










在机器学习领域,概率分布对于数据的认识有着非常重要的作用。不管是有效数据还是噪声数据,如果知道了数据的分布,那么在数据建模过程中会得到很大的启示。
首先,如下图所示8个特征数据概率分布情况(已经做归一化),这些特征是正态分布、伯努利分布,还是泊松分布、幂律分布?
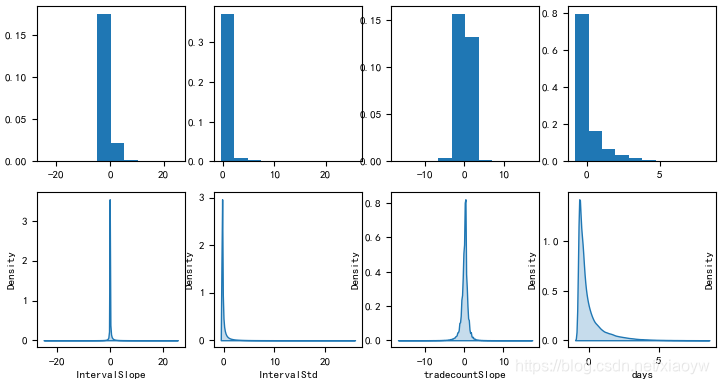
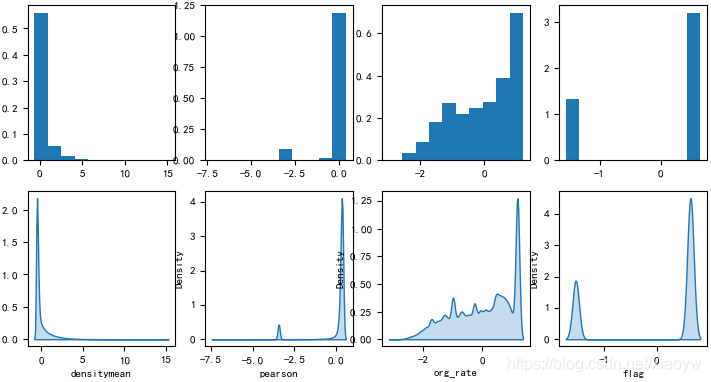
在高斯法则生效的领域,平均值可以代表整体。但是在幂律法则统治的领域,平均值毫无意义。高斯法则和幂律法则的典型代表是分别身高和财富,把姚明放到100个人中,并不会显著改变平均身高,但把比尔·盖茨放到100个人中,就会极大改变平均财富。
在高斯法则生效的领域,所有人跟平均值的差距不会很大;但是在幂律法则分布的领域,跟平均值的差距就会大到惊人。
正态法则和幂律法则,细思极恐。带着问题,我们开始概率分布之旅。
1. 概率分布概述
概率分布,是指用于表述随机变量取值的概率规律。将随机变量作为横轴,概率作为纵轴,把随机变量与对应变量画上去,构成一个图形,这个图像就是概率分布的直观表示。通常也用概率分布函数表示
F
(
x
)
F ( x )
F(x)来描述一个概率分布,概率分布函数被定义为:
F
(
x
)
=
P
{
X
<
x
}
F ( x ) =P\{X<x\}
F(x)=P{X<x}
总之概率分布也可以理解为一个函数,它刻画了随机变量与概率的映射关系,给定一个概率分布,就可以求任何随机变量对应的概率了。当一个随机变量与它的概率满足某一个概率分布的映射关系时,则称这个随机变量服从该概率分布。
如下图为常用概率分别关系图。
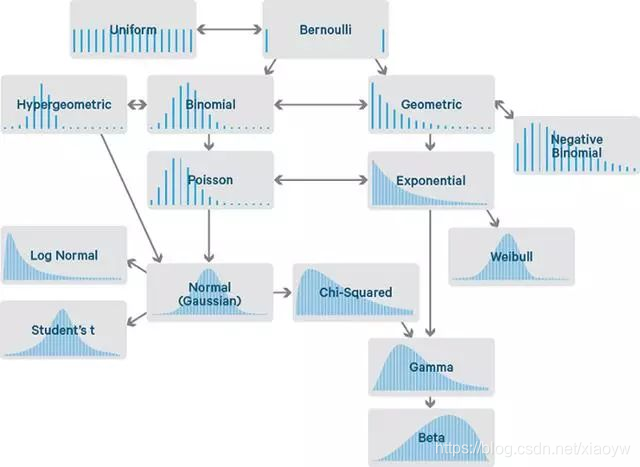
2. 常用概率分布
2.1. 均匀分布
均匀分布在 [a,b] 上具有相同的概率值,是简单概率分布。
均匀分布可以很容易地从伯努利分布中得出。在这种情况下,结果的数量可能不受限制,并且所有事件的发生概率均相同。例如掷骰子,存在多个可能的事件,每个事件都有相同的发生概率。
2.2. 伯努利分布
伯努利分布(Bernoulli Distribution)是单个二值随机变量的分布,是一种离散分布,又称为 “0-1 分布” 或 “两点分布”。例如抛硬币的正面或反面,物品有缺陷或没缺陷,病人康复或未康复,此类满足「只有两种可能,试验结果相互独立且对立」的随机变量通常称为伯努利随机变量。
假设二值其中之一的概率等于 p p p,而对于互斥对立面面则是 ( 1 − p ) (1-p) (1−p)(包含所有可能结果的互斥事件的概率总和为1)。
对于伯努利分布来说,其离散型随机变量期望为:
E
(
x
)
=
∑
x
×
p
(
x
)
=
1
×
p
+
0
×
(
1
−
p
)
=
p
E(x) = ∑x\times p(x) = 1\times p+0\times (1−p) = p
E(x)=∑x×p(x)=1×p+0×(1−p)=p
E
(
x
2
)
=
∑
x
×
p
(
x
2
)
=
1
2
×
p
+
0
2
×
(
1
−
p
)
=
p
E(x^2) = ∑x\times p(x^2) = 1^2\times p+0^2\times (1−p) = p
E(x2)=∑x×p(x2)=12×p+02×(1−p)=p
方差为:
V
a
r
(
x
)
=
E
(
x
2
)
−
(
E
(
x
)
)
2
=
p
−
p
2
=
p
(
1
−
p
)
Var(x) = E(x^2)−(E(x))^2 = p−p^2 = p(1−p)
Var(x)=E(x2)−(E(x))2=p−p2=p(1−p)
2.3. 二项分布
二项分布(binomial distrubution)就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
P { X = k } = ( n k ) p k ( 1 − p ) ( n − k ) P\{X=k\}=\binom{n}{k}p^k(1-p)^{(n-k)} P{X=k}=(kn)pk(1−p)(n−k)
式中 k = 0 , 1 , 2 , . . . , n k=0,1,2,...,n k=0,1,2,...,n, ( n k ) = n ! k ! ( n − k ) ! \binom{n}{k}=\frac{n!}{k!(n-k)!} (kn)=k!(n−k)!n!是二项式系数,又记为 C n k C_n^k Cnk。
二项式分布的主要特征是:
给定多个试验,每个试验彼此独立(一项试验的结果不会影响另一项试验)。
每个试验只能得出两个可能的结果(例如,获胜或失败),其概率分别为p和(1- p)。
如果获得成功概率(p)和试验次数(n),则可以使用以下公式计算这n次试验中的成功概率(x)。
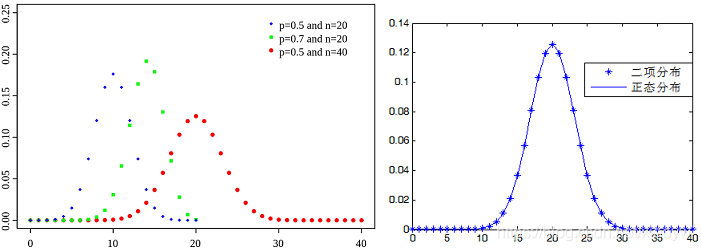
如果二项分布满足p<q,np≥5,(或p>q,np≥5)时,二项分布接近正态分布。
E
(
X
)
=
n
p
E(X)=np
E(X)=np
V
a
r
(
X
)
=
n
p
(
1
−
p
)
Var(X)=np(1-p)
Var(X)=np(1−p)
2.4. 多项分布
多项式分布(Multinoulli distribution)二项分布的推广。二项分布(也叫伯努利分布)的典型例子是扔硬币,硬币正面朝上概率为p, 重复扔n次硬币,k次为正面的概率即为一个二项分布概率。而多项分布就像扔骰子,有6个面对应6个不同的点数。
某随机实验如果有k个可能结局 A 1 、 A 2 、 … 、 A k A_1、A_2、…、A_k A1、A2、…、Ak,分别将他们的出现次数记为随机变量 X 1 、 X 2 、 … 、 X k X_1、X_2、…、X_k X1、X2、…、Xk,它们的概率分布分别是 p 1 , p 2 , … , p k p_1,p_2,…,p_k p1,p2,…,pk,那么在n次采样的总结果中, A 1 A_1 A1出现 n 1 n_1 n1次、 A 2 A_2 A2出现 n 2 n_2 n2次、…、 A k A_k Ak出现 n k n_k nk次的这种事件的出现概率P有下面公式:
P ( X 1 = n 1 , X 2 = n 2 , ⋯ , X k = n k ) = { n ! n 1 ! n 2 ! ⋯ n k ! p 1 n 1 p 2 n 2 ⋯ p k n k , ∑ i = 1 k n i = n 0 , o r t h e r w i s e P(X_1=n_1,X_2=n_2,⋯,X_k=n_k)=\left\{\begin{matrix} \frac{n!}{n1!n2!⋯nk!}p^{n1}_1p^{n2}_2⋯p^{nk}_k & , \sum_{i=1}^{k}n_i = n\\ 0 & , ortherwise \end{matrix}\right. P(X1=n1,X2=n2,⋯,Xk=nk)={n1!n2!⋯nk!n!p1n1p2n2⋯pknk0,∑i=1kni=n,ortherwise
多项分布对其每一个结果都有均值和方差,分别为:
E
(
X
i
)
=
n
p
i
E(X_i)=np_i
E(Xi)=npi
V
a
r
(
X
i
)
=
n
p
i
(
1
−
p
i
)
Var(X_i)=np_i(1-p_i)
Var(Xi)=npi(1−pi)
2.5. 泊松分布
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数、激光的光子数分布等等。【维基百科】
P ( X = k ) = λ k k ! e − λ , k = 0 , 1 , . . . P(X=k)= \frac{λ^k}{k!}e^{-λ} ,k=0,1,... P(X=k)=k!λke−λ,k=0,1,...
泊松分布的参数
λ
λ
λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。
泊松分布的期望和方差均为
λ
λ
λ
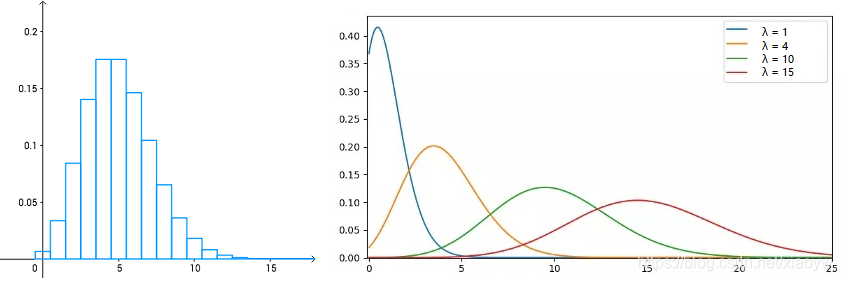
一般来说,我们会换一个符号,让
μ
=
λ
\mu=\lambda
μ=λ 。
2.6. 正态分布
若随机变量 X X X服从一个数学期望为 μ μ μ、方差为 σ 2 \sigma ^2 σ2的正态分布,记为 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)。其概率密度函数为正态分布的期望值 μ μ μ决定了其位置,其标准差 σ σ σ决定了分布的幅度。当 μ = 0 , σ = 1 μ = 0,σ = 1 μ=0,σ=1时的正态分布是标准正态分布。
标准正态分布又称为
u
u
u分布,是以0为均数、以1为标准差的正态分布,记为
N
(
0
,
1
)
N(0,1)
N(0,1)。
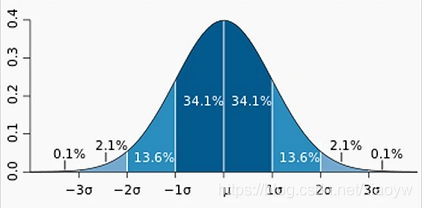
一维正态分布
若随机变量
X
X
X服从一个位置参数为
μ
μ
μ 、尺度参数为
σ
σ
σ的概率分布,且其概率密度函数为:
f
(
x
)
=
1
2
π
σ
e
(
−
(
x
−
μ
)
2
2
σ
2
)
f(x)=\frac {1}{\sqrt{2π}σ}e^{(-\frac{(x-μ)^2}{2σ^2})}
f(x)=2πσ1e(−2σ2(x−μ)2)
标准正态分布
当
μ
=
0
,
σ
=
1
μ=0,σ=1
μ=0,σ=1时,正态分布就成为标准正态分布:
f
(
x
)
=
1
2
π
e
(
−
x
2
2
)
f(x)=\frac {1}{\sqrt{2π}}e^{(-\frac{x^2}{2})}
f(x)=2π1e(−2x2)
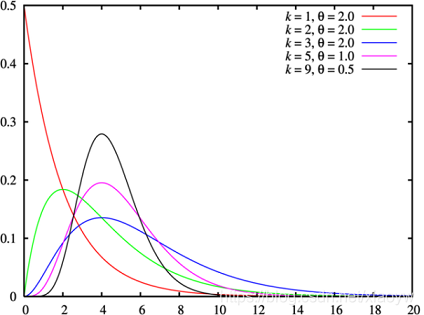
2.7. 伽马分布
伽玛分布(Gamma Distribution),Gamma分布中的参数α,称为形状参数(shape parameter),β称为尺度参数(scale parameter)。
“指数分布”和“
χ
2
χ^2
χ2分布”都是伽马分布的特例。
令 X ∼ Γ ( α , β ) X \sim \Gamma(\alpha, \beta) X∼Γ(α,β);且令 λ = 1 β \lambda = \frac{1}{\beta} λ=β1: (即 X ∼ Γ ( α , 1 λ ) ) X \sim \Gamma(\alpha, \frac{1}{\lambda})) X∼Γ(α,λ1))。
f
(
X
)
=
X
(
α
−
1
)
λ
α
e
(
−
λ
X
)
Γ
(
α
)
,
X
>
0
f(X) = \frac{X^{(\alpha -1)} \lambda^{\alpha} e^{(-\lambda X)}}{\Gamma(\alpha)},X > 0
f(X)=Γ(α)X(α−1)λαe(−λX),X>0
2.8. 几何分布
几何分布(Geometric distribution)在伯努利试验中,记每次试验中事件 A A A发生的概率为 p p p,试验进行到事件A出现时停止,此时所进行的试验次数为 X X X,其分布列为:
P
(
X
=
k
)
=
(
1
−
p
)
(
k
−
1
)
p
,
k
=
1
,
2
,
.
.
.
P(X=k)=(1-p)^{(k-1)}p,k=1,2,...
P(X=k)=(1−p)(k−1)p,k=1,2,...
此分布列是几何数列的一般项,因此称
X
X
X服从几何分布,记为
X
~
G
E
(
p
)
X ~ GE(p)
X~GE(p) 。
实际中有不少随机变量服从几何分布,譬如,某产品的不合格率为0.05,则首次查到不合格品的检查次数
X
~
G
E
(
0.05
)
X ~ GE(0.05)
X~GE(0.05) 。
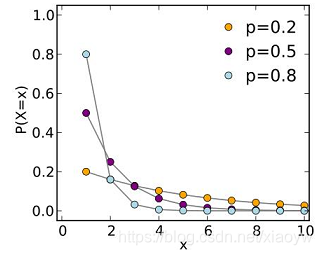
X ∼ G E ( p ) , q = 1 − p , P ( X = r ) = p q ( r − 1 ) X\sim GE(p),q=1-p,P(X = r) = pq^{(r-1)} X∼GE(p),q=1−p,P(X=r)=pq(r−1),当 r → ∞ r→∞ r→∞时:
期望和方差:
E
(
X
)
=
1
p
E(X) = \frac{1}{p}
E(X)=p1
V
a
r
(
X
)
=
q
p
2
Var(X) = \frac{q}{p^2}
Var(X)=p2q
2.9. 指数分布
在概率理论和统计学中,指数分布(Exponential distribution也称为负指数分布)是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 这是伽马分布的一个特殊情况。 它是几何分布的连续模拟,它具有无记忆的关键性质。 除了用于分析泊松过程外,还可以在其他各种环境中找到。
f ( x ) = { λ e − ( λ x ) , x > 0 0 , x ≤ 0 f(x)=\left\{\begin{matrix} λe^{-(λx)} & , x>0\\ 0 & , x ≤ 0 \end{matrix}\right. f(x)={λe−(λx)0,x>0,x≤0
在概率论和统计学中,指数分布是一种连续概率分布。指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进机场的时间间隔、中文维基百科新条目出现的时间间隔等等。
许多电子产品的寿命分布一般服从指数分布。有的系统的寿命分布也可用指数分布来近似。它在可靠性研究中是最常用的一种分布形式。指数分布是伽玛分布和威布尔分布的特殊情况,产品的失效是偶然失效时,其寿命服从指数分布。
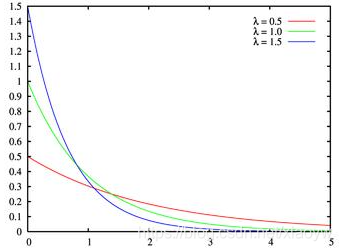
期望与方差:
E
(
X
)
=
1
λ
E(X)=\frac{1}{λ}
E(X)=λ1
V
a
r
(
X
)
=
1
λ
2
Var(X) = \frac{1}{λ^2}
Var(X)=λ21
2.10. 卡方分布
卡方分布(chi-square distribution),也称为 X 2 X^2 X2分布,若 n n n个相互独立的随机变量 ξ 1 , ξ 2 , . . . , ξ n ξ_1,ξ_2,...,ξ_n ξ1,ξ2,...,ξn,均服从标准正态分布(也称独立同分布于标准正态分布),则这 n n n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为卡方分布。
χ 2 ( n ) χ^2 ( n ) χ2(n) 分 布 , 就 是 Γ Γ Γ 分 布 的 一 种 特 殊 形 式:
其中 α = n 2 , β = 1 2 α = \frac{n}{ 2} , β = \frac{1}{ 2} α=2n,β=21
f ( x ) = { 1 2 n 2 Γ ( n 2 ) x n 2 − 1 e − 1 2 x , x > 0 0 , x ≤ 0 f ( x ) = \left\{\begin{matrix} \frac{1}{2^{\frac{n}{2}} Γ ( \frac{n}{ 2} )} x^{\frac{n}{2}-1}e^{-\frac{1}{2}x}& , x>0\\ 0 & , x ≤ 0 \end{matrix}\right. f(x)={22nΓ(2n)1x2n−1e−21x0,x>0,x≤0
定义 如果随机变脸
X
i
X_i
Xi 之 间 相 互 独 立 且 服 从
N
(
0
,
1
)
N ( 0 , 1 )
N(0,1) , 分 布 , 则 称 随 机 变 量
χ
2
=
X
1
2
+
X
2
2
+
.
.
.
+
X
n
2
χ^2 = X_1^ 2 + X_ 2^2 + ... + X_n^2
χ2=X12+X22+...+Xn2 服从自由度为
n
n
n 的
χ
2
χ^2
χ2 分 布 记 为
χ
2
∼
X
2
(
n
)
χ^2\sim X^2(n)
χ2∼X2(n)
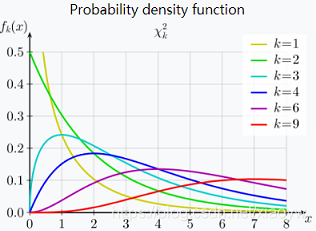
2.11. beta分布
贝塔分布(Beta Distribution) 是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,在机器学习和数理统计学中有重要应用。在概率论中,贝塔分布,也称
B
Β
B分布,是指一组定义在(0,1) 区间的连续概率分布。
f
(
x
:
α
,
β
)
=
1
B
(
α
,
β
)
x
(
α
−
1
)
(
1
−
x
)
(
β
−
1
)
f(x:α ,β)=\frac{1}{B(α ,β)}x^{(α-1)}(1-x)^{(β-1)}
f(x:α,β)=B(α,β)1x(α−1)(1−x)(β−1)
其中
Γ
(
z
)
Γ(z)
Γ(z) 是
Γ
Γ
Γ函数。随机变量
X
X
X服从参数为
(
α
,
β
)
(α ,β)
(α,β) 的
B
Β
B分布通常写作
X
∼
B
e
B
(
α
,
β
)
X \sim BeB(α ,β)
X∼BeB(α,β)
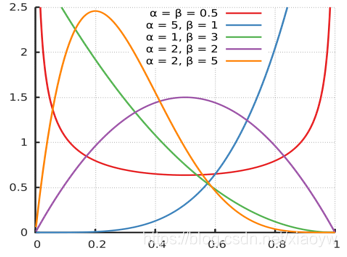
2.12. 幂律分布
幂律分布是指某个具有分布性质的变量,且其分布密度函数是幂函数(由于分布密度函数必然满足“归一律”,所以这里的幂函数,一般规定小于负1)的分布。
幂律分布表现为一条斜率为幂指数的负数的直线,这一线性关系是判断给定的实例中随机变量是否满足幂律的依据。
假设变量x服从参数为 的幂律分布,则其概率密度函数可以表示为:
f
(
x
)
=
c
x
−
α
−
1
,
x
→
∞
f(x)=cx^{-α-1}, x→∞
f(x)=cx−α−1,x→∞
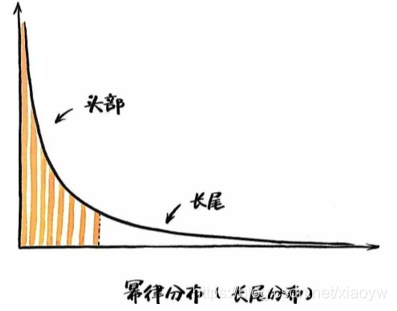
在双对数坐标下,幂律分布表现为一条斜率为幂指数的负数的直线,这一线性关系是判断给定的实例中随机变量是否满足幂律的依据。
Zipf定律与Pareto定律(帕累托定律)
对“长尾”分布研究做出重要贡献的是Zipf和Pareto ,虽然他们并不是这种分布的最早发现者。Zipf定律与Pareto定律都是简单的幂函数,我们称之为幂律分布。

3. 总结
回顾本文的开始,幂律分布的长尾现象很普遍,大数据中小概率数据普遍存在,如何解决呢?
我的方法是把数据 x 3 \sqrt[3]{x} 3x,对模型的精度结果影响只有不到千分之一,也就是说数据变换缩短尾巴效果有限。另外的方法,是从整体模型上考虑细分,二八原则中,把20%的分离出来,自顶向下逐步精确。
参考:
【1】视学算法,数据分析必须掌握的概率分布!建议收藏! CSDN博客 ,2019.11
【2】数据派THU,深度学习必懂的 13 种概率分布(附链接) CSDN博客,2020.02
【3】马同学图解数学, 如何通俗理解泊松分布? CSDN博客,2019.04
【4】刘之帅,机器学习中的“分布” CSDN博客,2020.04
【5】我是8位的,概率统计14——几何分布 博客园 ,2020.01
【6】sam-X,正态和伽马分布族 CSDN博客,2018.09
【7】娜娜酱,生存法则—正态分布和幂律分布 知乎,2018.07


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











