"""
对rois 进行normalize 使其满足tf.image.crop_and_resize方法参数格式
:param rois: (None, 5) batch_id, x1, y1, x2, y2
:return:
"""
im_dims = self._im_dims
normalization = tf.cast(tf.stack([im_dims[1], im_dims[0], im_dims[1], im_dims[0]], axis=0),
dtype=tf.float32)
batch_ids = rois[..., 0]
boxes = rois[..., 1:]
boxes = tf.div(boxes, normalization)
# tf.stop_gradient
# y1, x1, y2, x2
boxes = tf.stack([boxes[..., 1], boxes[..., 0], boxes[..., 3], boxes[..., 2]], axis=-1)
return boxes, batch_ids
计算公式如下:
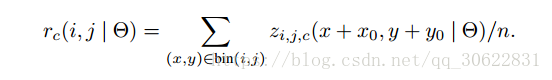
![]()
讲一下我个人对这个公式的理解
对于 sensitive position score map 的维度是[H, W, K * K * (C + 1)]
通道维度可以分成 K * K 组 每组(C + 1)维的向量,同时我们还会对我们要进行roipooling的区域(h, w)进行划分,将其分成 k * k 个bin
每个bin的大小 h / k, w/k 每个bin对应通道中一组C + 1维度向量 顺序则是 从上到下 从左到又 就像下面表格中的索引顺序。具体实现细节可以参考下我上面的代码。
| 0 | 1 | 2 |
| 3 | 4 | 5 |
| 6 | 7 | 8 |
对于regresion map 就和score map 是一样的操作 这里就不重复了
其他的功能实现,请参考代码。我就不全部讲解了
如果有帮助到大家,请给我点个赞~
与君共勉!!!

















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









