







简介
深度学习图像分类常需要将数据集分为训练集(train)、验证集(validation)和测试集(test),而 TensorFlow 没有提供相关函数(准确来说是很难用),使用 split-folders 可轻松实现。
功能:
将文件划分为训练集和验证集(或加上测试集)
适用于不同文件类型
打乱文件顺序
种子 seed 让划分可复现
对不平衡数据集进行随机过采样
可选组文件的前缀
适用任何操作系统
Split Train data into Training and Validation when using ImageDataGenerator in Keras
安装
pip install split-folders
初试
下载数据集 flower_photos.tgz 并解压

数据集是不平衡的,即每个类的样本数不同(广义来说是平衡的,比例偏差不大)
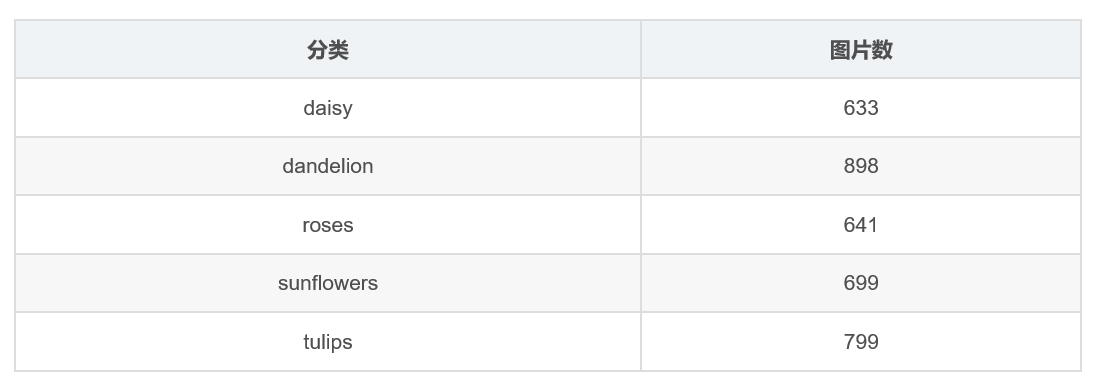
代码
import splitfolders
# train:validation:test=8:1:1
splitfolders.ratio(input='flower_photos', output='output', seed=1337, ratio=(0.8, 0.1, 0.1))效果

可以看到测试集和验证集数量大致相同,文档表示不平衡的数据集应该用 splitfolders.fixed()
用法

函数功能适用情况splitfolders.ratio('input_folder', output='output', seed=1337, ratio=(0.8, 0.1, 0.1), group_prefix=None)按比例划分训练集、验证集、测试集,默认情况关闭过采样,过采样只适用于训练集,因为验证集和测试集中有重复是作弊平衡数据集splitfolders.fixed('input_folder', output='output', seed=1337, fixed=(100, 100), oversample=False, group_prefix=None)给验证集、测试集固定数量图片,其余均划分到训练集不平衡数据集
只划分训练和验证集的话,ratio 改为 (0.8, 0.2)
命令行
Usage:
splitfolders [--output] [--ratio] [--fixed] [--seed] [--oversample] [--group_prefix] folder_with_images
Options:
--output path to the output folder. defaults to `output`. Get created if non-existent.
--ratio the ratio to split. e.g. for train/val/test `.8 .1 .1 --` or for train/val `.8 .2 --`.
--fixed set the absolute number of items per validation/test set. The remaining items constitute
the training set. e.g. for train/val/test `100 100` or for train/val `100`.
--seed set seed value for shuffling the items. defaults to 1337.
--oversample enable oversampling of imbalanced datasets, works only with --fixed.
--group_prefix split files into equally-sized groups based on their prefix
Example:
splitfolders --ratio .8 .1 .1 -- folder_with_images
如:
splitfolders --output output --ratio 0.8 0.1 0.1 -- flower_photos参考文献















 4448
4448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









