







 本文详细解读了word2vec的源码实现,重点介绍了训练模型中的词汇表(vocab)、哈弗曼树的构建、神经网络的训练过程,包括CBOW模型、负采样、词向量的更新等关键步骤。同时,文中还提到了参数调整如窗口大小、学习率等对模型的影响。
本文详细解读了word2vec的源码实现,重点介绍了训练模型中的词汇表(vocab)、哈弗曼树的构建、神经网络的训练过程,包括CBOW模型、负采样、词向量的更新等关键步骤。同时,文中还提到了参数调整如窗口大小、学习率等对模型的影响。
word2vec主要的层次结构

vocab是一个结构体数组。
*Vocab_hash是一个hash链表。
vocab存入词的时候实际是按照先后顺序存储的。为了方便查找,在词存入的时候顺便把词在链表中的位置存入到vocab_hash中,而该词的vocab_hash位置有hash(word)决定,这样查找起来很快。
ReadWord:逐个字符读入词(一个汉字是不是拆成两个字符读入呢?)
GetWordHash: hash = hash*257+word[i];
SearchVocab: 在vocab中查找对应的词,返回-1是没有找到,否则返回vocab_hash[hash]。
ReadWordIndex: 返回词在vocab中的位置。
AddWordToVocab:向vocab中插入新词,并在vocab_hash中插入新词的位置。
SortVocab:把vocab中的所有词整理了一遍,出现次数少于最低次数的丢掉,并重新分配了空间。
ReduceVocab:也是重新整理,将出现次数少的词干掉,只是并不重新分配空间,只是将次数不达标的词对应的vocab空间free掉。每被执行一次,min_reduce自增一次。(此函数是为保证vocab最大容量为21M而做的,如果trainfile里的词量太大,只有保留频次高的词。)
LearnVocabFromTrainFile:

SaveVocab:将vocab中的word和cn写入到输出文件中。
TrainModel:
其实网络的实现都是在TrainModelThread中,神经网络分成多线程计算,计算完成之后再进行k-mean聚类。TrainModel生成线程,配置线程。

InitNet:给第一层syn0、syn1、syn1neg分配空间。并给syn0赋初始值。并生成二叉树。
CreateBinaryTree:生成一棵节点数为2*vocab_size+1个节点的huffman树,并根据词频给给每个词设定其在huffman树的位置。
TrainModelThread:实现神经网络。(下一节细看这块。)
1. TrainModelTread的流程图
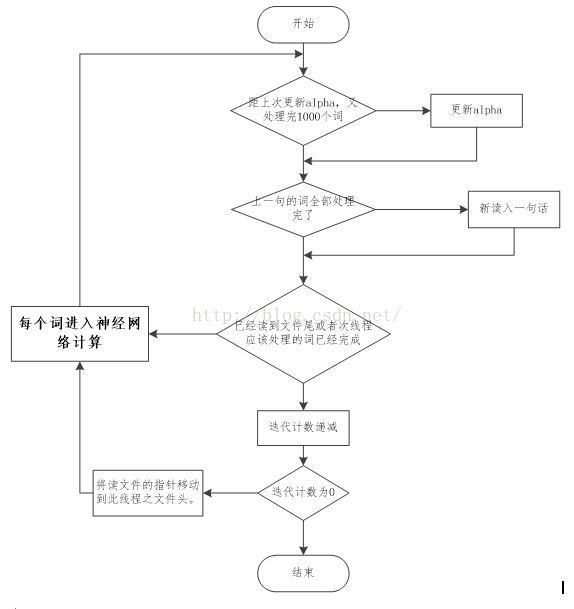
总的来说是这样的:
(1).所有训练集中的词被等分成n份(n为线程数),所有的词都会迭代5次(5次是默认值,这个可以在参数中设置),因此,每个线程会反复读5次自己管辖内的词。
(2).每次按照句子来读入词,一次读入一句,一句读入后,逐个词进入神经网络训练。等这句话的所有词都训练完成后,再读入下一句。
(3).当读到线程管辖文件尾时,迭代计数器自减,如果减为0了,则跳出最外层循环,整个训练结束;如果还没有减到0,则将读文件的指针移到线程管辖文件的头部。重新开始下一次迭代。
(4).每处理10000个词,就需要更新1次alpha。
(5). 逐个词进入神经网络训练,虽然设置了window,但是,并不是5个词进行一次神经网络训练,而是在in->hidden做向量累加时,随机计算窗口量,窗口数量有window这么多种(3-11个之间),以当前输入词为中心,累加其前后的词的向量。
(窗口大小随机,但有范围,以当前词为中心,(除最开始,和最末尾))。
2. 神经网络对应程序推导
以下推导是根据神经网络中主要的算式为主线,红色为其后备推导过程,以此来分析整个神经网络。
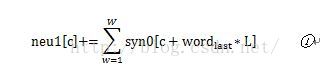
这里,首先,在intiNet()定义syn0是一个V*L维度的大矩阵,L为每个词的向量维度。它存的是vocab中所有词的L维的向量,已经给此矩阵负了随机初始值。Word是词在vocab中的位置。
在上一节提到,在做in->hidden的累加时,词窗口大小是随机的。这里neu1[c]就是窗口中词的向量累加。(c为维度计数,L范围内循环,W为窗口词个数)。
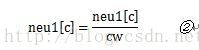
cw是窗口中词的数量,这里相当于是把做成平均值。
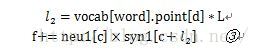
其中piont为词在huffman树中到根结点的路径,point[d]是其往上推的第d个父结点。这个内积和为其自身向量与各父结点的内积和,取这样一个内积和的好处目前还没有搞清楚。
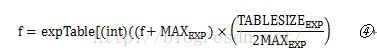
这是求f的sigmoid函数输出。这里没有直接计算,而是换成了查表的方式,应该是为了加快速度。但是查表就意味着把这个函数离散化了,就会存在离散误差。这里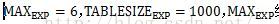
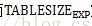
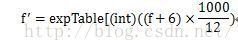
这个公式怎么就是sigmoid函数了呢?
首先来看看,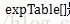
也就是
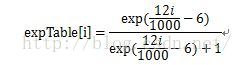
再来看看sigmoid函数的定义
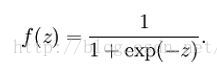
其取值范围为(0,1)。可转化为
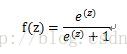
那么
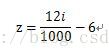
i的范围(0,1000),z的范围为(-6,6),离散化后步长为12/1000。
那么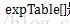
接下来令P=(f+6)*1000/12,f取值范围(-6,6),P的取值范围正好是(0,1000),覆盖表中所有的元素。
因此,④就是sigmoid函数的离散化形式。

code是父结点的标签,1为右结点,0为左结点。d依然是往上推的第d个父结点。这是梯度计算公式。由于0<f<1,>0,这样的话,父结点为左结点对应的梯度为正,为右结点的梯度为负。
更新向量。Neu1e[],每个词的向量误差为各父结点各次迭代向量乘梯度的和。然后把父结点的向量叠加到该词当前向量值中,实际上,向量误差就是自己前面d次迭代出来的向量参数乘梯度。
把误差叠加到每个词的向量当中。这个误差实际上是各父结点的向量乘梯度,包含了该父结点所有叶子结点的向量,因此,不但同一个父结点下来的两个子结点有关联了,连与叶子结点出现在同一个句子,且位置相近的词也关联起来了。
第三部分、word2vec之TrainModelThread程序详细注解
- <pre name="code" class="cpp">void *TrainModelThread(void *id) {
- long long a, b, d, cw, word, last_word, sentence_length = 0, sentence_position = 0;
- long long word_count = 0, last_word_count = 0, sen[MAX_SENTENCE_LENGTH + 1];
- long long l1, l2, c, target, label, local_iter = iter;
- unsigned long long next_random = (long long)id;
- real f, g;
- clock_t now;
- real *neu1 = (real *)calloc(layer1_size, sizeof(real)); //只有输入层需要,隐含层是一个累加和,输出层存入huffman树中。
- real *neu1e = (real *)calloc(layer1_size, sizeof(real));
- FILE *fi = fopen(train_file, "rb");
- fseek(fi, file_size / (long long)num_threads * (long long)id, SEEK_SET);
- while (1) {
- /************每10000个词左右重新计算一次alpha.**********************/
- if (word_count - last_word_count > 10000) {
- word_count_actual += word_count - last_word_count;
- last_word_count = word_count;
- if ((debug_mode > 1)) {
- now=clock();
- printf("%cAlpha: %f Progress: %.2f%% Words/thread/sec: %.2fk ", 13, alpha,
- word_count_actual / (real)(iter * train_words + 1) * 100,
- word_count_actual / ((real)(now - start + 1) / (real)CLOCKS_PER_SEC * 1000));
- fflush(stdout);
- }
- alpha = starting_alpha * (1 - word_count_actual / (real)(iter * train_words + 1));
- if (alpha < starting_alpha * 0.0001) alpha = starting_alpha * 0.0001;
- }
- /**********************读入一个句子,或者文章长于1000,则分成两句***************************************/
- //将句子中每个词的vocab位置存入到sen[]
- //每次读入一句,但读一句后等待这句话处理完之后再读下一句。
- if (sentence_length == 0) { //只有在一句执行完之后,,才会取下一句
- while (1) {
- word = ReadWordIndex(fi); //读fi中的词,返回其在vocab中的位置。
- if (feof(fi)) break;
- if (word == -1) continue;
- word_count++;
- if (word == 0) break; // 第0个词存的是句子结束符</s>,因此,这里一次性送入sen的就是一个句子或一篇文章。
- // The subsampling randomly discards frequent words while keeping the ranking same
- if (sample > 0) {
- //
- real ran = (sqrt(vocab[word].cn / (sample * train_words)) + 1) * (sample * train_words) / vocab[word].cn;
- next_random = next_random * (unsigned long long)25214903917 + 11;
- if (ran < (next_random & 0xFFFF) / (real)65536) continue; //(next_random & 0xFFFF) / (real)65536 应该是个小于1的值。也就是说ran 应该大于1.
- }
- sen[sentence_length] = word; //sen存的是词在vocab中的位置。
- sentence_length++;
- if (sentence_length >= MAX_SENTENCE_LENGTH) break; //文章超过1000个词则分成两个句子。
- }
- sentence_position = 0;
- }
- /**************************************************处理到文件尾的话,迭代数递减,***********************************/
- //所有的词(这里单个线程处理其对应的词)会被执行local_iter次。这5次神经网络的参数不是重复的,而是持续更新的,像alpha、syn0。
- //单个线程处理的词是一样的,这个后续可以看看有没可优化的地方。
- if (feof(fi) || (word_count > train_words / num_threads)) { //train_file被读到末尾了,或者一个线程已经完成了它的份额。
- word_count_actual += word_count - last_word_count;
- local_iter--; //读完所有词之后进行5次迭代是个啥意思? 也就是这些词不是过一次这个网络就行了,而是5词。
- if (local_iter == 0) break; //只有这里才是跳出最外层循环的地方。
- word_count = 0;
- last_word_count = 0;
- sentence_length = 0;
- //移动文件流读写位置,从距文件开头file_size / (long long)num_threads * (long long)id 位移量为新的读写位置
- fseek(fi, file_size / (long long)num_threads * (long long)id, SEEK_SET); //将文件读指针重新移到到此线程所处理词的开头。
- continue;
- }
- /*******************************进入神经网络******************************/
- word = sen[sentence_position]; //从句首开始,虽然window=5,或别的,但是,以
- if (word == -1) continue;
- for (c = 0; c < layer1_size; c++) neu1[c] = 0;
- for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
- next_random = next_random * (unsigned long long)25214903917 + 11;
- //这个点没有固定下来,导致窗口也是随机的,可以看看这点是否可以优化。
- b = next_random % window; //b取0-4之间的随机值。
- if (cbow) { //train the cbow architecture
- // in -> hidden
- cw = 0;
- //窗口大小随机,但有范围(3-11,窗口大小为单数,一共5种,因此,window实际可以理解为窗口变化的种数),以当前词为中心,(除最开始,和最末尾)
- for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
- c = sentence_position - window + a; //给c赋值
- if (c < 0) continue;
- if (c >= sentence_length) continue;
- last_word = sen[c];
- if (last_word == -1) continue;
- //累加词对应的向量。双重循环下来就是窗口额定数量的词每一维对应的向量累加。
- //累加后neu1的维度依然是layer1_size。
- //从输入层过度到隐含层。
- for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size];
- cw++; //进入隐含层的词个数。
- }
- if (cw) {
- for (c = 0; c < layer1_size; c++) neu1[c] /= cw; //归一化处理。
- //遍历该叶子节点对应的路径,也就是每个父结点循环一次,这是什么原理呢?
- //这样一来,越是词频低的词,迭代层数越多,
- //每个词都要从叶子结点向根结点推一遍。
- //这样的话可以通过父结点,建立叶子结点之间的联系。
- if (hs) for (d = 0; d < vocab[word].codelen; d++) {
- f = 0;
- l2 = vocab[word].point[d] * layer1_size;
- // Propagate hidden -> output
- for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2]; //做内积 这个内积是什么原理呢?
- if (f <= -MAX_EXP) continue; //不在范围内的内积丢掉
- else if (f >= MAX_EXP) continue; //-6<f<6
- else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; //sigmod函数, f=expTab[(int)((f+6)*1000/12)]
- // 'g' is the gradient multiplied by the learning rate
- g = (1 - vocab[word].code[d] - f) * alpha; //计算梯度
- // Propagate errors output -> hidden
- for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2]; //计算向量误差,实际就是各父结点的向量和乘梯度。
- // Learn weights hidden -> output
- for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c]; //更新父结点们的向量值,父结点的向量就是各叶子结点各次向量的累加。
- //关系就是这样建立起来的,各叶子结点的向量都累加进入了每一个父结点中,因此,拥有相同父结点的词就会联系起来了。
- }
- // NEGATIVE SAMPLING
- if (negative > 0) for (d = 0; d < negative + 1; d++) { //有负样本,处理负样本
- if (d == 0) {
- target = word;
- label = 1; //正样本
- } else {
- next_random = next_random * (unsigned long long)25214903917 + 11;
- target = table[(next_random >> 16) % table_size];
- if (target == 0) target = next_random % (vocab_size - 1) + 1;
- if (target == word) continue;
- label = 0; //负样本
- }
- l2 = target * layer1_size;
- f = 0; //以下和上面差不多。
- for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2];
- if (f > MAX_EXP) g = (label - 1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2832
2832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









