









0、前言
来吧,HTTP又来了,讲真,我一直以为我作为一个前端程序媛,只要学好HTML CSS JavaScript就好了,我真的这么以为的,真的!可是面试的时候,听了面试官的话,我觉着,我真的是 图样图森破,眼界太浅!
要想做一个优秀的前端开发工程师,要懂得远远远远远远不止这些呀,HTTP原理,后台编程语言,服务器,UI设计等等等等等等等都需要学习,知识面要广,对于一些新的库也要去深入的学习。听君一席话,胜读十年书啊。不然我还真的就只是悠哉悠哉的学着我自己认为的前端,开心的不可自拔……
对于HTTP缓存,我之前还真的了解的不是很多,(这么说都是抬举自己),这两天深入的学习了,发现,我以前知道的那都叫啥?记得之前的博客里,我总结过,在浏览器地址栏输入一个网址,会发生什么,对的,我总结过的。所以面试的时候,我真的被问到了这个问题,所以我就开始说啊,但是,当面试官深入的一问我,我真的就懵逼了。。。。。其实心情还是很沮丧,但是还是振作的学习了 HTTP缓存机制。
好,正文开始
1、请求过程
先贴一个图,是在吴秦老师的博客中看到的
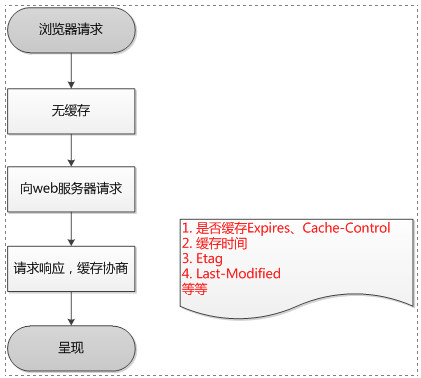
浏览器第一次请求:
再次请求
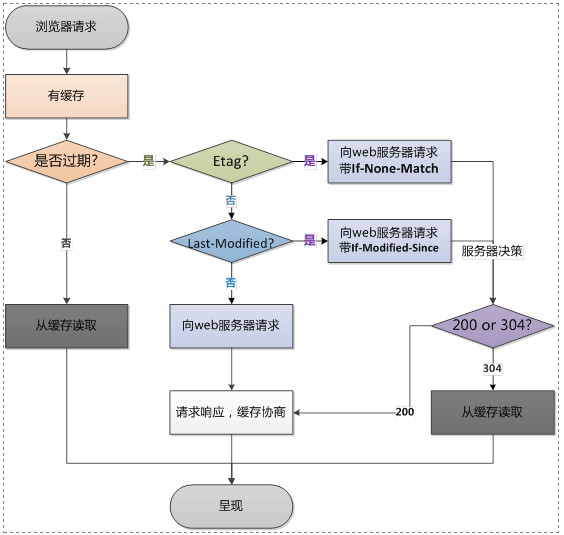
这样先看这两个图,心里是会感觉清楚了很多吧。
第一次请求,没有缓存,向服务器发送请求,然后返回200的响应头部和文件。而且还会进行缓存协商,把一些缓存相关的头部信息返回给浏览器
下面重点来介绍再次请求,有缓存的时候。
2、HTTP报文中与缓存相关的首部字段
1、通用头
cache-control:控制缓存的行为 pragma:值为no-cache时禁用缓存,http1.0的
2、请求头
if-match:比较ETag是否一致 if-none-match:比较ETag是否不一致
if-modified-since:比较资源最后修改时间是否一致 if-unmodified-since:比较资源最后修改时间是否不一致
3、响应头
ETag:资源的匹配信息
4、实体头
Expires:实体主体过期的时间
Last-Modified:资源的最后一次修改时间
下面具体介绍:
1、Pragma
当该字段值为“no-cache”的时候,会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。Pragma属于通用首部字段,在客户端上使用时,常规要求我们往html上加上这段meta元标签(而且可能还得做些hack放到body后面去):
<meta http-equiv="Pragma" content="no-cache">但是这行代码的用处很有限,因为只有IE识别。
2、Expires
有了Pragma来禁用缓存,自然也需要有个东西来启用缓存和定义缓存时间,对http1.0而言,Expires就是做这件事的首部字段。
Expires的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2002 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
但是,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了。
3、catch-control
这是一个比较重要的头部,当报文中同时出现了Pragma、Expires、Cache-control的时候,以cache-control为主。
http1.1新增了 Cache-Control 来定义缓存过期时间,Cache-Control是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。
在请求头中使用时,其值(表的出处)可能为:
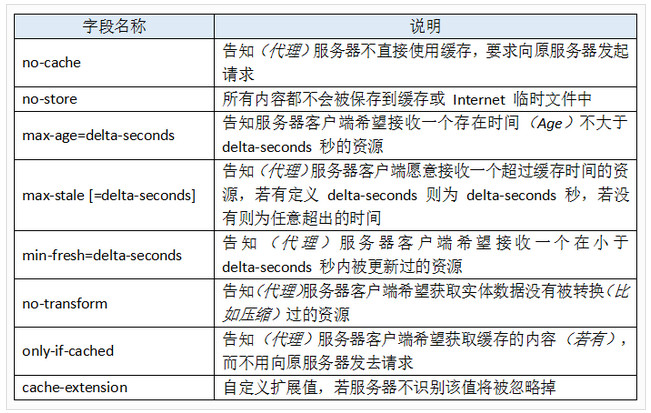
在响应头部使用时,其值可能为:
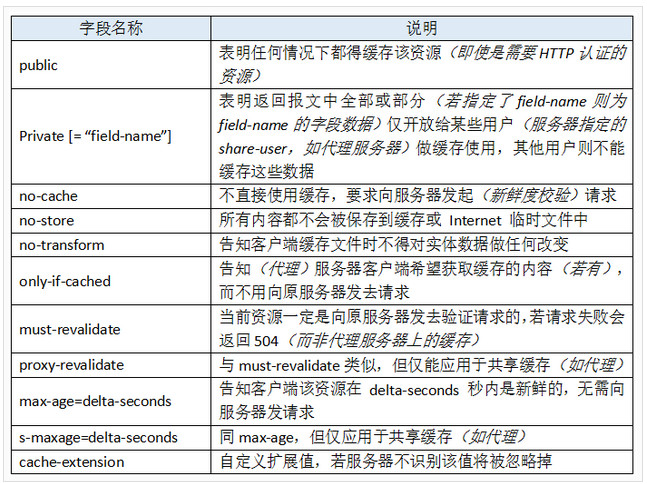
个人觉着最重要的是:no-cache/ no-state / max-age/ min-fresh
public/private/max-age
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
现在有这样一种情况,浏览器上缓存的内容过期了,而服务器端该资源并没有进行过更改,如果这时候浏览器向服务器重新发送请求,服务器把资源重新发送给浏览器一遍,如果文件内容很大,那么就会很浪费带宽和资源。所以,http又加了几种头部:
4、LastModified
服务器将资源传递给客户端时,会将资源最后更改时间以Last-Modified的形式加在实体头部返回给客户端。客户端会为该资源标记上该信息。等下次请求的时候,客户端会把该信息以If-modified-since附带在请求报文中,一并发送给服务器。若时间同服务器上的一致,说明资源没有被改动过,返回304,直接请求缓存即可,如果不一致,则资源改动了,那么就返回200,把新资源也返回给客户端
5、ETag
服务器会通过某算法,给资源计算得出一个唯一的标识符,在实体头部加上ETag返回给客户端。客户端会保留ETag字段。下次请求时,用在if-no-match中放上ETag的值,发送给服务器,若客户端的if-no-match值和服务器端的ETag值一致,则返回304,客户端可直接访问缓存;如果不一致,则返回200,并将新资源一起返回给客户端。
这就是200和304是怎么来的,我感觉,我已经能够明白了,不知道看了文章的朋友们能不能明白,下面附上我的参考文章:
1、浅谈浏览器HTTP的缓存机制
2、浏览器缓存机制
3、浏览器缓存机制浅析















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









